Yes. It does.
No problems at all! Watched it right thru.
I had this question as well! Why pick a learning rate point where the loss was still improving and not the lowest point?
In this line
data = ImageClassifierData.from_paths(PATH, tfms=tfms_from_model(resnet34, 299), bs=64)
bs = batch size which has a default value of 64. In the notebook, the bs is omitted in the function call so it defaults to 64. I only put it in above so it’s evident.
Good question! I was looking forward to that as well…I believe this thread is well along on that topic ==> AWS GPU install script and public AMI
1 Like
Hi Guys, @jeremy suggested to create private groups in the forum, I can’t really find a way of doing that. Has anyone done this yet?
Thanks @jeremy , @yinterian and Anurag(crestle) for the session today. Unfortunate scaling/streaming issues earlier, but things went all good later on  Time to get some sleep in this timezone now.
Time to get some sleep in this timezone now. 
4 Likes
Go to your messages and create a new message and invite people you want to that.
1 Like
You can send your teammates a private message, and start a messaging group that way.
Use the highlighted button as shown in this image (available on the top right corner).

1 Like
I suggest trying a higher learning rate (the learning rate at the lowest point) and comparing your results to the rate Jeremy used. The idea is we want to converge as fast as possible to optimize the function we are approximating without going too fast.
In part 1 v1, Jeremy explains using too high of a learning rate as if we are jumping over a valley, instead of further down into the valley.
The lrf=learn.lr_find() function is increasing the learning rate gradually during training. The plot you see is the loss, which we generally want to minimize, as a function of the learning rate.
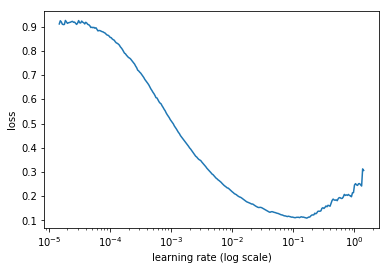
If you want to learn more about what is being done, I suggest reading the paper referenced (https://arxiv.org/abs/1506.01186). **note, in the paper they tell you to plot accuracy vs. learning rate and pick the learning rate where the accuracy is still increasing, at the end of the day this should have the same outcome as plotting against loss and picking the learning rate where loss is still decreasing.
Maybe someone else out there has a better explanation of “why” this works. To be perfectly honest, I’m not entirely sure. It might be one of those things where theory hasn’t caught up with best practices yet.
4 Likes
Awesome!
Duly understood 
1 Like
Questions
Code
- All items of the particular class should belong to one folder. Is this fast.ai library’s expectation which I believe is by design like Keras?
Using fast.ai library
- How good is my knowledge if I use libraries on top of libraries? e.g. PyTorch, fast.ai etc. etc. Having said that, should I invest time in understanding fast.ai? I know Jeremy replied to this question already and requested students to contribute to the library than understand it. I still have the question in terms of overall knowledge because of so many abstractions! Creating a wiki/documentation page for the fasi.ai library is something that can help us understand the library and also make the library popular.
Switching team
- Can I switch a team in the same timezone since I personally know someone who is part of the different team. Since we are at the same location, in-person meetings can be more productive?
Since we are using fast.ai’s open source libraries, we all will get used to functions and parameters by end of the course. We’ve part2 v2 and ML courses which will utilize the same library. 
What did I do wrong? I’m unable to run lesson1.
This file contains all the main external libs we’ll use
from fastai.imports import *
ImportError Traceback (most recent call last)
in ()
1 # This file contains all the main external libs we’ll use
----> 2 from fastai.imports import *
ImportError: No module named ‘fastai’
1 Like
Hi Jeremy and classmates. I have Windows 10 on a notebook, and also Windows 10 on a desktop with an older NVIDIA GPU which works under Windows 10 for Tensorflow. However, for Pytorch I am running WSL as we need to be using Ubuntu - and therefore I have no CUDA.
Is it possible that despite all of the instructions about setting up my PC and the nicely packaged fastai environment, I won’t actually be able to make use of this setup, and will have to do everything from a cloud instance with a GPU? I did clone the fastai github repo, and ran the environment.yml and started the fastai environment, but when trying to run lesson 1 notebook I immediately had many problems loading various libraries on the import * line, so I wonder if there is any point in trying anything more locally, given my situation.
Thanks
Without GPU support, you can still manage to run the notebooks (probably have to change few lines of codes like pytorch,cuda, maybe too much of work), but it will be really slow. Can you manage to setup dual boot in your system? It seems not right to not use GPU when you have access to it and pay Amazon.
This one is too good.
1 Like
Yes, I could set up dual boot on my desktop PC. Never done it before so if you have any tips please let me know! It won’t help me during class as I am accessing that during the working day from my laptop, but after working hours I will be fine to use it.
But your reply suggests that I should be able to run it anyway, so why all of the issues loading libraries? Do I need to go through each one and fix them - if there are these dependencies then why are they not included in the environment.yml I wonder?
Just try pip install missing packages.
You can still access your desktop from by ssh into it. I am not an expert but I can help you with setting up dual boot. Just send me a private message.