Even I am working on replicating the planet classification challenge on Google Landmark Recognition Challenge (will use softmax instead of sigmoid) on Kaggle. It fails at the get_data(sz = batch_size) step even for a batchsize of 16. Fills up all the RAM and crashes(then restarts) the notebook. Is there a way to lazily load a batch at a time? The dataset is about 336 Gb large and I am working with 56 GB RAM + K80 graphics on Azure’s NC6 VM.
It’s possible that ThreadPoolExecutor is being used elsewhere too. I faced the issue in lesson1.ipynb. I used tracemalloc to drill down to the exact location that was allocating memory. It was the np_collate() function which was being called by thread pool executer’s run() function. In my case it was happening when creating batches and saving them. It’s very likely that the same is happening when loading the batches for training.
Farhan’s fix works in my case, but the training time increases by many folds. It will be really helpful if someone could fix this issue.
I think there are two seperate issues here. Farhan’s workaround is for issue 184 which manifests in DataLoader.
I believe the issue I’m experiencing with the Landmark dataset is the same one Bart and Deepak reported (at least all symptoms are same). It manifest before DataLoader is used. I’ve pinpointed it to
dataset.py:138 in the label handling and am looking to fix it.
Submitted a PR that should buy us 4 times more training data. Still not enough so let me know if you can think of a more complete fix!
I did a temporary for the ThreadPoolExecutor problem, while keeping multithreading.
I just copied the _DataLoaderIter object from pytorch and added a few lines. I hope that a better solution can be found soon.
Did anybody find out why python changed this behavior?
Here the link to the fix: dataloader.py and dataloaderiter.py
Cheers, Johannes
2 Likes
I’m seeing similar issue when trying to run the Quick Dogs vs.Cats notebook. The kernel just dies when I run the following line of code:
learn = ConvLearner.pretrained(resnet50,data)
Hey William,
The same thing happened to me. I am using paperspace and when I try to do the last step TTA for bs = 256, it always died.
Have you fixed the problem?
Yeah, I know. Making predictions seems surprisingly memory intensive :-/. I haven’t had an in depth look at it. There might well be an easy mitigation like the one in the PR above. I have only worked around the issue by predicting in smaller batches. Which is a pain.
Yea. During validation, my kernel jus dies, there are around 20000 images of 1mb each, might be causing the problem. Any idea how do I stop the kernel from dying during validation? Running GPU+ instance on paperspace (8gb vRAM with 30gb ram)
Farhan’s fix worked for me — thanks Farhan!
My dataset is ~190k images from this competition: https://www.kaggle.com/c/imaterialist-challenge-furniture-2018. I resized my images to 500px using data.resize(). These temporary images consume < 20 GB on my disk.
Before Farhan’s fix:
With ConvLearner.pretrained (resnet34), GPU memory usage was 30%, (batch size 48), but all 32 GB of RAM was eaten up and virtual memory usage grew to 80 GB before the Kernel crashed.
After Farhan’s fix:
With ConvLearner.pretrained (resnet34), GPU memory continues to remain 30%, (batch size 48), but only 3 GB of RAM is used and virtual memory is at a steady 20 GB (no Kernel crashes).
Currently attempting your fix and it seems to run like a charm…
Just checked with the fastai repo, so right now when using 0 workers it will not load all into memory, but if you try multi threading it will. If the fix works I could submit a pull request @jeremy
cheers Johannes
Okay so it was zipping along fine during training and seemed to make use of multiple threads while not keeping every batch in memory, but then failed at the end of the learn.fit() call with the following err:
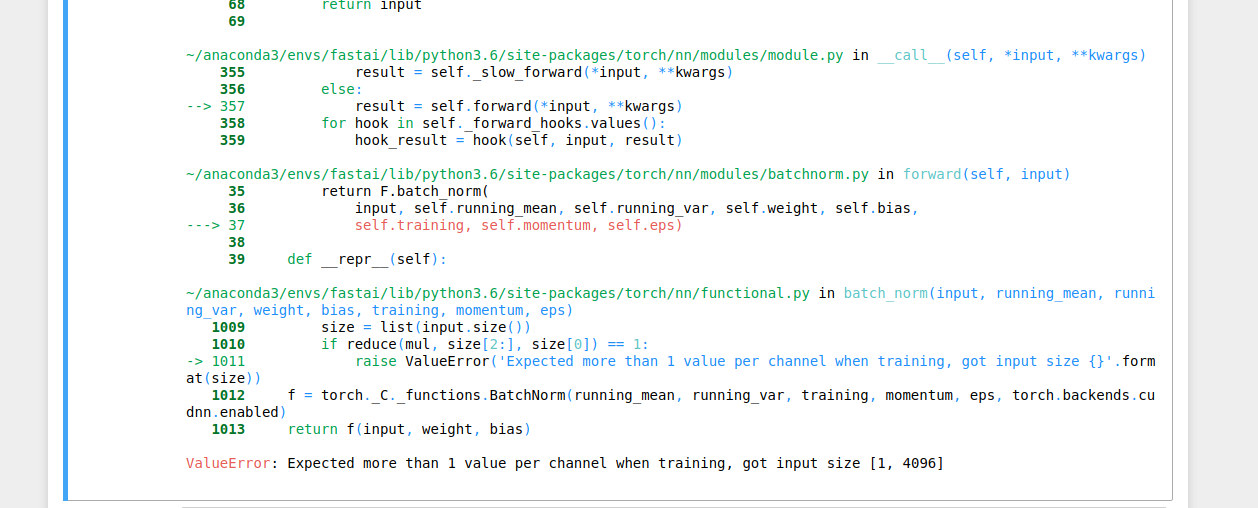
Hmm, can you share a full stack trace or provide a minimal code example that fails. I will try to fix it later.
cheers, Johannes
Nevermind Johannes, looks like this was unrelated! Apologies. Will update later if I run into any troubles!
@j.laute 's fix worked for me as well - cheers, well done. Would support this being PRed into master
1 Like
Hi there,
I’ve been facing the same issue too!
So, I’ve tried to do the TTA separately for ‘test-jpg’ and ‘test-jpg-additional’ folders. Created separate result csv’s and finally merged them using
‘result = pd.concat([test_df, addn_df])’
And it worked.
Hope this solves for you too.
(Just be watchful of the filenames while creating addn_df and ‘index=False’ during .to_csv())
Thanks for the advice, I will look into it!