Was just looking for a tmux cheatsheet. Thanks so much!
Ok, I’m finding these forums a little confusing in terms of organization, and I hope this is the right place to post, but if it’s not, I’d appreciate it if someone would point me in the right direction.
So, I’ve created a new directory structure from the kaggle images downloaded with kaggle-cli. What I did was: I put them all in a folder called ‘train’, and then divided them into two directories (cats, dogs) according to their filenames. Then I made a cross-validation directory in the same folder where I put ‘train’, and I called it ‘valid’. I put about 20% of the images from ‘train’ into ‘valid’, using the crude method of ‘mv *3.jpg …’, ‘mv *4.jpg …’ to get that division of images. This allowed me to train vgg on those images (in a copy of the original Lesson 1 notebook), and the training went as expected. So far so good!
But I was a bit stumped at the next step. I copied some of the images from the test set into a directory called ‘smalltest’ (‘cp [0-9].jpg …’, copying 10 test images to make a small test), and then I tried to get predictions for those images, but that’s where I faltered. I looked at the example code, and it seems to want to use vgg.predict() on images being fed to it. That seems straightforward, except that I can’t seem to find a way to feed the predict() method images from ‘smalltest’ that doesn’t throw errors!
I even tried:
small_batch = vgg.get_batches(path+'smalltest', batch_size=2) #I used 2 because I keep getting a 'modulo by zero error and I thought lower batch values might fix it, but the error seems independent of this value
for img, label in small_batch:
plots(img, label)
In order to try to have any idea of how to get vgg to take these images in, and of course this fails. It looks like the predict() method should work straightforwardly if I can feed it data in the way it’s expecting, but I am not sure how to do that.
Edit:
I forgot to mention that I’m on a p2 server. I looked around in this forum again and decided to try the test() method as described above. Like this:
batches, preds = vgg.test(path + 'smalltest', batch_size=batch_size) out = [] for img_path,pred in zip(batches.filenames, preds): out.append([img_path,pred]) print(out)
(Printing them out as an initial sanity check)
I again got the same error:
Exception in thread Thread-6: Traceback (most recent call last): File "/home/ubuntu/anaconda2/lib/python2.7/threading.py", line 801, in __bootstrap_inner self.run() File "/home/ubuntu/anaconda2/lib/python2.7/threading.py", line 754, in run self.__target(*self.__args, **self.__kwargs) File "/home/ubuntu/anaconda2/lib/python2.7/site-packages/keras/engine/training.py", line 425, in data_generator_task generator_output = next(generator) File "/home/ubuntu/anaconda2/lib/python2.7/site-packages/keras/preprocessing/image.py", line 593, in next index_array, current_index, current_batch_size = next(self.index_generator) File "/home/ubuntu/anaconda2/lib/python2.7/site-packages/keras/preprocessing/image.py", line 441, in _flow_index current_index = (self.batch_index * batch_size) % N ZeroDivisionError: integer division or modulo by zero
My last hypothesis about this was that it must somehow be because I have too few images in the directory. So I tried it on the ‘test’ directory rather than the ‘smalltest’ directory, and got the same result again. Is this somehow a problem with the Keras version installed?
It is not working for me too 
I’m using Python 3.6 on AWS (linux) and I’m having issue pip3 installing pillow. I did try pip3 installing Image but still I’m getting error installing pillow:
‘Command "/usr/local/bin/python3.6 -u -c "import setuptools, tokenize;file=’/tmp/pip-build-6fiat3 yy/pillow/setup.py’;f=getattr(tokenize, ‘open’, open)(file);code=f.read().replace(’\r\n’, ‘\n’);f.close();exec(compile(code, file, ‘exec’))" install --record /tmp/pip-96wvf_jn-record/install-record.txt --single-version-externally-managed --compile --install-scripts=/usr/bin" failed with error code 1 in /tmp/pip-build-6fiat3yy/pillow/’
Any idea how I could fix it?
Follow-up on my previous question:
The problem was that there needed to be a sub-folder in the ‘test’ folder. It doesn’t read from the directory it’s pointed to, but rather it reads from its subdirectories. The modulo by zero error was because it was reading zero images in the ‘test’ directory. When I moved all the images to ‘test/unknown’, it fixed the issue.
The link has expired can you check that once.
Hi everybody.
I have Ubuntu 16.04 with nvidia GPU on my notebook and just installed fastai and everything was installed successfully.
I’m trying to run the code of lesson1 (cats and dogs) but i am having this error on the first import line:
ImportError: libavcodec.so.53: cannot open shared object file: No such file or directory
I have libavcodec56 and tried to install libevcode53 but seems like for some reason it is not possible!!
when trying to install it or any older dependancies like version 51, I constantly get this msg:
The following packages will be REMOVED:
libavcodec53
and it is weird because apparently this package is not installed at all!!
apt-cache search libavcodec53
also doesn’t return anything!
Can somebody help me with this issue plz?
Many thanks in advance.
Hi,
Having completed the dogs/cats example and a good/bad images of my own, I would like to expand on it with a useful application by separating the results to 2 new folders: “good_images” and “bad_images”.
This also means that I would like to run the model without the validation folder.
In other words, I would like to run a cats/dogs example but the output would create the equivalent of the “data/dogscats/valid” folder.
I am a developer in multiple languages but not Python. Could someone point out in the lesson1 notebook which sections of code I need to modify and hint at a python commands I could use to do this?
I assume I will have to start in section In [134] (os.listdir(f’{PATH}valid’)) and continue until In [141]
(after 141 it would be no longer relevant)
Lastly: thank you all for the good information here and also for the course.
/Florin
I am getting same error while executing the code " import utils; reload(utils)
from utils import plots "
Seems that u got the same error .Did u get the solution?
“”""""""""""""""""""""""""""""“Error”""""""""""""""""
ValueError Traceback (most recent call last)
in ()
----> 1 import utils; reload(utils)
2 from utils import plots
/home/ubuntu/FastAI/PROJECTS/courses/deeplearning1/nbs/utils.py in ()
26 from IPython.lib.display import FileLink
27
—> 28 import theano
29 from theano import shared, tensor as T
30 from theano.tensor.nnet import conv2d, nnet
/home/ubuntu/anaconda2/lib/python2.7/site-packages/theano/init.pyc in ()
86
87
—> 88 from theano.configdefaults import config
89 from theano.configparser import change_flags
90
/home/ubuntu/anaconda2/lib/python2.7/site-packages/theano/configdefaults.py in ()
135 “letters, only lower case even if NVIDIA uses capital letters.”),
136 DeviceParam(‘cpu’, allow_override=False),
–> 137 in_c_key=False)
138
139 AddConfigVar(
/home/ubuntu/anaconda2/lib/python2.7/site-packages/theano/configparser.pyc in AddConfigVar(name, doc, configparam, root, in_c_key)
285 # This allow to filter wrong value from the user.
286 if not callable(configparam.default):
–> 287 configparam.get(root, type(root), delete_key=True)
288 else:
289 # We do not want to evaluate now the default value
/home/ubuntu/anaconda2/lib/python2.7/site-packages/theano/configparser.pyc in get(self, cls, type_, delete_key)
333 else:
334 val_str = self.default
–> 335 self.set(cls, val_str)
336 # print “RVAL”, self.val
337 return self.val
/home/ubuntu/anaconda2/lib/python2.7/site-packages/theano/configparser.pyc in set(self, cls, val)
344 # print “SETTING PARAM”, self.fullname,(cls), val
345 if self.filter:
–> 346 self.val = self.filter(val)
347 else:
348 self.val = val
/home/ubuntu/anaconda2/lib/python2.7/site-packages/theano/configdefaults.py in filter(val)
114 elif val.startswith(‘gpu’):
115 raise ValueError(
–> 116 'You are tring to use the old GPU back-end. ’
117 'It was removed from Theano. Use device=cuda* now. ’
118 'See https://github.com/Theano/Theano/wiki/Converting-to-the-new-gpu-back-end(gpuarray) ’
ValueError: You are tring to use the old GPU back-end. It was removed from Theano. Use device=cuda* now. See https://github.com/Theano/Theano/wiki/Converting-to-the-new-gpu-back-end(gpuarray) for more information.
After following the instruction from link ‘https://github.com/Theano/Theano/wiki/Converting-to-the-new-gpu-back-end(gpuarray)’ like used below command
conda install theano pygpu still issue is not resolved
I have the same problem.have you fixed it?
when I run the following code in lesson1.ipynb:
vgg = Vgg16()
# Grab a few images at a time for training and validation.
# NB: They must be in subdirectories named based on their category
batches = vgg.get_batches(path+'train', batch_size=batch_size)
val_batches = vgg.get_batches(path+'valid', batch_size=batch_size*2)
vgg.finetune(batches)
vgg.fit(batches, val_batches, nb_epoch=1)
there is something wrong:
Downloading data from http://files.fast.ai/models/imagenet_class_index.json
16384/35363 [============>.................] - ETA: 0sFound 16 images belonging to 2 classes.
Found 8 images belonging to 2 classes.
Epoch 1/1
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-9-dcf03b063aee> in <module>()
5 val_batches = vgg.get_batches(path+'valid', batch_size=batch_size*2)
6 vgg.finetune(batches)
----> 7 vgg.fit(batches, val_batches, nb_epoch=1)
/home/bnrc/lee/jupyter/fast.ai/courses/deeplearning1/nbs/vgg16.pyc in fit(self, batches, val_batches, nb_epoch)
211 """
212 self.model.fit_generator(batches, samples_per_epoch=batches.nb_sample, nb_epoch=nb_epoch,
--> 213 validation_data=val_batches, nb_val_samples=val_batches.nb_sample)
214
215
/home/bnrc/.conda/envs/DL-Py2/lib/python2.7/site-packages/keras/models.pyc in fit_generator(self, generator, samples_per_epoch, nb_epoch, verbose, callbacks, validation_data, nb_val_samples, class_weight, max_q_size, nb_worker, pickle_safe, **kwargs)
880 max_q_size=max_q_size,
881 nb_worker=nb_worker,
--> 882 pickle_safe=pickle_safe)
883
884 def evaluate_generator(self, generator, val_samples,
/home/bnrc/.conda/envs/DL-Py2/lib/python2.7/site-packages/keras/engine/training.pyc in fit_generator(self, generator, samples_per_epoch, nb_epoch, verbose, callbacks, validation_data, nb_val_samples, class_weight, max_q_size, nb_worker, pickle_safe)
1459 outs = self.train_on_batch(x, y,
1460 sample_weight=sample_weight,
-> 1461 class_weight=class_weight)
1462 except:
1463 _stop.set()
/home/bnrc/.conda/envs/DL-Py2/lib/python2.7/site-packages/keras/engine/training.pyc in train_on_batch(self, x, y, sample_weight, class_weight)
1237 ins = x + y + sample_weights
1238 self._make_train_function()
-> 1239 outputs = self.train_function(ins)
1240 if len(outputs) == 1:
1241 return outputs[0]
/home/bnrc/.conda/envs/DL-Py2/lib/python2.7/site-packages/keras/backend/theano_backend.pyc in __call__(self, inputs)
790 def __call__(self, inputs):
791 assert type(inputs) in {list, tuple}
--> 792 return self.function(*inputs)
793
794
/home/bnrc/.conda/envs/DL-Py2/lib/python2.7/site-packages/theano/compile/function_module.pyc in __call__(self, *args, **kwargs)
915 node=self.fn.nodes[self.fn.position_of_error],
916 thunk=thunk,
--> 917 storage_map=getattr(self.fn, 'storage_map', None))
918 else:
919 # old-style linkers raise their own exceptions
/home/bnrc/.conda/envs/DL-Py2/lib/python2.7/site-packages/theano/gof/link.pyc in raise_with_op(node, thunk, exc_info, storage_map)
323 # extra long error message in that case.
324 pass
--> 325 reraise(exc_type, exc_value, exc_trace)
326
327
/home/bnrc/.conda/envs/DL-Py2/lib/python2.7/site-packages/theano/compile/function_module.pyc in __call__(self, *args, **kwargs)
901 try:
902 outputs =\
--> 903 self.fn() if output_subset is None else\
904 self.fn(output_subset=output_subset)
905 except Exception:
RuntimeError: error getting worksize: CUDNN_STATUS_BAD_PARAM
Apply node that caused the error: GpuDnnConv{algo='small', inplace=True, num_groups=1}(GpuContiguous.0, GpuContiguous.0, GpuAllocEmpty{dtype='float32', context_name=None}.0, GpuDnnConvDesc{border_mode='valid', subsample=(1, 1), dilation=(1, 1), conv_mode='conv', precision='float32', num_groups=1}.0, Constant{1.0}, Constant{0.0})
Toposort index: 238
Inputs types: [GpuArrayType<None>(float32, 4D), GpuArrayType<None>(float32, 4D), GpuArrayType<None>(float32, 4D), <theano.gof.type.CDataType object at 0x7fe99837a5d0>, Scalar(float32), Scalar(float32)]
Inputs shapes: [(16, 3, 226, 226), (64, 3, 3, 3), (16, 64, 224, 224), 'No shapes', (), ()]
Inputs strides: [(612912, 204304, 904, 4), (108, 36, 12, 4), (12845056, 200704, 896, 4), 'No strides', (), ()]
Inputs values: ['not shown', 'not shown', 'not shown', <capsule object NULL at 0x7fe997e2f7e0>, 1.0, 0.0]
Outputs clients: [[GpuElemwise{Composite{(i0 * ((i1 + i2) + Abs((i1 + i2))))}}[(0, 1)]<gpuarray>(GpuArrayConstant{[[[[ 0.5]]]]}, GpuDnnConv{algo='small', inplace=True, num_groups=1}.0, InplaceGpuDimShuffle{x,0,x,x}.0)]]
Backtrace when the node is created(use Theano flag traceback.limit=N to make it longer):
File "vgg16.py", line 127, in create
self.ConvBlock(2, 64)
File "vgg16.py", line 100, in ConvBlock
model.add(Convolution2D(filters, 3, 3, activation='relu'))
File "/home/bnrc/.conda/envs/DL-Py2/lib/python2.7/site-packages/keras/models.py", line 312, in add
output_tensor = layer(self.outputs[0])
File "/home/bnrc/.conda/envs/DL-Py2/lib/python2.7/site-packages/keras/engine/topology.py", line 514, in __call__
self.add_inbound_node(inbound_layers, node_indices, tensor_indices)
File "/home/bnrc/.conda/envs/DL-Py2/lib/python2.7/site-packages/keras/engine/topology.py", line 572, in add_inbound_node
Node.create_node(self, inbound_layers, node_indices, tensor_indices)
File "/home/bnrc/.conda/envs/DL-Py2/lib/python2.7/site-packages/keras/engine/topology.py", line 149, in create_node
output_tensors = to_list(outbound_layer.call(input_tensors[0], mask=input_masks[0]))
File "/home/bnrc/.conda/envs/DL-Py2/lib/python2.7/site-packages/keras/layers/convolutional.py", line 466, in call
filter_shape=self.W_shape)
File "/home/bnrc/.conda/envs/DL-Py2/lib/python2.7/site-packages/keras/backend/theano_backend.py", line 1307, in conv2d
filter_shape=filter_shape)
HINT: Use the Theano flag 'exception_verbosity=high' for a debugprint and storage map footprint of this apply node.
Can someone help me?Please! Thx so much!
I am facing the same problem. Can anyone please help me.
Can someone explain the following to me?
In the first lesson, after unfreezing the layers, 3 learning rates are used for training the earlier layers.
learn.unfreeze()
lr=np.array([1e-4,1e-3,1e-2])
learn.fit(lr, 3, cycle_len=1, cycle_mult=2)
Notes from the notebook:
“…The first few layers will be at 1e-4, the middle layers at 1e-3, and our FC layers we’ll leave at 1e-2 as before.”
But the resnet model has so many layers. Then how these 3 rates are distributed among these layers? How first few layers are decided for using learning rate 1e-4?
Is there any reason of doing this course now when we have new edition?
There are some things covered in v1 that are not covered in v2, some receive different treatment, etc. It’s all very valuable information delivered in a really nice way but under nearly all circumstances I can imagine, there is no reason to start with v1 now that we have v2.
v2 + the machine learning course is a great combination imho
1 Like
how to find keras.json file
You will find it in c:\users<username>.keras\keras.json
I have an image data set where each image has two labels namely vowels and consonants , can anyone help me how can i use ImageDataBunch to load such kind of data.
I was able to get 95% accuracy on Banglalekha dataset to recognize Bengali characters using resnet34.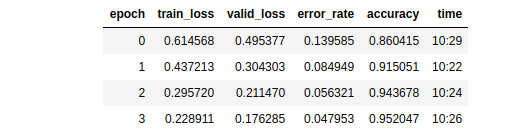
The state of the art is 99%.