Whats color augmentation on an image?
I have the similar problem of TTA in other notebooks as well.
In the meantime, you can compare your file against the sample submission file to identify which item is missing. Copy it across and make a submission.
1 Like
Is anyone able to provide a minimal test example to help us identify and fix this?
I have the same issue:
I checked all files have the .png in the directory as well.
And the same issue with the planet dataset: 61190 predictions on a sample of 61191. The code is more or less identical so that would explain why the issue for me in both cases. Not sure why though.

Hi Jeremy, does looking at the code help. Here is what i am using:
I have also deleted the tmp folder and re-started aws just to be sure but still getting the same issue.
Hi @amritv, thanks for sharing your code. Next time, you can press the Gist share button (the yellow highlighted one). It will generate a link for your Jupyter notebook. So, Jeremy can replicate the problem quickly.
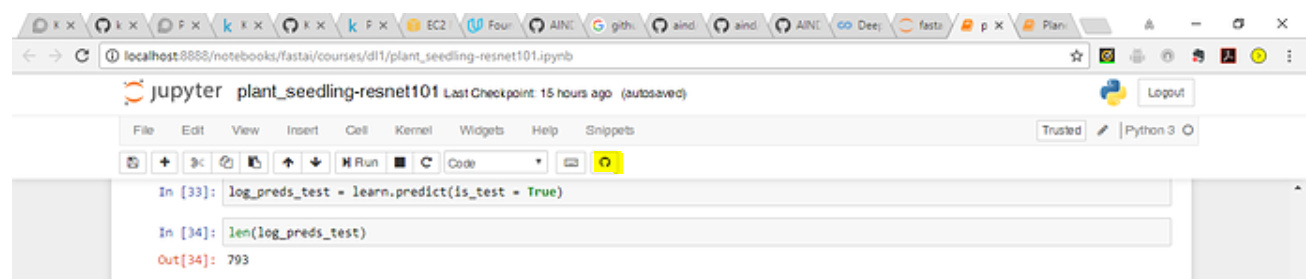
1 Like
Hi Jeremy. Here is my minimal test replicating the issue when I run the learn.TTA() function. It seems that there is a mismatch between the counts only when the is_test=True argument is passed to learn.TTA(). There is no issue when its used with the validation set as it returns the correct shape.
Thanks for those of you looking into this. Since I’m busy getting the new course up and running, it might be hard for me to debug this right now - but it would be a great little exercise if one of you want to try to figure out what’s going wrong, and how to fix it! Ideally, send in a PR with the fix, or else just let us know here what you find.
Hey Amrit,
I didn’t run the exact same notebook but mine is almost similar in flow.
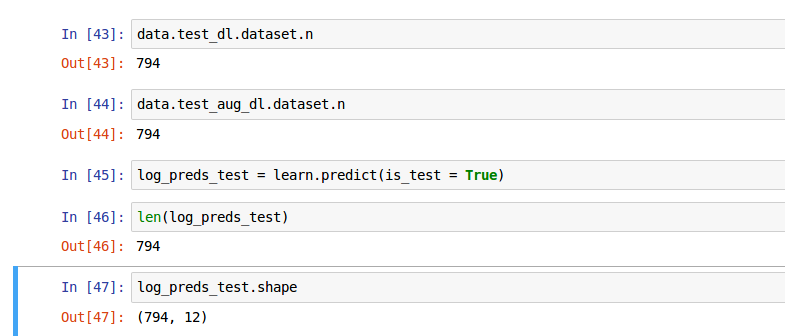
I printed the following details and predictions and it seems that TTA is working fine with is_test=True for me.
I also checked the learner.py for TTA definition and its simply pulling data.test_dl or data.test_aug_dl and calculating predict_with_targs on same. I’ll try and run your notebook if I am not able to figure out the difference.
In the meantime, my suggestion is to look at data.test_dl.dataset.n before you run your learn.predict. If the output shape is still not as expected then go ahead and lookup TTA definition in learner.py and find edge cases for predict_with_targs.
Hope it helps.
1 Like
@PranY really appreciate your insights, I re-ran my notebook and primarily got the same results and will let you know about your second suggestion…
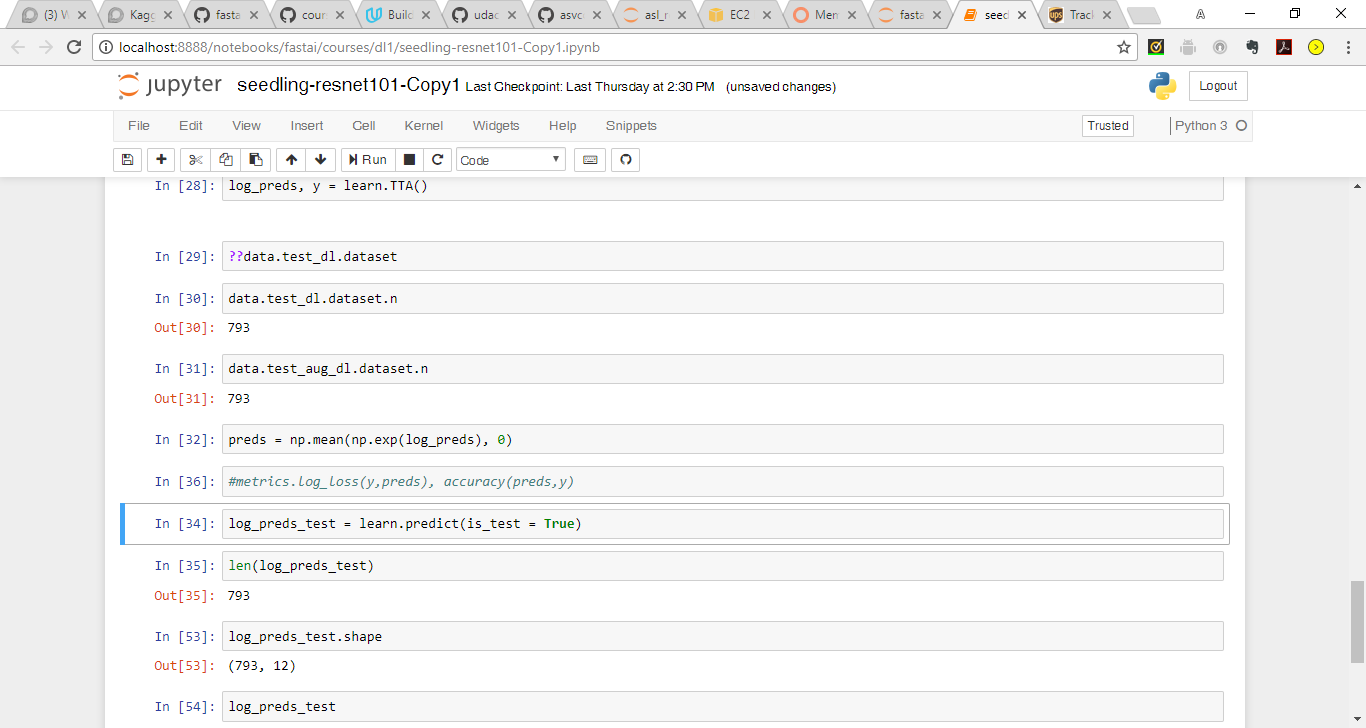
@amritv I can see your data.test_dl.dataset.n is itself 793. I strongly believe the learn or TTA step is not related to this problem. The source for data is the “ImageClassifierData.from_csv” method which revolves around your train/test folders, label.csv and val indexes. Since your word count for train/test is right, my best guess is that the part where you are creating val indexes using n, relies upon an assumption that your labels does include the titles ‘id’ and ‘species’. If thats not the case then the source method will inherently pull 1 less record. Please print “data.trn_dl.dataset.n + data.val_dl.dataset.n” and that should match with your word count for train folder which is 4750. If it doesn’t I think we found the root cause.
Please revert back if this helps.
3 Likes
@PranY Firstly, your insights are really helping me dig deeper into the fastai code and get a more better understanding of what is happening under the hood. I ran data.trn_dl.dataset.n + data.val_dl.dataset.n and the total count is the same as the train folder 4750.
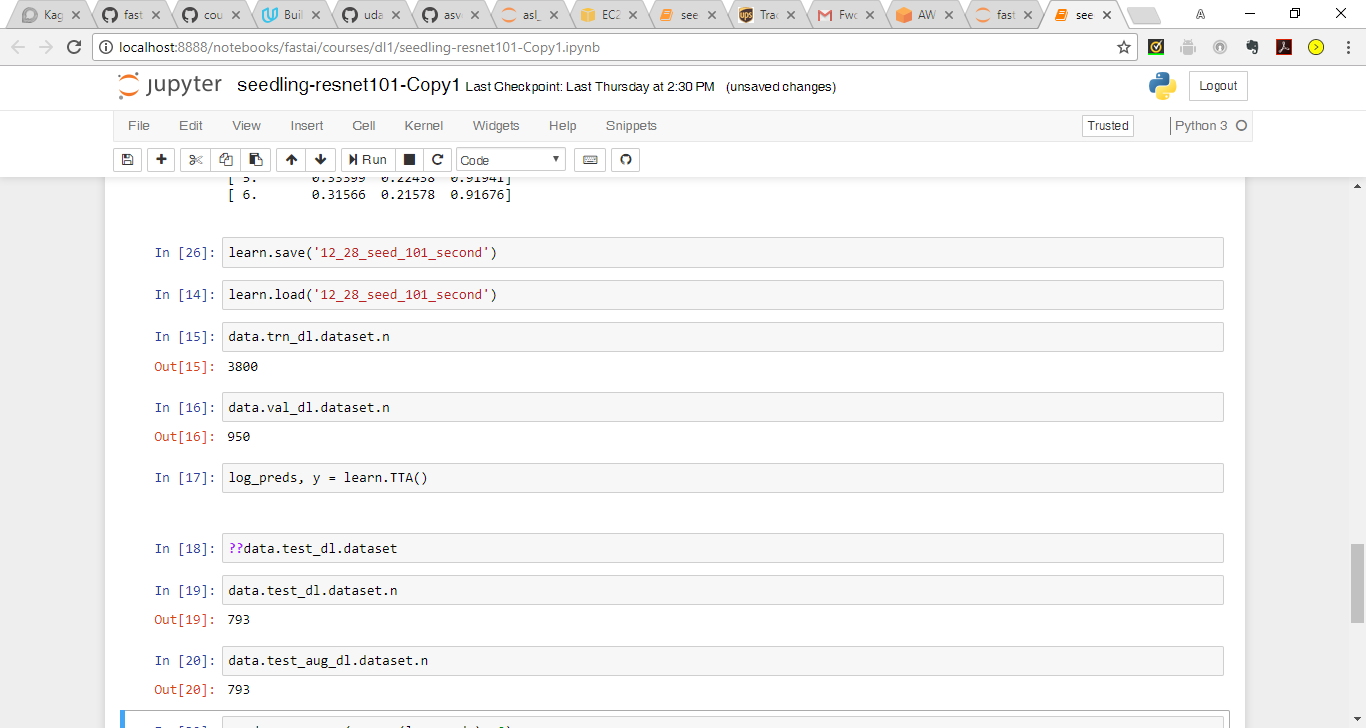
I wanted to get a better understanding of what is happening here:
labels_csv = f'{path}labels.csv'
n = len(list(open(labels_csv)))-1
val_idxs = get_cv_idxs(n)n= 4750
labels_csv = 24 (where does this number come from - 12 classes and 2 columns?)
len of val_idxs is 950 (where does this number come from?)
Thanks,
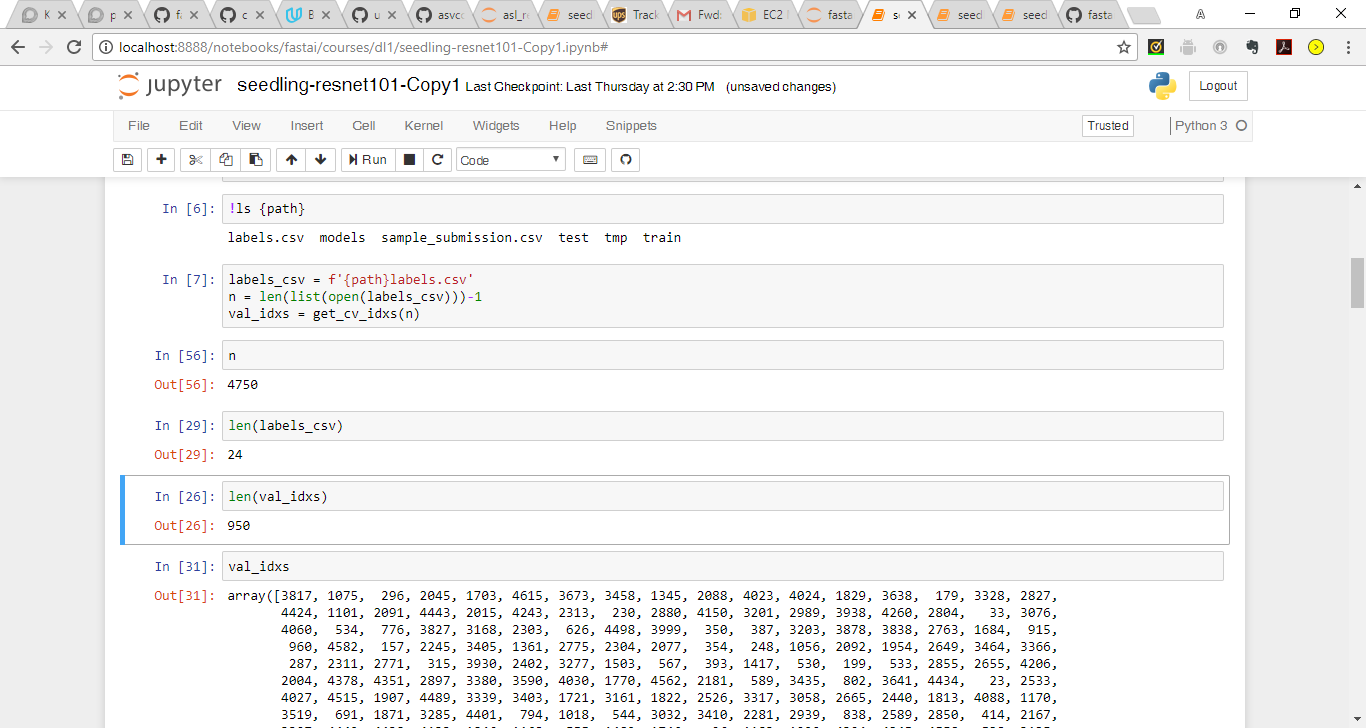
Here n is the length of (labels_csv-1) i.e minus the header. val_idxs is 20% of n.
I am facing the same issue while doing TTA and am not able to create a submission file. Were you able to fix the error, if so how? I checked ‘data.trn_dl.dataset.n + data.val_dl.dataset.n’ according to @PranY and it is the same as train folder i.e 4750.
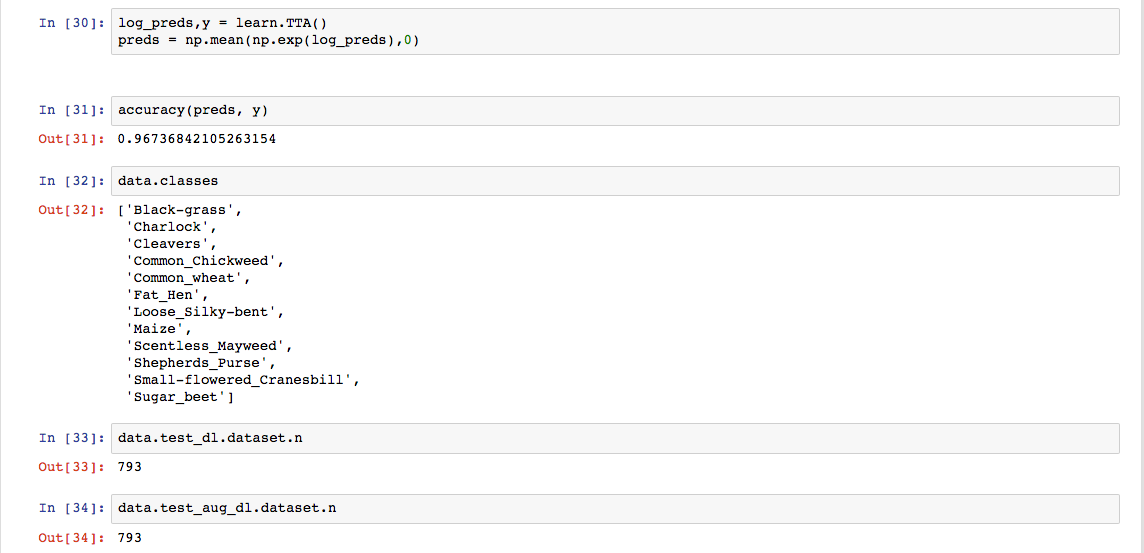
Unfortunately not but was able to generate a submission. I also started from scratch and reviewed learner and dataset.py, reviewed videos (no solution but learnt alot about the fastai library  )
)
Running this code right at the beginning
data = ImageClassifierData.from_csv(path, 'train', labels_csv, test_name='test', val_idxs=val_idxs, bs=bs, tfms=tfms, skip_header=True, continuous=False)
learn = ConvLearner.pretrained(arch, data, precompute=True)creates the tmp file which as 793 entries instead of 794 hence no need to train the model fully all the way to realize there is a difference in the sizes. The tmp files dont correspond to anything I can reference back to the 794 in the test folder. The meta file provides shape, cbytes and nbytes. Is there any way to know what the data corresponds to in the tmp file?
Seems like you ran into the same problem as I did. I created an issue and pull request to solve the problem. https://github.com/fastai/fastai/issues/77
2 Likes
Thanks for the PR @FabianHertwig! I’ve merged it, but didn’t have time to test it, so if folks here could check it works for both this comp and the existing lessons, that would be much appreciated…
3 Likes
Ran into this problem for the dog breed identification and the pull request fixed everything.