Hi,
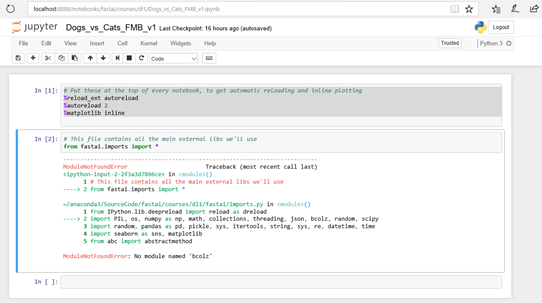
I cloned fastai in my computer using:
$ git clone https://github.com/fastai/fastai.git
However, when I run it on my CPU, I receive the following message:
ModuleNotFoundError: No module named 'bcolz’
Regards,
Faris
Hi,
I cloned fastai in my computer using:
$ git clone https://github.com/fastai/fastai.git
However, when I run it on my CPU, I receive the following message:
ModuleNotFoundError: No module named 'bcolz’
Regards,
Faris
Probably you are missing dependencies required for this course. You can go inside the fastai folder top level and run the following command ‘pip install -r requirements.txt’. This will install dependencies.
If you are running this for the first time then you also need to install torch. Check pytorch.org and use the installation command according to your system configuration
Please do pip install bcolz in your system. Best would be to create the environment in your conda. In the fastai parent folder please look for enviornment.yml. If you anaconda installed then do conda env create -f environment.yml
hi
i was wondering ,why this was used ,could anyone please explain me the intuition behind this step
[Crestle has the datasets required for fast.ai in /datasets, so we’ll create symlinks to the data we want for this competition. (NB: we can’t write to /datasets, but we need a place to store temporary files, so we create our own writable directory to put the symlinks in, and we also take advantage of Crestle’s /cache/ faster temporary storage space.)]
Running the notebooks on your own computer is an advanced topic. I’d suggest avoiding it if at all possible. If you need to do so, please discuss this on Part 1 (2018) , rather than on the beginner forum.
Can you explain what you’re asking about here? Which bit is unclear?
actually @jeremy i need to know about the functionality of this part of the code which is mention below
os.makedirs(‘data/dogscats/models’, exist_ok=True)
!ln -s /datasets/fast.ai/dogscats/train {PATH}
!ln -s /datasets/fast.ai/dogscats/test {PATH}
!ln -s /datasets/fast.ai/dogscats/valid {PATH}
os.makedirs(’/cache/tmp’, exist_ok=True)
!ln -fs /cache/tmp {PATH}
because i’m new to the concept of symlinks
thanks in advance
Thanks Jeremy for your reply, i will start running the scripts remotely at least for part 1.
In Lesson 1, cell ( In [5] ), what does the statement sz=224 mean?
If you’re running on Crestle, you need to run that code, because Crestle already has the data downloaded for you. The details don’t matter at all - it’s just a little technical detail for this particular platform. If you’re interested in learning more, you could read Create a symbolic link in Unix
It sets a variable called sz equal to the value 224. Later on in the notebook we’ll use that variable to define the size of the images passed to the model.
thank you @jeremy. ,
Thank you Jeremy.
@adilansari you have last year’s version there! Make sure you use the part2 AMI, which has the new version installed.
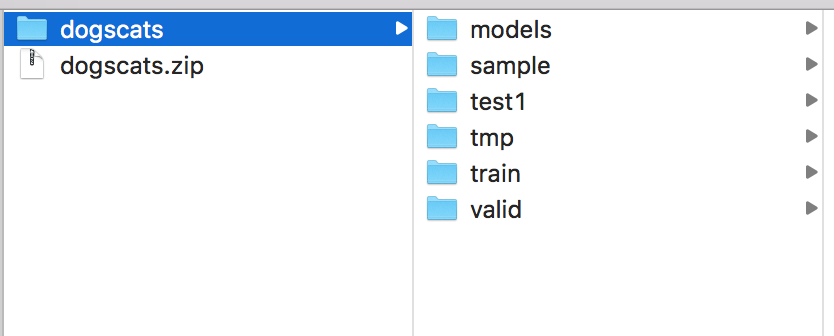
What do the various folders mean - specifically valid and train ? and how do i use them say to set up an example differentiating hotdogs and hamburgers
my attempt at understanding is that the model picks some training data , then runs them … and then runs this new trained model against the valid folder …Once it has a perfect model then it runs the Test to see if this is correct or false
Is this a good assumption / understanding
train - Images in this folder is used for Training the Learner (Updating weights to minimize Training loss based on images in train folder)
valid - On each Epoch the learn.fit(), generates prediction and tells you how much error the model has. This is what you are looking for to understand if the model will generalize.
test - Images in this folder are never seen by the model until the final run or when you use learn.TTA(is_test=True)
sample - Jeremy likes to run the models on a sample of images to do a sanity check and also see if the model is able to learn (train). Sometimes you only need a sample of images to get good results.
models - Probably has the saved weights - please double check
tmp - I am not sure of all the scenarios that it’s used for. I think it’s used when you set precompute=True to save the frozen layer output so the custom layers can be trained quickly to get to a reasonable place before you start to unfreeze layers of pre-trained network.
My current understanding. I have not dig deep into models or tmp directory. Hope this is useful.
train folder contains labeled data (i.e. you know the correct answers for them) for training.valid folder contains labeled data that is used after every epoch to see how good your model is. These images are not used for actual training and becomes important when you check for over-fitting/under-fitting etc.test folder contains un-labeled data (i.e. you don’t know the correct answers) which you make predictions against to submit to competitions like Kaggles.Ha. @ramesh beat me to it 
This is exactly right! ![]()