I tried some stuff, but I got this:
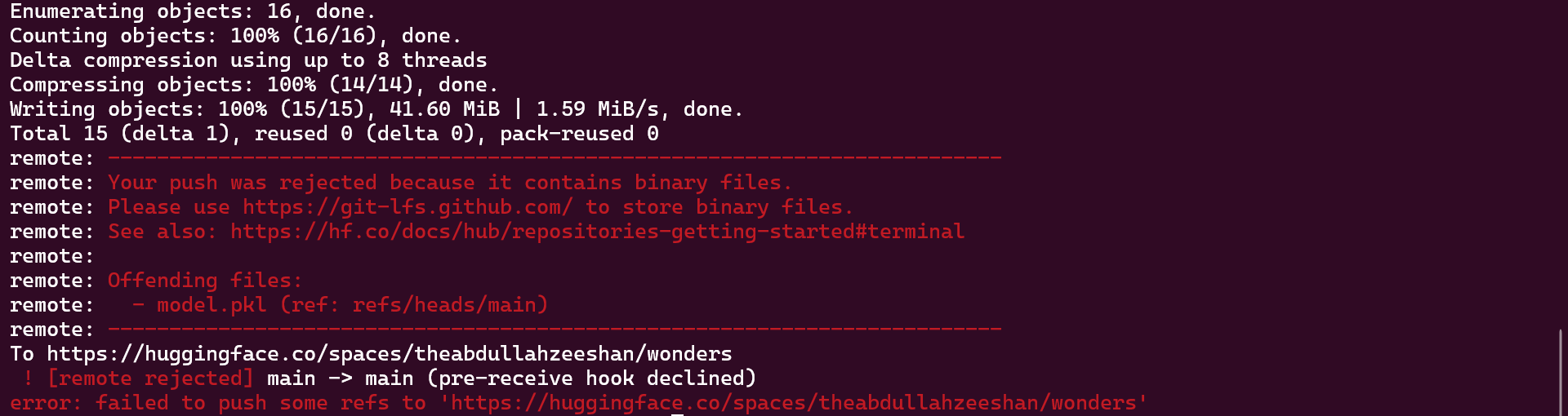
What is your best recommendation for deploying a mobile app?
It needs the git-lfs extension installed for large binary files. GitHub - git-lfs/git-lfs: Git extension for versioning large files
The other option is to manually upload any missed files to the huggingface space via the web interface.
- Navigate to the space,
- click on the files tab/view
- select ‘add file’
2 Likes
That second chapter is tough. I corrected the downloader of the images. But with
dls.valid.show_batch(max_n=4, nrows=1)
I get
UnidentifiedImageError: cannot identify image file ‘/kaggle/working/bears/grizzly/b0572ccc-1c3a-490a-8c9e-a5bff43918d1.jpg’
Anyone got any hint?
1 Like
You may need to delete that file as it is corrupted or something like that. If you’re using the Kaggle site I think you can open up the console at the bottom of the page and you may be able to use the rm command to remove that file. I don’t think it’s possible to delete files via the Kaggle UI in the right hand tab under “Data” so the console is all I can personally think of at the moment.
The console is this icon at the bottom of the Kaggle web page.

And the rm command in your case might be (you may need to alter the path I’m not 100%):
rm /kaggle/working/bears/grizzly/b0572ccc-1c3a-490a-8c9e-a5bff43918d1.jpg
And then try show_batch again?
I tried… but then there is an issue with another file. Mmaybe something with kaggle? Can’t even download properly. Even hat to manipulate url’s manually because the (if I remember correctily) the ? in the url’s didn’t work.
I now installed jupyter notebook locally. Hope this will work.
Hopefully running things locally works for you.
Where exactly is the model used for fine tuning in these lines of code:
learn = vision_learner(dls, resnet18, metrics=error_rate)
learn.fine_tune(3)
I assume it is the vision_learner from these docs:
However, I was anticipating a pkl file. How would we load our own model to fine tune?
Having trouble deploying the java script website, what could be wrong with the code:
---
title: 1. Single file
layout: page
---
<input id="photo" type="file">
<div id="results"></div>
<script>
async function loaded(reader) {
const response = await fetch('https://hiddenmiddle-fastai-lesson2.hf.space/predict', {
method: "POST", body: JSON.stringify({ "data": [reader.result] }),
headers: { "Content-Type": "application/json" }
});
const json = await response.json();
const label = json['data'][0]['confidences'][0]['label'];
results.innerHTML = `<br/><img src="${reader.result}" width="300"> <p>${label}</p>`
}
function read() {
const reader = new FileReader();
reader.addEventListener('load', () => loaded(reader))
reader.readAsDataURL(photo.files[0]);
}
photo.addEventListener('input', read);
</script>
It just takes in a picture, but doesn’t actually do anything
I also noticed same behavior at Single file | Jeremy Howard - it just takes in a picture, but doesn’t classify
Unfortunately I’m no longer familiar with the topic. When I wrote my post, it was best to convert the PyTorch model to ONNX and then to Apple’s CoreML format. However, it now looks like CoreML has the tooling to do a direct conversion from PyTorch. There should be sample code templates to use on Apple’s website for the app itself.
I’m not quite sure what you’re asking in relation to “where exactly is the model…”, but FWIW programmatically you can get access to it via learn.model (from Lesson 3: Practical Deep Learning for Coders 2022 - YouTube). But if you mean were is it physically then I think ResNets are built into the fastai library which is why the don’t need to be imported or installed separately to use (unlike LeViTs for example that need timm). So there isn’t a physical *.pth or *.pkl for ResNets AFAIK.
I haven’t used it but maybe Leaner.load_model() is what you need? Or if it’s a fastai vision learner you’ve already trained and exported to a pkl file you can use Learner.load().
Hello,
Is your blog post still relevant in April 2023 ? It looks like Gradio removed their awesome REST API ![]()
I recently deployed on HuggingFaces my first machine learning app with FastAI and Gradio (very exciting! many thanks for the course content!). You can find the app live on Training - a Hugging Face Space by ivanho92. However, I have trouble consuming the API that should have been automatically generated when this app was built.
I have tried several different requests through Postman, but I keep getting a “404 Not Found” error. I’ve followed the instructions in the documentation and have double-checked the endpoint URL, but I still can’t get it to work.
Here’s an example of a postman request I have tried:
POST https://ivanho92-training.hf.space/predict
{
"data": [
"https://raw.githubusercontent.com/gradio-app/gradio/main/test/test_files/bus.png"
]
}
Do you have any idea how to proceeed?
Many thanks!
Ivan
Is the app.ipynb shown here available in the repository? I don’t see it linked to here or in the fastai github repo, but maybe I missed it somewhere?
Try
02-saving-a-basic-fastai-model.ipynb in the course repo includes cats vs dogs.
There is also a Cats vs Dogs example in the docs. fastai - Computer vision intro
Thanks, but not quite what I was looking for. That’s the notebook that trains the model (and creates a .pkl file), but I’m looking for the notebook he uses that loads the .pkl file and uses Gradio to create an interface to generate predictions using the previously trained model.

Hello fastai community!
I am following along Lesson 2 of the Book and I want to use fastai to train my first model that will classify an ECG beat (data is explained below) into one of 4 classes.
I have seen in chapter 1 of the Book that at the time it was made, it was not well understood how to use transfer learning on time-series. The following questions arose:
- Is there now a pretrained fastai model that can be used for this kind of classification?
- What are the challenges of using transfer learning on time-series?
- Is there a known way to represent this kind of data (ECG) other than time series?
- How would You suggest to go about this problem?
My dataset is a .csv file containing a 87000 rows. Each row represent an ECG beat sampled at 125 Hz containing 187 samples.
Dataset can be found on Kaggle at the following link:
Kind regards from Serbia,
Mijat Paunović
Is it still possible to create an HTML file that uses the API from hugging faces spaces as shown in the lesson? Or do you have to pay for endpoints now?
Hi I am getting error :
AttributeError: ‘Sequential’ object has no attribute ‘fine_tune’
import torch
from fastai.vision.all import *
# Check if GPU is available
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print('Using device:', device)
# Load data and move to GPU
path = untar_data(URLs.PETS)
dls = ImageDataLoaders.from_name_re(
path, fnames=get_image_files(path/'images'), pat=r'^(.*)_\d+.jpg$', item_tfms=Resize(224),
batch_tfms=aug_transforms(), bs=64
)
dls = dls.to(device)
# Define model and move to GPU
learn = cnn_learner(dls, resnet34, metrics=error_rate).to(device)
# Train model on GPU
learn.fine_tune(3)
Please help.
I haven’t seen the .to(device) used in any of the examples I was following. is it needed?