Yes and thanks to Jeremy’s suggestion I finally got the 1st run of the Chinese language model through. It’s still converging so I’ll update again once it stops  I’m sharing my pain here and all of this could have been avoided if I had asked Jeremy earlier about the optimal # of tokens
I’m sharing my pain here and all of this could have been avoided if I had asked Jeremy earlier about the optimal # of tokens 
I had 32GB of RAM and 400M tokens. Initially I tried to copy the files and follow the lecture notes, but it was painfully long on my 1T HDD, so I took Jeremy’s advice and loaded everything in dataframe instead. The steps were recorded here for folks who can’t use SSD right now.
After that I ran into RAM issue, I couldn’t load all the text using get_all. The process seemed still running but when I checked htop, it looked like this:
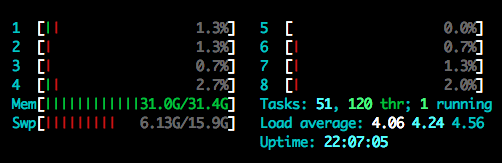
The swap quickly got maxed out and basically it would just hang their forever in the Jupyter notebook. I then ran it as a script and it threw an error eventually.
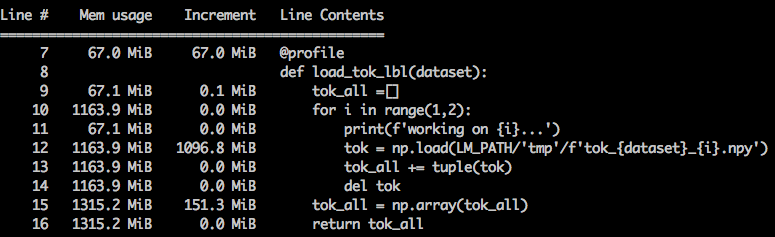
So, I had to modify the tokenization step from lecture notes to make it save the .npy file for every batch. I thought it solved the problem and it would be just easy to append them into a big list, but my last file maxed out my RAM. I tried to use a tuple instead of a list of a list to reduce the memory overhead, and it improved speed (quite surprisingly although no benchmark data), but didn’t help with loading my last file. I took this as an opportunity to dig deeper into the issue, and found the python memory_profiler very helpful. The following screenshot showed that the .npy file took almost 1GB of RAM whereas it was only 180MB on the disk!!!
I was going to search for a more memory-efficient method in Python, but then decided to first train on 100M tokens, which still had ~35k unique tokens. I used StratifiedShuffleSplit on my dataframe since the corpus I used has 14 imbalanced news classes. I’d imagine using lecture notes on my data would not give a good validation set since it’s for 2 balanced imdb classes. Many people are using wikipedia corpus and I imagine they won’t have such a problem. I’ll report back once my first big run is done. Right now my val_loss is at 4.47 (accuracy 0.299) for epoch 12 (took almost 48 hrs).