Thx, so this has a language model or it a good way to make translations without RNNs?
the breakthrough in this paper is that it is not a RNN. RNNs takes a long time to train and have issues with translating long sentences. I have been training RNNs where it tok 15 hour to process 10 epochs on 2.5e8 tokens. The awd_lstm rrn in fastai is very interesting as a model it just requires a lot of patience to train
The same perplexity/accuracy can be reached in about an hour using the transformerXL @sgugger implemented recently. it handles long sentences much more elegantly (attention mechanism) and can be parallelized.
In short - if you want to train languagemodels for translation or classification etc. you will do it faster an better using the transformerXL model.
If you manage to do that, please tell me how. Those models are heavy and require a much longer time to train! Those it’s true it takes less epochs to reach a ppl as low as the AWD-LSTM on WT103, it still takes more compute time.
thx @Kaspar got it ! I will take a look at it then for a pet project I want to do.
I am still looking for simple example code (afaict there are no examples in fast.ai notebooks) how to use a language model for translations, I just saw fast.ai examples from last term part II (lesson 11) using word vecs. @sgugger
I have see this phenomenon several times when training TransformerlXL. Do you @sgugger have any idea what is going on?
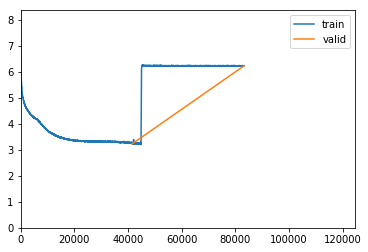
That would suggest a too high learning rate since it just breaks.
ok but to be more precise why does it occure “between” 2 epochs ?
Why would it occur at a specific time? I’m confused about what you’re asking.
Do you mean that you get the crash when epoch starts again?
Does it do that each time?
Interesting idea to use language modeling to do transfer learning to machine translation task.
Some ppl tried that with BERT and they failed. BERT model for Machine Translation · Issue #31 · huggingface/transformers · GitHub
There are other concepts like back translation that let you use large monolingual texts in MT, and we know that they are working well. Check http://nlpprogress.com/ Sebastian is listing there the recent approaches to MT.
thx for this link @piotr.czapla!
Reducing the learning rate to 1e-4 gets the training back in control. However i have seen this jump in training loss more frequently between epochs than inside an epoch. That makes me wonder whether the state of the network/buffers are restored correctly between validation / training.
just a heads up concerning TransformerXL. although i have not made an exhaustive hyperparameter search it does look like a slow start (pct_start) accelerates ceonvergence - by a lot
%time learn.fit_one_cycle(cyc_len=epochs, max_lr=5e-4, moms=(0.95,0.85), wd=1e-3, pct_start=0.01)
I’m about to start something for Italian since the assigned user has been inactive since last June, so I’m here asking: is the first post updated, with all the good tips working for the latest fastai version, or should I use some old version to make it work smoothly?
Hi,
I’m currently working on a dataset which is tabular in nature. It contains categories of 7 emotions.
Given Data:
id, sentence, emotion
target:
id, emotion.
I want to use ULMFit to analyse this tabular dataset, and predict the sentiment of ids given based on the sentence for that corresponding id.
i’m confused as to how do i proceed after reading the csv file
hey all,
i trained the model in Hebrew Wikipedia.
https://github.com/hanan9m/hebrew_ULMFiT](https://github.com/hanan9m/hebrew_ULMFiT
can u update the status?
and should i just open new New Topic?
interested in this as well. Have been thinking about it for ages
The Italian models are done in an effort of comparing ULMFiT against BERT, I need to find some time to move the modifications to fastai but for the time being the models can be found here: https://drive.google.com/drive/u/0/folders/1t3DqH0ZJC2gDMKEq9vTa5jqxBiVAnClR
They are working with GitHub - n-waves/multifit: The code to reproduce results from paper "MultiFiT: Efficient Multi-lingual Language Model Fine-tuning" https://arxiv.org/abs/1909.04761
I would love to see how it works on other Italian datasets than MLDoc.
Please open the thread. Hebrew is not tackle yet as far as I know. Have you found a suitable dataset to test ULMFiT against?
@miko, @DavideBoschetto, we have trained 2 Italian language models and one classification model on MLDoc. Having that set there are still some things that would be helpful to experiment with.
- test the current models on other datasets than MLDoc - it would be best if you would add such dataset in the same way as we added mldoc and cls to the ulmfit-multilingual.
- search some better hyperparameters for Italian. We tested only 3 models in a rather standard way maybe you find a better set of hyperparameters.
@piotr.czapla
hey, actually i just broke record of some banchmark that realease last yaer (in almost 2%!!). I’m in touch now with the auther to validate my results.
i open a thread ULMFiT - Hebrew
‘nvidia-smi dmon’ and ‘nvidia-smi pmon’ commands could also be helpful.