Also, it turns out that minimizing squared errors is equivalent to maximum likelihood for Gaussian noise, so you get some of the neat proofs Jeremy was hinting at
6 Likes
This is an interesting article on how extremely different datasets can nevertheless have the same mean, standard deviation, and Pearson correlation. It’s a great graphic reminder of the value of plotting the data!
9 Likes
can anybody explain "degrees of freedom " in this gap of technical issue
4 Likes
Seems like it’s a.__add__(b)
class Addables:
def __init__(self, n, label):
self.n = n
self.label = label
def __add__(self, another_addable):
return Addables(self.n + another_addable.n, self.label + " + " + another_addable.label)
def __repr__(self):
return "{0} = {1}".format(self.label, self.n)
a1 = Addables(1, "a1")
print(a1)
a2 = Addables(2, "a2")
print(a2)
a3 = a1 + a2
print(a3)
a3p = a2 + a1
print(a3p)
Gives
a1 = 1
a2 = 2
a1 + a2 = 3
a2 + a1 = 3
5 Likes
Thanks for the investigation!
This was mentioned earlier in the thread but there’s also an __radd__ method for when the thing on the left doesn’t have an __add__ method compatible with the thing on the right.
2 Likes
This course is so exciting! So dense, a lot of very valuable tips on software design. And I get a much better understanding of low-level internal workings of deep learning. Especially combined with the high-level part 1 of the course, it makes for a very good learning experience!
11 Likes
Does anyone use nano to check out source code or know a tutorial?
These 3 lectures are a few semesters of CS. Very intense and exciting content.
3 Likes
this version works well for me, I like the bottom up approach.
2 Likes
This is awesome and very instructive, thank you!
1 Like
Looking at the VSCode shortcuts, you can go back and forth between things using ^- & ^⇧-, which is ctrl + - for back and ctrl + shift + - for forward
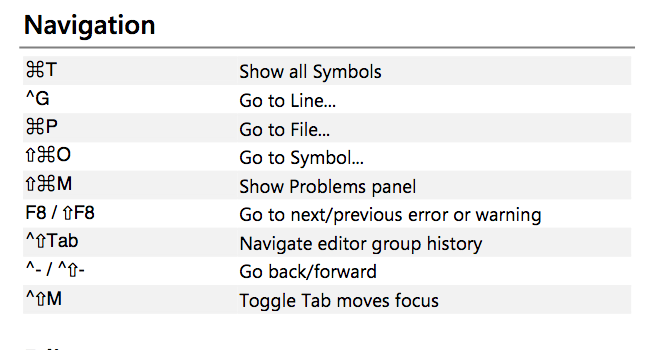
4 Likes
Better still to get a more comprehensive list with Ctrl+k Ctrl+s to get a searchable list in VScode
For the variance discussion, do data has to fall under a normal distribution for it to work?
I don’t think so, the discussion that happened so far makes no assumptions about the underlying distribution.
No, variance is defined for pretty much any distribution (unless summing your squares get you to infinity).
1 Like
For someone who is interested in diving deeper into the probability theory, there is a great book Introduction to Probability I find very helpful. Starting with some basic combinatorics, it goes deeper with each chapter. Also, there are many exercises, and some of them are solved by authors.
1 Like
Kevin Murphy 's book “Machine Learning A Probabilistic Perspective” is also helpful to understand these better
like levy distribution, very common but can have infinte variance
2 Likes
Can we add a dummy class incase none of the objects are in the Image and use Softmax?