Hey folks, I want to know what the difference is between this:
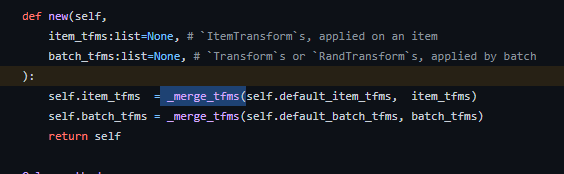
faces = DataBlock(
blocks=(ImageBlock, CategoryBlock), # we are dealing with categorical classification
get_items=get_image_files, # function to fetch images from our dataset
splitter=RandomSplitter(valid_pct=0.2, seed=42), # spliting our dataset
get_y=parent_label, # class of category
item_tfms=[Resize(192, method='squish')] # more like BoxFit.contain, from Flutter
)
dls = faces.dataloaders(path, bs=32).show_batch(max_n=9)
Specifically, the new keyword in the “faces” data block?
We created a datablock initially without the new keyword and now because we want to change the image appearance we ignored the other properties of the datablock and only passed the item_tfms params? Why is this so? Does the new “faces datablock” retain the properties of the first created datablock?
I have two different folders ( annotations and images) which contain 120 images in the images folder and the corresponding 120 annotations in an annotations folder. The format of the annotation is in “json”. I want to create a datablock so as to perform classification analysis. Please, how can I map my JSON files to the images so as to run the classification analysis?
Yes, there are many ways to do this. The details depends a bit on exactly how the data is structured, e.g. how the images are mapped to the entries in the json file.
If you are familiar with using pandas and especially referencing data in pandas dataframes as part of the datablocks API, you could read in your json files, combine them, put them into a single pandas dataframes and use that.
This looks more like object detection data, whereas in your question you mention “classification”.
Classification is finding the correct label for an image such as “cat”, “dog” or “horse”. Object detection is about finding things in images, classify them and also draw a bounding box around them.
Did you already have a look at this or this. Especially the second link is based on outdated code (course18), so not everything might work exactly as presented there, but it might be a good start and show you in general how to achieve this.
Hey @Akindele I believe the new keyword is reassigning a new image transformation to the set of images you’re preprocessing. I have yet to test this with my own data but if you look at the new method and the _merge_tfms method in fastAI’s Github repo it looks like it’s passing the values you pass into the new method back int othe item_tfms parameter.
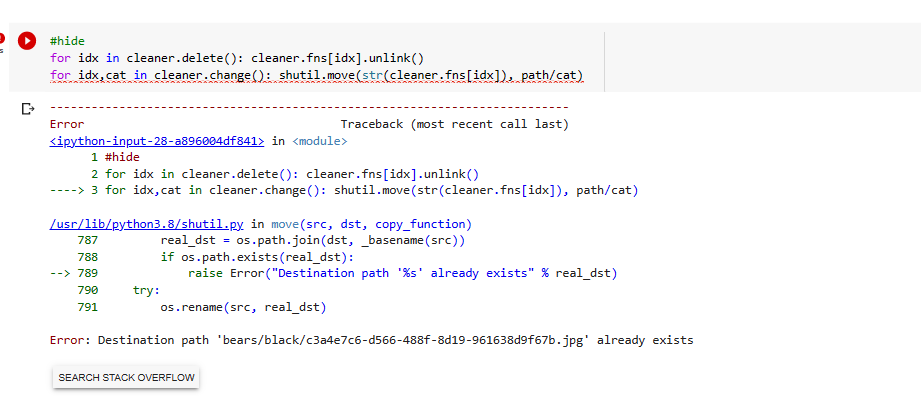
I tried to run the delete and change cell, for just one selection of black bear from the train set, as you told to… if I am not wrong.
However I am not sure… why do I get this error.
Is there any way to solve it…
If anyone else has solved the problem, kindly let me know.
Thanks in advance.
The error says that there is already an image with that file name. You are moving images from one folder to another with the cleaner (Change image category.). If you already ran this cell or notebook before the images you changed category earlier are still in that new folder.
Thank you for the reply, I think I got it where I was mistaken.
I was actually changing the labels for the images, which were already correct. I think that is why I got the error that the file exists already.
So, with image cleaner, I believe we only need to change those files which seem to be incorrect with the label or needs to be deleted. Rest <> label can stay.
N Once we are done cleaning the data I think we need to re-run the data loaders and train the model.
Also, I believe we need to run the cells after each pair of category and train/valid set.
for idx in cleaner.delete(): cleaner.fns[idx].unlink()
for idx,cat in cleaner.change():shutil.move(str(cleaner.fns[idx]), path/cat)
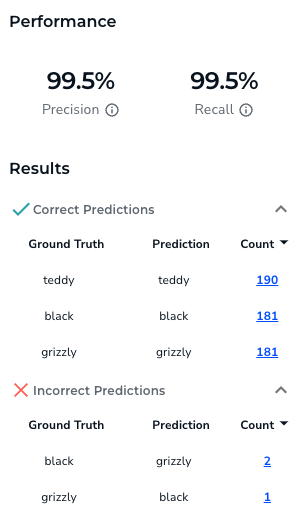
A bit off topic, but maybe some will find this interesting: I made an account on landing.ai and uploaded the bear images to see how their training went. The results are equal (although their training took way longer):
They have built a very nice interface on top of their tools, making it even more accessible for non-techies.
Might be a cool project to turn fast.ai as well into a SaaS. I know quite a bit about building a SaaS platform, but I’m just a newbie in AI (it’s lesson two after all ). If anyone is interested to explore this, please let me know.
Why is all the output in the book has two outputs? first output is always epoch0, and the second output depends on how many epochs you trained, if you train 1, the second output will just be one line about epoch0. if you train 5, the second output will be five lines from epoch0 to epock4. I’m really confused, isn’t there supposed to be just one output?