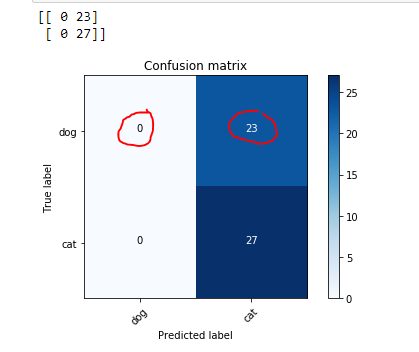
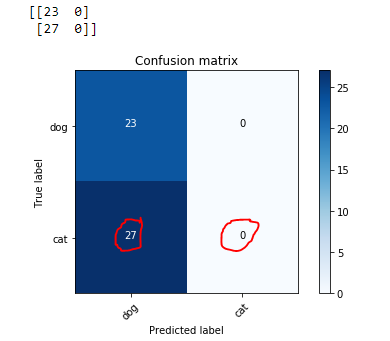
I am trying to run the linear model code from Lesson 2, but I get 87% accuracy rather than the 97% obtained by Jeremy – any hints on what may be going wrong?
lm.fit(trn_features, trn_labels, nb_epoch=15, batch_size=batch_size,
validation_data=(val_features, val_labels))
Train on 23000 samples, validate on 2000 samples
Epoch 1/15
23000/23000 [==============================] - 0s - loss: 0.3425 - acc: 0.8536 - val_loss: 0.3388 - val_acc: 0.8625
Epoch 2/15
23000/23000 [==============================] - 0s - loss: 0.3288 - acc: 0.8685 - val_loss: 0.3543 - val_acc: 0.8685
Epoch 3/15
23000/23000 [==============================] - 0s - loss: 0.3326 - acc: 0.8735 - val_loss: 0.3628 - val_acc: 0.8710
Epoch 4/15
23000/23000 [==============================] - 0s - loss: 0.3345 - acc: 0.8737 - val_loss: 0.3771 - val_acc: 0.8685
Epoch 5/15
23000/23000 [==============================] - 0s - loss: 0.3356 - acc: 0.8779 - val_loss: 0.3820 - val_acc: 0.8735
Epoch 6/15
23000/23000 [==============================] - 0s - loss: 0.3405 - acc: 0.8770 - val_loss: 0.3928 - val_acc: 0.8730
Epoch 7/15
23000/23000 [==============================] - 0s - loss: 0.3425 - acc: 0.8779 - val_loss: 0.3972 - val_acc: 0.8715
Epoch 8/15
23000/23000 [==============================] - 0s - loss: 0.3431 - acc: 0.8781 - val_loss: 0.4090 - val_acc: 0.8685
Epoch 9/15
23000/23000 [==============================] - 0s - loss: 0.3456 - acc: 0.8782 - val_loss: 0.4156 - val_acc: 0.8720
Epoch 10/15
23000/23000 [==============================] - 0s - loss: 0.3471 - acc: 0.8798 - val_loss: 0.4123 - val_acc: 0.8695
Epoch 11/15
23000/23000 [==============================] - 0s - loss: 0.3490 - acc: 0.8800 - val_loss: 0.4238 - val_acc: 0.8735
Epoch 12/15
23000/23000 [==============================] - 0s - loss: 0.3499 - acc: 0.8795 - val_loss: 0.4216 - val_acc: 0.8725
Epoch 13/15
23000/23000 [==============================] - 0s - loss: 0.3514 - acc: 0.8809 - val_loss: 0.4211 - val_acc: 0.8730
Epoch 14/15
23000/23000 [==============================] - 0s - loss: 0.3521 - acc: 0.8802 - val_loss: 0.4354 - val_acc: 0.8680
Epoch 15/15
23000/23000 [==============================] - 0s - loss: 0.3520 - acc: 0.8801 - val_loss: 0.4226 - val_acc: 0.8750