Number 4 was a great tip. Thanks @DanielLam!
Hi Grace,
Just looking through the forum now and noticed this. You’d do it just the same way you would from your own machine, by setting upstream to your github repo. If it’s still an issue I can go into more detail.
Best,
David
Thanks for the response. Yes, I figured it out.
Any thoughts why below transformation statement threw ‘AxesImage’ object has no property ‘unique’ error?

Note - I am working on lesson 2 nb and haven’t yet seen lecture 3 videos but I have done git pull so code is latest
Hi Folks,
My app is running on binder. However, the model is stored in github lfs – which has some file size restrictions. In stead I was hoping to save the model (pkl) file to some remote bucket say S3 / Google Drive and load the model from there. I dont think load_learner works with urls – looks the first argument should be a file / path. I did a little bit of hunting and found torch.utils.model_zoo.load_url(model_url) to be a good alternative. However, this does download the file in the local fs and then loads the model. I am thinking if there is a way to just stream the bytes and create the model in memory. Typically, for all files I use the requests object and then wrap it in an io.BytesIO object. However, load_learner or torch.load() which it internally calls seems to have some problems with it. Seems like there are some issues with reading pickle files this way. I am doing the following:
response = requests.get(model_url)
buffer = io.BytesIO(response.content)
torch.load(buffer) # or use load_learner(buffer)
I am seeing this error UnpicklingError: invalid load key, '\xff'.
Any thoughts / pointers on how to load pickle objects as Bytes and then finally into torch.load?
Here’s my Pasta classifier for 20 different pasta types:
rotini, farfalle, macaroni, orzo, penne, spaghetti, rigatoni, gnocchi, ravioli, tagliatelle, tortellini, fusilli, vermicelli, fettuccine, linguine, orecchiette, manicotti, ziti, gemelli, lasagne
To my surprise, there is well over 200 different pasta varieties including regional differences. I didn’t play around with the widgets yet since I just wanted to get a basic web app working first.
Double check it is the latest version (also for fastcore). For me, updating fixed the error, which apparently was a known bug.
Thank you, Daniel. Your notes were quite helpful - was able to build the web application (despite Paperspace) referencing your notes.
Best,
Charles
Hi all,
Turns out, this process is rather decent at classifying types of baseball bats (metal, wood, or plastic).
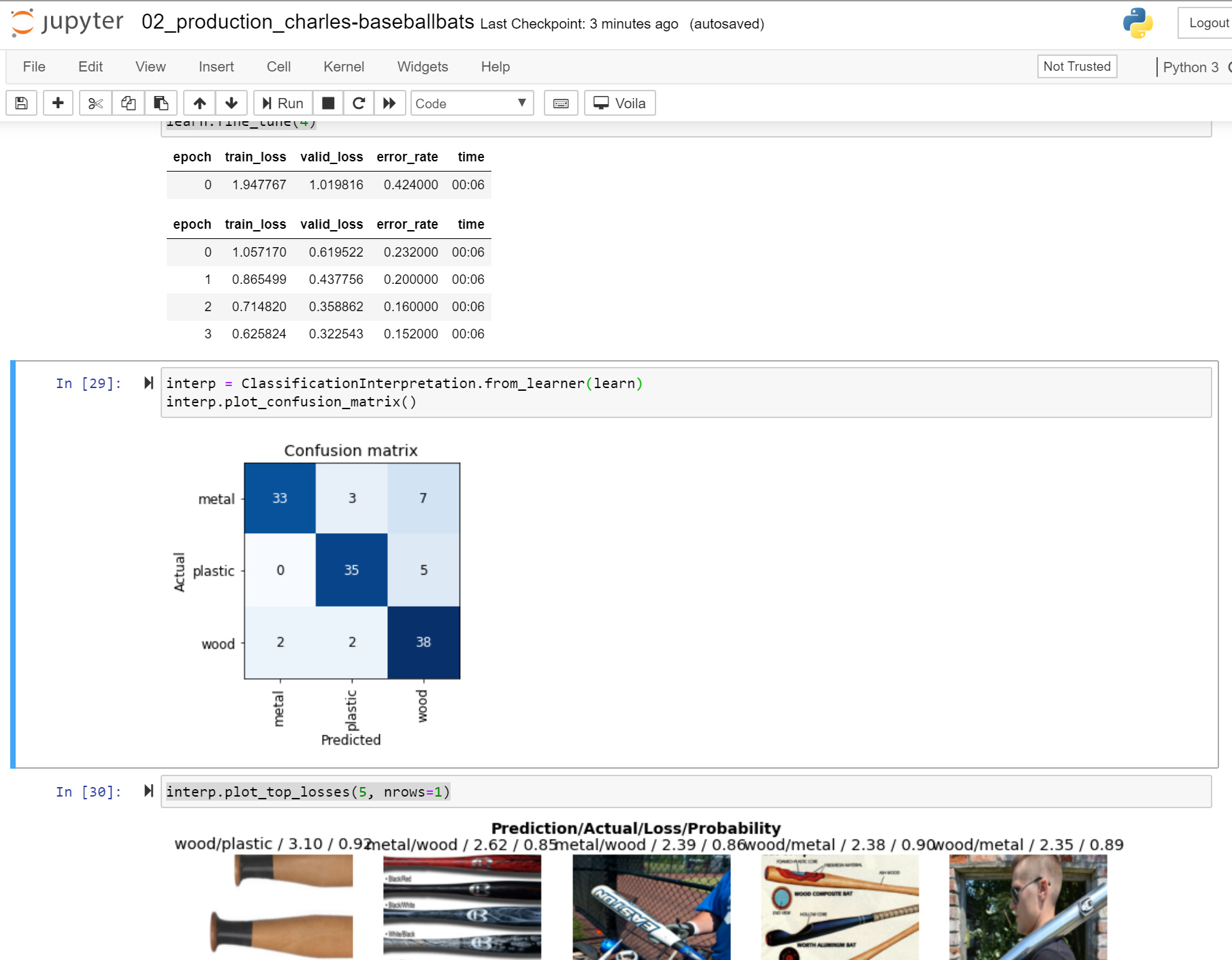
Best,
Charles
Do this and restart your kernel
!pip install git+https://github.com/fastai/fastai2
!pip install git+https://github.com/fastai/fastcore
Yes, the bug was solved in the latest version of Fastai2, so updating solves it.
Were you able to figure out how to run it in paperspace?
Can I use the Google search approach in a blog post?
I am facing this issue now. Have you got any idea how to fix this?
Hi,
I am a course-v3 student and have a few questions for lesson 2,
- Should we be running
pip install fastai --upgradein our notebooks? (Considering there’s a new version of fastai now that is incompatible with course-v3 fastai. - How can train and valid loss be > 1? Isn’t 1 == 100% loss? What does a loss greater than 100% mean?
- I noticed in the notebook
learn.export()andload_learner(...)is used; how is this different fromlearn.save(...)andlearn.load(...)?
Thank you.
Regards,
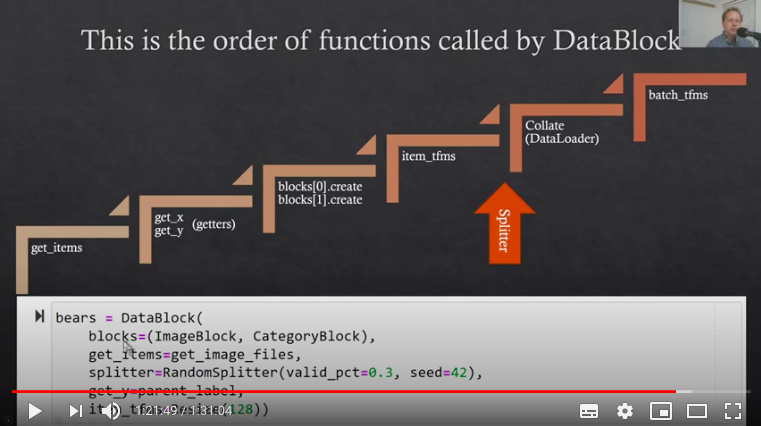
I am going through Chapter 2’s notebook, and remaking the example bear classifier. I get this error when running learn.fine_tune4():
RuntimeError: DataLoader worker (pid 19862) is killed by signal: Killed.
I am using Gradient. Any help will be appreciated! Thank you.
The full error message is:
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-12-672a4803901c> in <module>
1 learn = cnn_learner(dls, resnet18, metrics=error_rate)
----> 2 learn.fine_tune(4)
/opt/conda/envs/fastai/lib/python3.8/site-packages/fastcore/utils.py in _f(*args, **kwargs)
470 init_args.update(log)
471 setattr(inst, 'init_args', init_args)
--> 472 return inst if to_return else f(*args, **kwargs)
473 return _f
474
/opt/conda/envs/fastai/lib/python3.8/site-packages/fastai/callback/schedule.py in fine_tune(self, epochs, base_lr, freeze_epochs, lr_mult, pct_start, div, **kwargs)
159 "Fine tune with `freeze` for `freeze_epochs` then with `unfreeze` from `epochs` using discriminative LR"
160 self.freeze()
--> 161 self.fit_one_cycle(freeze_epochs, slice(base_lr), pct_start=0.99, **kwargs)
162 base_lr /= 2
163 self.unfreeze()
/opt/conda/envs/fastai/lib/python3.8/site-packages/fastcore/utils.py in _f(*args, **kwargs)
470 init_args.update(log)
471 setattr(inst, 'init_args', init_args)
--> 472 return inst if to_return else f(*args, **kwargs)
473 return _f
474
/opt/conda/envs/fastai/lib/python3.8/site-packages/fastai/callback/schedule.py in fit_one_cycle(self, n_epoch, lr_max, div, div_final, pct_start, wd, moms, cbs, reset_opt)
111 scheds = {'lr': combined_cos(pct_start, lr_max/div, lr_max, lr_max/div_final),
112 'mom': combined_cos(pct_start, *(self.moms if moms is None else moms))}
--> 113 self.fit(n_epoch, cbs=ParamScheduler(scheds)+L(cbs), reset_opt=reset_opt, wd=wd)
114
115 # Cell
/opt/conda/envs/fastai/lib/python3.8/site-packages/fastcore/utils.py in _f(*args, **kwargs)
470 init_args.update(log)
471 setattr(inst, 'init_args', init_args)
--> 472 return inst if to_return else f(*args, **kwargs)
473 return _f
474
/opt/conda/envs/fastai/lib/python3.8/site-packages/fastai/learner.py in fit(self, n_epoch, lr, wd, cbs, reset_opt)
205 self.opt.set_hypers(lr=self.lr if lr is None else lr)
206 self.n_epoch,self.loss = n_epoch,tensor(0.)
--> 207 self._with_events(self._do_fit, 'fit', CancelFitException, self._end_cleanup)
208
209 def _end_cleanup(self): self.dl,self.xb,self.yb,self.pred,self.loss = None,(None,),(None,),None,None
/opt/conda/envs/fastai/lib/python3.8/site-packages/fastai/learner.py in _with_events(self, f, event_type, ex, final)
153
154 def _with_events(self, f, event_type, ex, final=noop):
--> 155 try: self(f'before_{event_type}') ;f()
156 except ex: self(f'after_cancel_{event_type}')
157 finally: self(f'after_{event_type}') ;final()
/opt/conda/envs/fastai/lib/python3.8/site-packages/fastai/learner.py in _do_fit(self)
195 for epoch in range(self.n_epoch):
196 self.epoch=epoch
--> 197 self._with_events(self._do_epoch, 'epoch', CancelEpochException)
198
199 @log_args(but='cbs')
/opt/conda/envs/fastai/lib/python3.8/site-packages/fastai/learner.py in _with_events(self, f, event_type, ex, final)
153
154 def _with_events(self, f, event_type, ex, final=noop):
--> 155 try: self(f'before_{event_type}') ;f()
156 except ex: self(f'after_cancel_{event_type}')
157 finally: self(f'after_{event_type}') ;final()
/opt/conda/envs/fastai/lib/python3.8/site-packages/fastai/learner.py in _do_epoch(self)
189
190 def _do_epoch(self):
--> 191 self._do_epoch_train()
192 self._do_epoch_validate()
193
/opt/conda/envs/fastai/lib/python3.8/site-packages/fastai/learner.py in _do_epoch_train(self)
181 def _do_epoch_train(self):
182 self.dl = self.dls.train
--> 183 self._with_events(self.all_batches, 'train', CancelTrainException)
184
185 def _do_epoch_validate(self, ds_idx=1, dl=None):
/opt/conda/envs/fastai/lib/python3.8/site-packages/fastai/learner.py in _with_events(self, f, event_type, ex, final)
153
154 def _with_events(self, f, event_type, ex, final=noop):
--> 155 try: self(f'before_{event_type}') ;f()
156 except ex: self(f'after_cancel_{event_type}')
157 finally: self(f'after_{event_type}') ;final()
/opt/conda/envs/fastai/lib/python3.8/site-packages/fastai/learner.py in all_batches(self)
159 def all_batches(self):
160 self.n_iter = len(self.dl)
--> 161 for o in enumerate(self.dl): self.one_batch(*o)
162
163 def _do_one_batch(self):
/opt/conda/envs/fastai/lib/python3.8/site-packages/fastai/learner.py in one_batch(self, i, b)
177 self.iter = i
178 self._split(b)
--> 179 self._with_events(self._do_one_batch, 'batch', CancelBatchException)
180
181 def _do_epoch_train(self):
/opt/conda/envs/fastai/lib/python3.8/site-packages/fastai/learner.py in _with_events(self, f, event_type, ex, final)
153
154 def _with_events(self, f, event_type, ex, final=noop):
--> 155 try: self(f'before_{event_type}') ;f()
156 except ex: self(f'after_cancel_{event_type}')
157 finally: self(f'after_{event_type}') ;final()
/opt/conda/envs/fastai/lib/python3.8/site-packages/fastai/learner.py in _do_one_batch(self)
162
163 def _do_one_batch(self):
--> 164 self.pred = self.model(*self.xb)
165 self('after_pred')
166 if len(self.yb): self.loss = self.loss_func(self.pred, *self.yb)
/opt/conda/envs/fastai/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
/opt/conda/envs/fastai/lib/python3.8/site-packages/torch/nn/modules/container.py in forward(self, input)
115 def forward(self, input):
116 for module in self:
--> 117 input = module(input)
118 return input
119
/opt/conda/envs/fastai/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
/opt/conda/envs/fastai/lib/python3.8/site-packages/torch/nn/modules/container.py in forward(self, input)
115 def forward(self, input):
116 for module in self:
--> 117 input = module(input)
118 return input
119
/opt/conda/envs/fastai/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
/opt/conda/envs/fastai/lib/python3.8/site-packages/torch/nn/modules/container.py in forward(self, input)
115 def forward(self, input):
116 for module in self:
--> 117 input = module(input)
118 return input
119
/opt/conda/envs/fastai/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
/opt/conda/envs/fastai/lib/python3.8/site-packages/torchvision/models/resnet.py in forward(self, x)
61 out = self.relu(out)
62
---> 63 out = self.conv2(out)
64 out = self.bn2(out)
65
/opt/conda/envs/fastai/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
/opt/conda/envs/fastai/lib/python3.8/site-packages/torch/nn/modules/conv.py in forward(self, input)
417
418 def forward(self, input: Tensor) -> Tensor:
--> 419 return self._conv_forward(input, self.weight)
420
421 class Conv3d(_ConvNd):
/opt/conda/envs/fastai/lib/python3.8/site-packages/torch/nn/modules/conv.py in _conv_forward(self, input, weight)
413 weight, self.bias, self.stride,
414 _pair(0), self.dilation, self.groups)
--> 415 return F.conv2d(input, weight, self.bias, self.stride,
416 self.padding, self.dilation, self.groups)
417
/opt/conda/envs/fastai/lib/python3.8/site-packages/torch/utils/data/_utils/signal_handling.py in handler(signum, frame)
64 # This following call uses `waitid` with WNOHANG from C side. Therefore,
65 # Python can still get and update the process status successfully.
---> 66 _error_if_any_worker_fails()
67 if previous_handler is not None:
68 previous_handler(signum, frame)
RuntimeError: DataLoader worker (pid 19862) is killed by signal: Killed.
Managed to get my first production model! Felt like it took far too long to get it all to work, but I got there in the end…
1 Like
For the first one, I would recomend use conda enviroments or another way to install fastai v2 that yes is not backward compatible in API, but some knowledge could be translated from one to the other, only things things changed from name and got another organization.
And yes, if you will not use the old one, you should do --upgrade.
This is typically a memory problem. How much RAM do you have? Try reducing the number of concurrent processes, it might help you.
1 Like