If that happens, I won’t post it here. You are my guru (obviously after Jeremy)
Go for it - if you beat me , make sure to go to the top. I won’t feel bad.
1 Like
QQ: if loss started jumping up and down both for train and valid thats mean something wrong with architecture (dropout, num of FC layers, nodes in layers) or I need to wait? Lower loss does not learn anything.
Is your loss goes down smoothly or it goes up as it was 3 epochs ago and than get even better? And how valid loss relates to train loss? Mine become equal after 4 iterations and than I start overfitting but with improvement on valid set as well.
@shubham24 I am able to get your code to work once I figured out how to properly install GLOB2. Thank you.
1 Like
I would say this depends on how you have set your cycle_len and cycle_mult. For example, if you have cycle_len=1 and cycle_mult=2 then there is a typical pattern is as follows:
Cycle_0 = Higher or Avg Loss
Cycle_1 Part 1 = Higher or Avg Loss
Cycle_1 Part 2 = Lower Loss
Cycle_2 Part 1 = Higher or Avg Loss (usually this one ends up the highest loss for me)
Cycle_2 Part 2 = Lower Loss
Cycle_2 Part 3 = Even Lower Loss
Cycle_2 Part 4 = Lowest Loss
So in other words if you are using SGDR then its actual quite “normal” for the loss rates to be fluctuating since the learning rate is being adjusted higher than gradually lower, so I have found the loss rates should usually follow this general pattern.
Also if you see validation loss is still decreasing and doesn’t appear to be “stalled” or increasing at the end of each cycle then you should probably repeat the whole process another time to see if it further improves! This is regardless of the training loss cause remember that could very well change quite a bit for each cycle with SGDR.
8 Likes
After reading the various discussion about learning rates, I did a revision for it by running my existing notebooks. I got better results for the models. 
However, I got different shapes after I ran learn.TTA. The log_preds.shape became:
(5, “no. of images in test folder”, “no. of possible classifications”)
What does the “5” mean? And, how can I fix it?

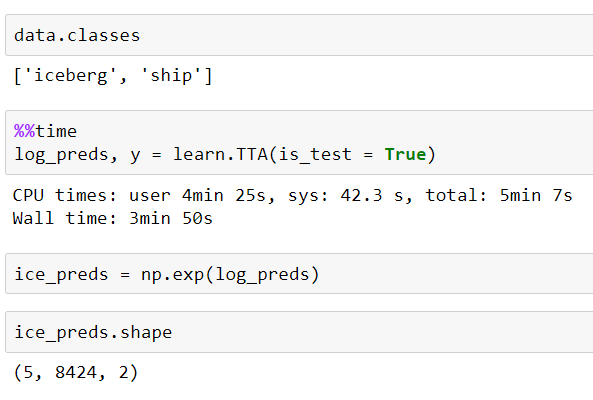
@Moody, can you check learn.data.classes and tell us what shape returns learn.TTA(is_test=False) ? 
UPDT after Jeremy`s post below. What I wrote does not make sense anymore. TTA now returns class probability for each n_aug so you need to:
log_preds,y = learn.TTA()
preds = np.mean(np.exp(log_preds),0)
2 Likes
Sorry - I made a change to TTA a few days ago! ![]() Search this forum for details and why it was necessary.
Search this forum for details and why it was necessary.
1 Like
Thank you for explaining the mystery. I found the discussion.
I subscribed the updates from Github by pressing the “watch button”. So, I know what is coming. But, I may not necessarily understand all the implications.

1 Like


Question to @jeremy:
It seems like 2/3, or more, of the Top 20 scores today in Plant Seedlings are using Fastai PyTorch library, some having found a more effective “secret sauce” than others (like me as #19: “what am I missing ?”).
I’d be interested to discuss and learn from those performing better as part of the studying process of Part 1 v2: how can we do that while respecting the spirit of Kaggle competitions, taking this example as a case study for later references ?
Challenging competitions like Cdiscount or DHS-Passenger Screening Algorithm, both ending within 14 days, being another example for case studies.
2 Likes
There may be more insightful answers than mine - but as someone who is in #3 position for 4 days - the secret sauce is to know the optimum number of iterations for different size of data inputs . I believe Jeremy has already shown it in multiple notebooks, its not that much of a secret. Another technique might be to use ensemble of different models, which is of course quite general, now-a-days.
3 Likes
I did nothing of that so far. My error was not taking into account TTA factor that might change accuracy score from 0.95 in logs vs 0.97 with TTA n_aug= 4, 6, 8 …
I wish I could tell you I found a special way to get to top 10. I basically used resnet50, trained with size 128, top_down Augmentation then changed size to 256. Ran it for a few times (took about 3 hours). Then created a submission file based on TTA.
Currently our Pre-Trained Model Flattens and adds Fully Connected(Linear) Layers at the end. My question is when we change sizes, we aren’t taking advantage of all the Linear Layers and need to re-train from scratch. I would like to know how to build a Fully Convolution Layer with fastai. Is there some parameter to pretrained to ask for fully convolution layer?
3 Likes
You guys and gals, with your “I just implemented the notebook, nothing else”:
I hate you and I love you.
All in the same sentence.
E.
7 Likes
I totally hear you. I had lots of false starts. The final version of the notebook took 3 hours, but I spent 10 hours earlier and ended up overfitting or underfitting as I move between Sizes and using wds, learning rates, cycles etc.
I think we shouldn’t share this level of detail, just to be totally fair to other competitors not in the course (since this comp doesn’t have prize money or points, it’s not such a bit deal, but I still want to respect those competing). Instead, when the competition is finished, we can all share the juicy details,
3 Likes
On training first time with precompute = true, I get an accuracy of around 0.85 after 5 epochs. But once I try to train all the layers with precompute = False, it seems that the model unlearns everything that it has learnt in the previous step and gives an accuracy of around 0.5. Is there something that I am doing wrong?
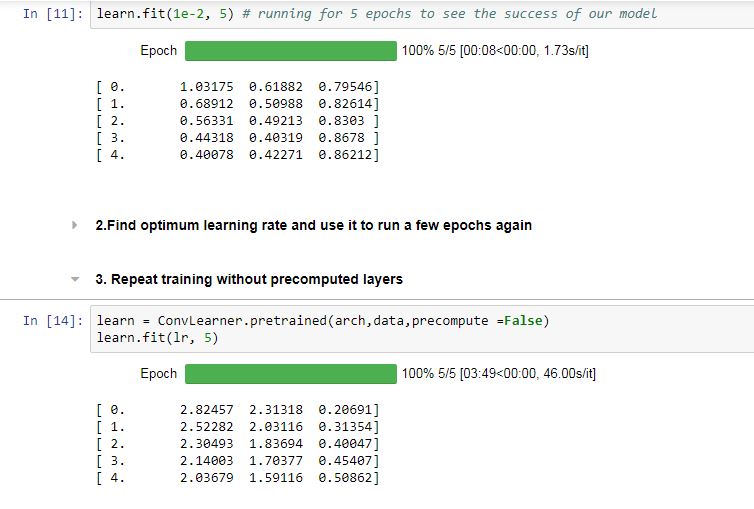
It’s like you create absolutely new model and train it from scratch. Take a look at lessons notebook, you need to call learn.precompute = false or learn.unfreeze()
Hmm…was that in lesson 1 notebook? A lot of my code is based on that…I will look into it… thanks.
Also, is there any way to remove the verbose version of the training version, which displays the loading times of all the training steps, and just display the final output.