fast.ai Course Forums
Kaggle Comp: Plant Seedlings Classification
Part 1 (2018)
sermakarevich
(sergii makarevych)
December 7, 2017, 5:10pm
180
Thanks, Jeremy.
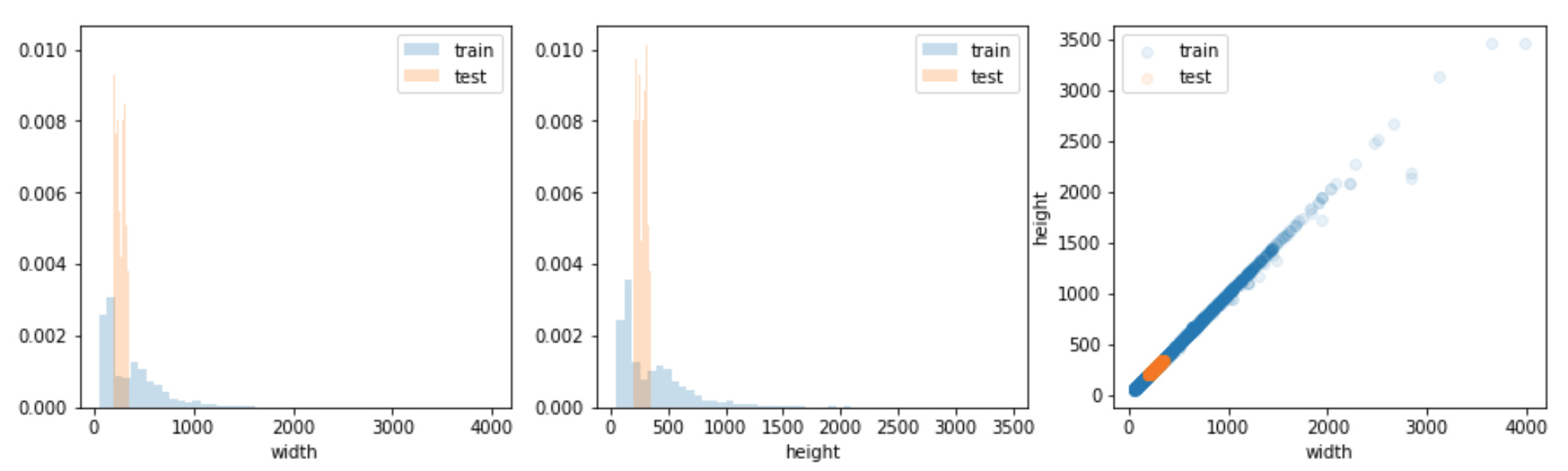
image.jpg
1970×592 94.7 KB
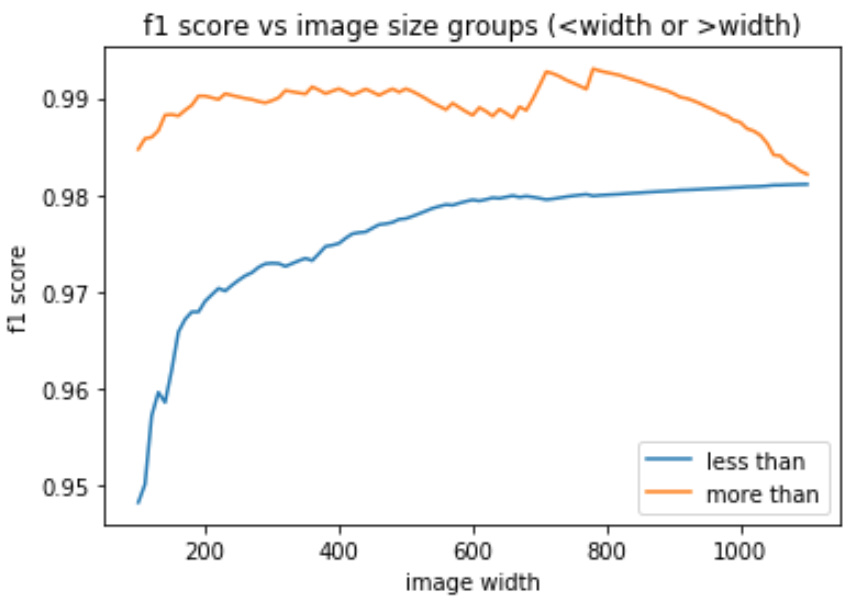
image.jpg
868×608 54.4 KB
14 Likes
Another treat! Early access to Intro To Machine Learning videos
show post in topic