Can you give me some idea of what do you mean by LR decrease on plateau? how does that work?
This is a good idea. Also thinking if datasets play a part in the choice as well as @miwojc mentioned
this is doc page from Keras about this callback. it tracks loss and when it doesn’t improve it would automatically decrease learning rate. you can decide on how many epochs to wait after no improvement and how much to decrease learning rate.
https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/ReduceLROnPlateau
PyTorch also has a version of it: https://pytorch.org/docs/stable/optim.html#torch.optim.lr_scheduler.ReduceLROnPlateau
2 Likes
A recording of (part) of a discussion on Zoom exploring the lesson 1 code will be available here shortly: https://youtu.be/uwmwWGJfA84 ~3min from this post or so
6 Likes
Can you record all of them? That will be really helpful 
1 Like
If I have control of the room, I’ll try to. (Anyone that does can push record  )
)
3 Likes
Ranger already does a gradual LR warm-up. So you should generally use Ranger+flat_cos or Adam+one_cycle.
5 Likes
@muellerzr Is it possible to record the questions asked as well? I’m watching through the video which is very helpful as is but I’m trying to interpret the question based on the answer you gave in the walkthrough! 
1 Like
I wasn’t able to look it over, but it sounds like it didn’t pick up everyone else I take it. In the future I’ll use the built in zoom recording so that should be better. Apologies!
I’ve been working on reconstructing Hyperspectral Imagery from an RGB input using the NoGAN approach and for me switching to Ranger+OneCycle slashed the MRAE (Mean Relative Absolute Error) metric by half (~0.11 to ~ 0.0575. But this is just “one” instance, I haven’t used it anywhere else at this point.
3 Likes
That’s really cool. And now that I think about it, most of the benefit I got using Ranger + fit_one_cycle comes from the RAdam part, and less so the LookAhead optimizer. So I might try running only RAdam + fit_one_cycle and see if I can get a speedup!
Currently I’m running some FastGarden tests and it looks like Ranger + fit_flat_cos blows the one-cycle learning policy out of the water (by ~5-8%).
1 Like
Maybe a dumb question but, Currently both keras, pytorch and fastai reduces the learning rate after it hit the patience limit on a plateau right? Why not rollback into the last best state, reduce the lr and continue instead of just reducing the lr and continuing further?
2 Likes
Not quite. If you look at how the source code for these functions work, you’re passing in a % to work off of. For instance with flat_cos, we reduce after 75% of the batches. This is also in fit_one_cycle:
def fit_one_cycle(self:Learner, n_epoch, lr_max=None, div=25., div_final=1e5, pct_start=0.25 <- HERE, wd=None,
moms=None, cbs=None, reset_opt=False):
def fit_flat_cos(self:Learner, n_epoch, lr=None, div_final=1e5, pct_start=0.75 <- HERE, wd=None,
cbs=None, reset_opt=False):
3 Likes
Ok I got that, but I was talking about the ReduceLROnPlateau callback.
2 Likes
Ah shoot my bad ![]() In that case I don’t know but I am anticipating the answer too
In that case I don’t know but I am anticipating the answer too ![]()
1 Like
Why not rollback into the last best state, reduce the lr and continue
I am by no means an expert on any of this, but I can take a guess. Sometimes, the extra training beyond the “plateau” is useful for deep models, even though this training would go into the “overfitting” regime by classical machine learning standards. Empirically, there is a second descent phase of training in deep learning:
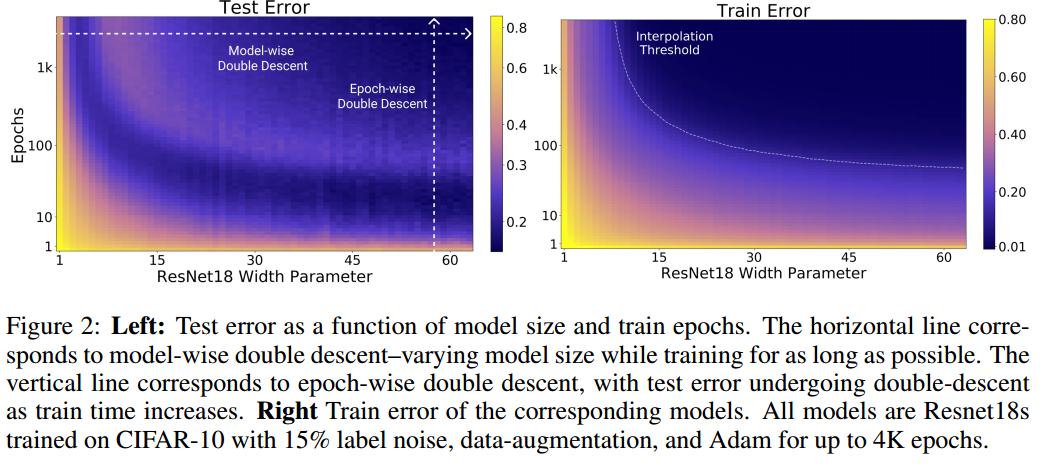
This is Figure 2 from the paper about “Deep Double Descent” (arXiv: 1912.02292), which does a great job of explaining these concepts (and much more) in detail. Relevant to our discussion is this result: training beyond the plateau causes the validation/test error to rise, and then miraculously fall again. In other words, extraneous training can undo overfitting! (The same can be accomplished by using larger models.)
Now is this why deep learning practictioners (and ReduceLROnPlateau) doesn’t roll back to an earlier epoch? Probably not, I’m guessing that it was written before fastai made the idea of callbacks as popular as it is now. But perhaps it has created unintentional benefits!
EDIT – accidentally included the wrong figure.
3 Likes
a less advanced question ;).
reading the notebooks I was wondering if we still need to normalize the images (Normalize.from_stats(*imagenet_stats) in v2?! Couldn’t find any information regarding normalization.
Florian
Yes you do, normalization should always be done on your data! However fastai2 has made it a bit easier with the pre-built functions (like cnn_learner, unet_learner). If you use them and say accidentally forget to tag on normalize() it’ll normalized based on your models data
This video is so much clearer than mine, can you please share your OBS settings with me?
1 Like