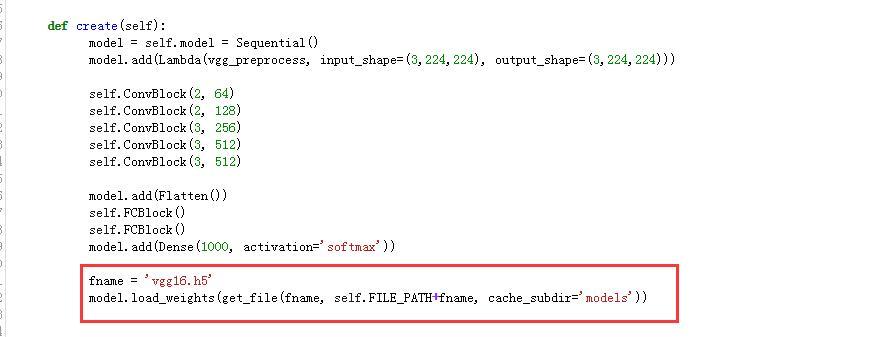
Ok, so I managed to avoid memory problems by using get_batches and generators instead of get_data and numpy arrays.
Or at least that’s what I thought, because I’ve encountered a problem at the end of the lesson which I’m not able to solve. When I try to fit the model here:
fit_model(model, batches, val_batches, nb_epoch=2)
I’m getting the following error:
Epoch 1/2
ValueError Traceback (most recent call last)
in ()
----> 1 fit_model(model, batches, val_batches, nb_epoch=2)
in fit_model(model, batches, val_batches, nb_epoch)
1 def fit_model(model, batches, val_batches, nb_epoch=1):
2 model.fit_generator(batches, samples_per_epoch=batches.n, nb_epoch=nb_epoch,
----> 3 validation_data=val_batches, nb_val_samples=val_batches.n)
/home/user/anaconda2/lib/python2.7/site-packages/keras/models.pyc in fit_generator(self, generator, samples_per_epoch, nb_epoch, verbose, callbacks, validation_data, nb_val_samples, class_weight, max_q_size, nb_worker, pickle_safe, initial_epoch, **kwargs)
933 nb_worker=nb_worker,
934 pickle_safe=pickle_safe,
–> 935 initial_epoch=initial_epoch)
936
937 def evaluate_generator(self, generator, val_samples,
/home/user/anaconda2/lib/python2.7/site-packages/keras/engine/training.pyc in fit_generator(self, generator, samples_per_epoch, nb_epoch, verbose, callbacks, validation_data, nb_val_samples, class_weight, max_q_size, nb_worker, pickle_safe, initial_epoch)
1555 outs = self.train_on_batch(x, y,
1556 sample_weight=sample_weight,
-> 1557 class_weight=class_weight)
1558
1559 if not isinstance(outs, list):
/home/user/anaconda2/lib/python2.7/site-packages/keras/engine/training.pyc in train_on_batch(self, x, y, sample_weight, class_weight)
1312 sample_weight=sample_weight,
1313 class_weight=class_weight,
-> 1314 check_batch_axis=True)
1315 if self.uses_learning_phase and not isinstance(K.learning_phase, int):
1316 ins = x + y + sample_weights + [1.]
/home/user/anaconda2/lib/python2.7/site-packages/keras/engine/training.pyc in _standardize_user_data(self, x, y, sample_weight, class_weight, check_batch_axis, batch_size)
1027 self.internal_input_shapes,
1028 check_batch_axis=False,
-> 1029 exception_prefix=‘model input’)
1030 y = standardize_input_data(y, self.output_names,
1031 output_shapes,
/home/user/anaconda2/lib/python2.7/site-packages/keras/engine/training.pyc in standardize_input_data(data, names, shapes, check_batch_axis, exception_prefix)
122 ’ to have shape ’ + str(shapes[i]) +
123 ’ but got array with shape ’ +
–> 124 str(array.shape))
125 return arrays
126
ValueError: Error when checking model input: expected lambda_input_1 to have shape (None, 3, 224, 224) but got array with shape (32, 3, 256, 256)
I’m assuming it has to do with non-matching shapes of arrays, but I can’t really understand where the problem is and why that mismatch is happening.
Any help on this?