@nzhang,
Yeah, they were in the right directory.
I re-started my kernel as @gnavink suggested and am able to pass through vgg.test. Probably something with respect to path got messed up as I was executing cells multiple times.
Thanks!
@nzhang,
Yeah, they were in the right directory.
I re-started my kernel as @gnavink suggested and am able to pass through vgg.test. Probably something with respect to path got messed up as I was executing cells multiple times.
Thanks!
Hello nicolas, looked at your notebook to avoid memory problem in Lesson2 because of get_data(). its quite good that you have tried it on a different note… would have saved me a day’s effort if I had seen it before. I also stumbled upon the same approach which you had taken that of calling model.predict_generator().
Is there any reason why you had made shuffle=False while calling get_batches()
I get 97% validation accuracy as expected if shuffle=False. But when i call get_batches() with shuffle= True both my training & validation accuracy drops down to around 50%.
I have no clue why it happens… My understanding is shuffle=True on a training data should provide randomness to have a better accuracy while training the model… But I don’t know why the accuracy drops down…
Quoted the code here for better understanding of the problem…
`Preformatted text
batch_size = 64
train_batches = get_batches(trainpath, batch_size = batch_size, shuffle = False )
valid_batches = get_batches(validpath, batch_size = batch_size, shuffle = False )
def onehot(x): return np.array(OneHotEncoder().fit_transform(x.reshape(-1,1)).todense())
train_labels = onehot(train_batches.classes)
valid_labels = onehot(valid_batches.classes)
vgg = Vgg16()
model = vgg.model
train_features = model.predict_generator(train_batches, val_samples = train_batches.N)
valid_features = model.predict_generator(valid_batches, val_samples = valid_batches.N)
lm = Sequential([ Dense( 2, activation = ‘softmax’, input_shape=(1000,)) ])
lm.compile(optimizer = RMSprop(lr = 0.1), loss = ‘categorical_crossentropy’, metrics = [‘accuracy’] )
lm.fit(train_features, train_labels, batch_size = batch_size, nb_epoch = 3,
validation_data = (valid_features, valid_labels))
`
I get a training & validation accuracy of around 97% after training 3 epochs.
Now restarted the kernel. Made shuffle = True and re-ran the model.
indent preformatted text by 4 spaces
train_batches = get_batches(trainpath, batch_size = batch_size, shuffle = True )
valid_batches = get_batches(validpath, batch_size = batch_size, shuffle = True )
Any suggestions on why such a drop in accuracy??
navin
My query was regarding the post by nicholas
http://forums.fast.ai/t/lesson-2-discussion/161/271
Trying to quote that post here using quote post feature…
hope it helps to correlate the query with that specific post.
I apologize in case the query is quite messy… New to this forum . trying to learn how to use quote post feature of the forum.
Is there any reason why :
In Cell No:14 val_batch with 23000 samples is used while doing model.predict_generator() instead of train_batches. I believe you want to get the 1000 category predictions for training data in that cell.
Also the batch_size has been set to 1 when using get_batches() for training data while valid_batches has batch_size of 40. I hope its just a choice …
Navin,
Yeah, if I recall correctly (haven’t looked at this notebook recently though) if you use shuffle = TRUE then your batch set won’t match with the actual labels you’re feeding to the model.
The reason for that is that you’re shuffling the images (random order) and then you’re training the model against an ordered list of labels.
It actually makes sense that your accuracy would drop to 50% : the model at this point is probably just recognizing cats and dogs as being the same and guessing correctly half of the time (totally random).
HTH,
N.
on #1 : I think you’re right. This should be train_batches. Probably just a copy & paste error from cell 11. I will re-run that part to see if it changes anything. My guess is that I already had the training predictions on disk and when I reformatted the notebook it used that.
on #2 : you should definitely change that. I was originally doing some tests to see if there was a significant difference in processing time and memory consumption when using different batch sizes. I probably forgot to reset it to using batch_size=40.
If I have time next week I’ll update the notebook to Keras 2. Since I updated my environment, it’s a little difficult to revert back to Keras 1.2.
Thanks !
N.
was doing the lesson2 notebook ie removing the last dense layer of 1000 predictions of vgg’s model
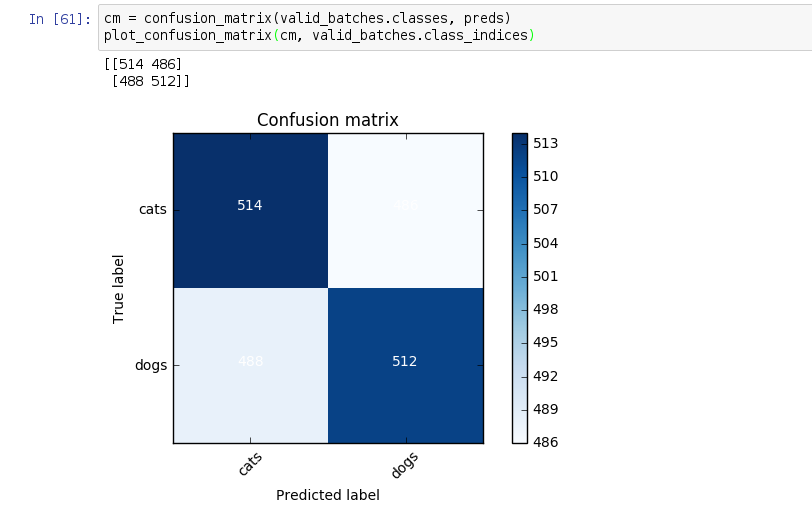
and adding a dense layer with 2 outputs with dogscats data. The same dogscats data was also used in the class. I got the validation accuracy to 97.75 %. But when I plot the confusion matrix i get weird results…
I assume that when val_accuracy is around 97% and the validation data is 2000 samples, the no.of misclassifications should be only around : (3/100) * 2000 = 60
But my confusion matrix is showing:
My code is as follows:
indent preformatted text by 4 spaces
vgg = Vgg16()
model = vgg.model
train_batches = get_batches(trainpath, batch_size = batch_size)
valid_batches = get_batches(validpath, batch_size = batch_size)
Found 23000 images belonging to 2 classes.
Found 2000 images belonging to 2 classes.
model.pop()
for layer in model.layers:
layer.trainable = False
model.add(Dense(2, activation = ‘softmax’))
model.compile(optimizer = RMSprop(lr = 0.1), loss = ‘categorical_crossentropy’, metrics = [‘accuracy’])
def fit_model(train_batches, valid_batches, nb_epoch = 1 ):
model.fit_generator(train_batches, samples_per_epoch=train_batches.N, nb_epoch = nb_epoch,
validation_data = valid_batches, nb_val_samples = valid_batches.N)
fit_model(train_batches, valid_batches, nb_epoch = 1 )
Epoch 1/1
23000/23000 [==============================] - 628s - loss: 0.6630 - acc: 0.9565 - val_loss: 0.5950 - val_acc: 0.9610
fit_model(train_batches, valid_batches, nb_epoch = 1 )
Epoch 1/1
23000/23000 [==============================] - 628s - loss: 0.5184 - acc: 0.9672 - val_loss: 0.3477 - val_acc: 0.9775
probs = model.predict_generator(valid_batches, val_samples = valid_batches.N)
preds = np_utils.probas_to_classes(probs)
cm = confusion_matrix(valid_batches.classes, preds)
plot_confusion_matrix(cm, valid_batches.class_indices)
any thoughts why its so…
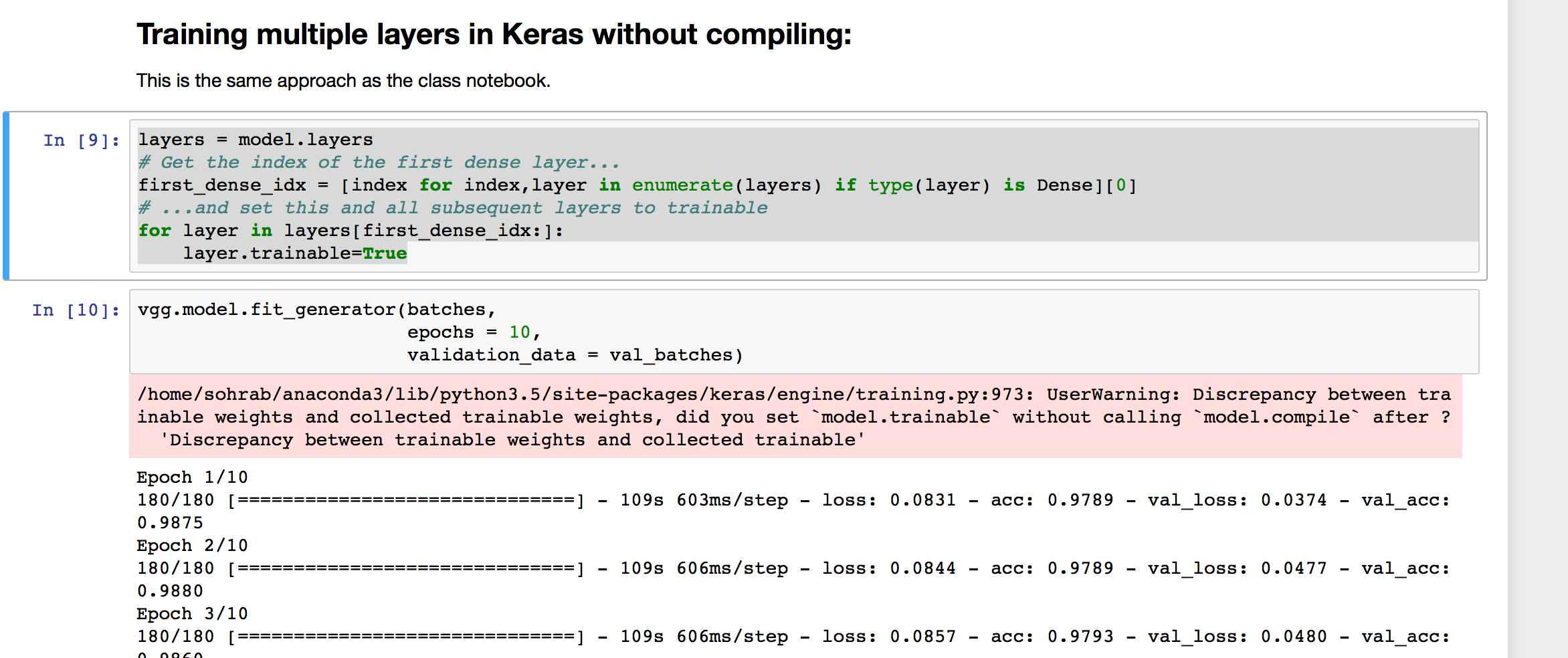
I have been going through lesson 2 part one and I am not sure whether I’ve identify and issue in the original code in “Training multiple layers in Keras” section.
I am not sure if we are updating weights if “model.compile” has not been run after updatating the first Dense layer to a trainable layer. So basically, without compiling the model after updating the layer (or layers) to become trainable, running more epochs will not update the corresponding weights. Although looking at the summary of the model, it shows that the weights are trainable but underneath the model is not updating the weights. In keras2 this issue will raise a warning but in Keras1 no warning will be flagged. I run the model on two system with Kears 1 and 2.
To elaborate on this issue I have ran few test and in the following I am sharing my results on Keras2. Image below shows the process of dropping the last layer, adding a dense layer with 2 output and running two epochs to train this last layer. As you can see each epoch takes about 107s and 592ms/step.
Image below shows the result of changing the first dense layer to trainable but not compiling the model and Keras 2 is raining a waning. very similar epoch and step speed to the previous section.
After compiling the model, the loss increased from 0.08 to 8.06 and we see a slightly longer processing time.
Furthermore according the Keras documentation, one must compile for the effect to take place:
“Additionally, you can set the trainable property of a layer to True or False after instantiation. For this to take effect, you will need to call compile() on your model after modifying the trainable property
” (https://keras.io/getting-started/faq/)
So in conclusion, I believe in the section that we tired to train and update the weights on the last Dense layer we are not doing anything. Please let me know if I am missing something here?
Here are the links to my notebooks:
Keras 1:
keras 2:
Following this post. Same question.
Hi,
Facing same issue. Did you figure out why?
It looks like the dog and cat images have a mixture of sizes:
http://wiki.fast.ai/index.php/Lesson_2_Notes#Visualization_of_Results
How does the convnet handle input matrices of different sizes?
Hi all.
I’ve run into something I think is strange. I’m following the steps recommended in the Lesson 2 notebook, namely:
What I’ve observed, consistently, is that the training loss goes from 1.x (1.29 in my latest attempt) back to 2.3 (i.e. random) when I start training step 2. Is this normal? Does anyone know what the loss would jump back up?
Thanks.
Hi, I tried to set layers.trainable=True just for testing purpose. But my model accuracy drops down to 50%. Why?? My guess was that accuracy should have increased ? But that wasn’t the case. Can someone explain why the accuracy dropped.
can you show the changes made to vgg16.py when using keras 2 api.
i am getting an error where i dont know how to rectify that issue.
but I am sure that the issue is causing because of vgg16.py
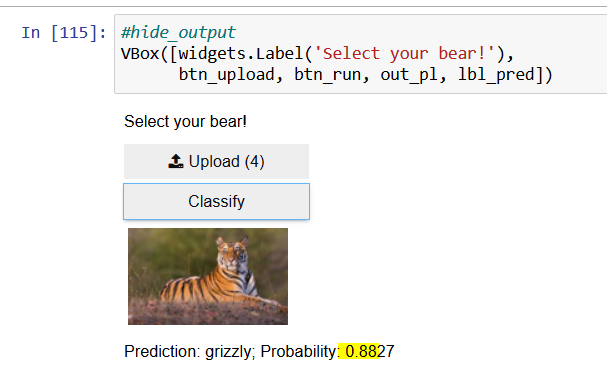
Hi, I did the training in the lesson, but get strange results when I try predictions on some fringe cases.
How can we explain such a high probability for the image below?