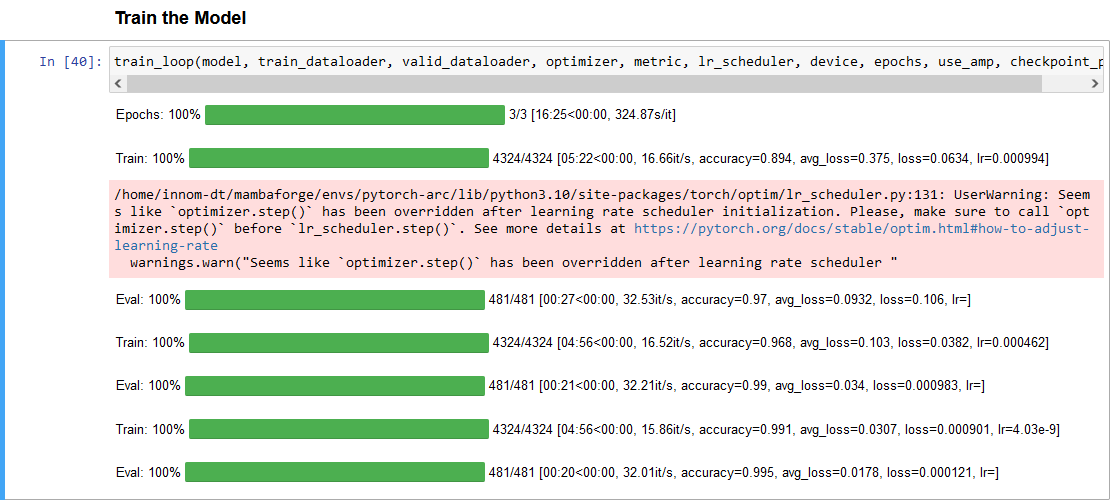
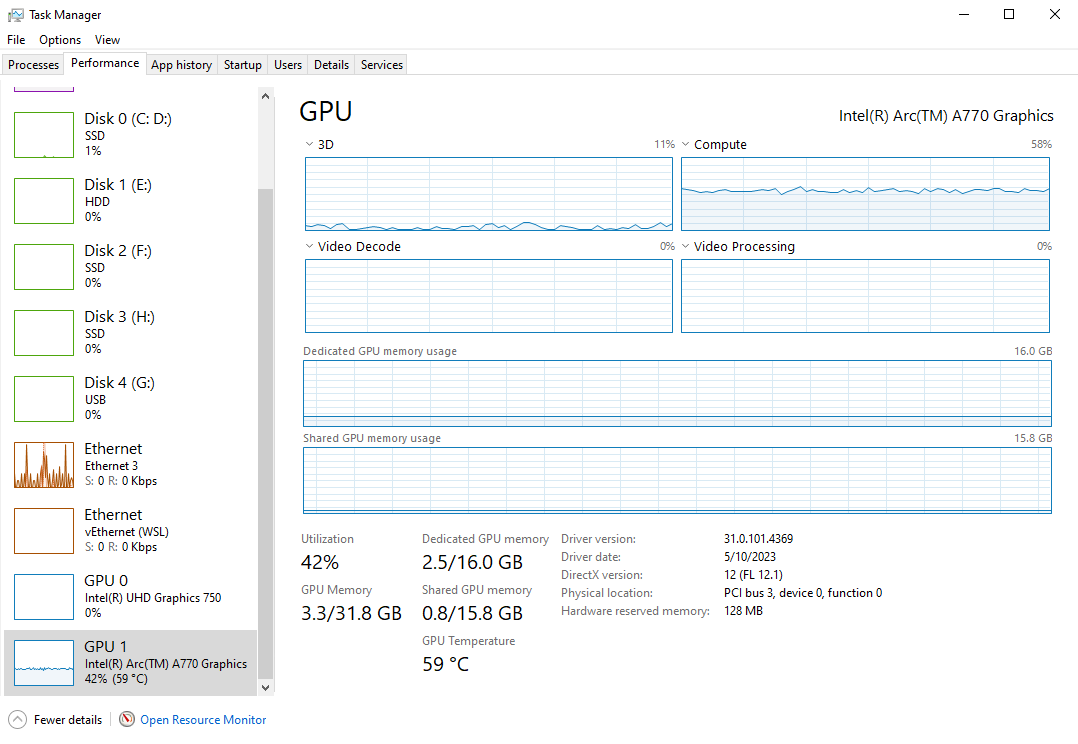
After waiting several months, I decided to give the Arc card another try on Ubuntu with Intel’s PyTorch extension. While the setup and documentation need refinement, I am happy to report it works now! ![]()
I used the training code from my recent beginner PyTorch tutorial for testing.
Initially, the backward pass during training was incredibly slow. The first epoch was nearly twice as slow as the free GPU tier on Google Colab. Fortunately, the fix involved setting a single environment variable.
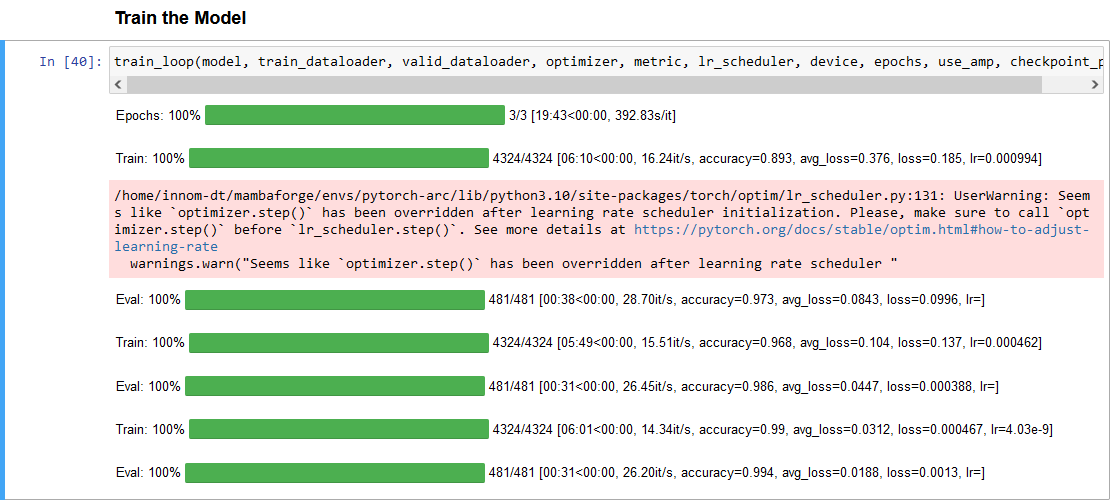
After setting IPEX_XPU_ONEDNN_LAYOUT=1, the total training time is within 10% of my Titan RTX on the same system. The gap would be slightly wider if I compiled the model on the Titan with PyTorch 2.0. Intel’s PyTorch extension is still on PyTorch 1.13.
The final loss and accuracy values fluctuate slightly, even when using fixed seed values for PyTorch, NumPy, and Python. However, they stay pretty close to the results on my Nvidia GPU.
Here is a screenshot of the training session with the Arc A770:
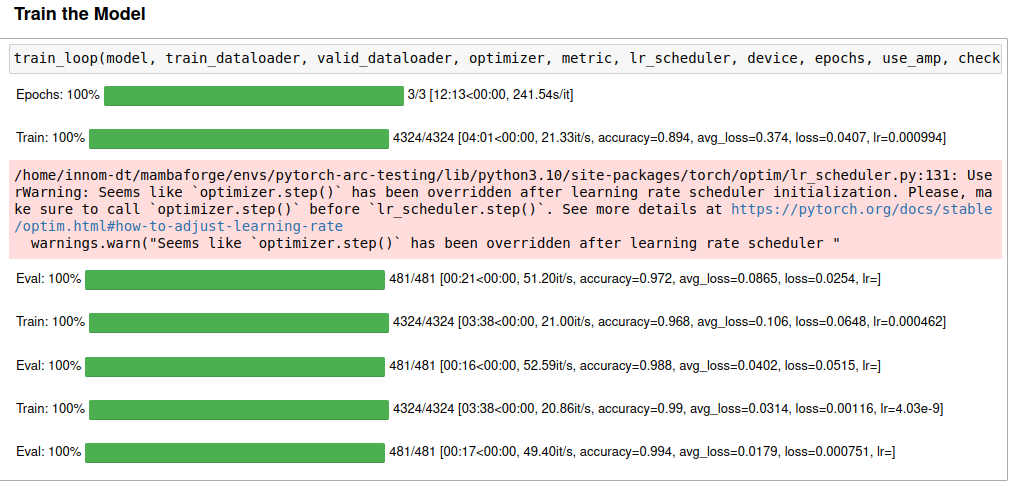
Here is a link to the training session with the Titan RTX
Epochs: 100%|█████████| 3/3 [11:15<00:00, 224.96s/it]
Train: 100%|██████████| 4324/4324 [03:29<00:00, 21.75it/s, accuracy=0.894, avg_loss=0.374, loss=0.0984, lr=0.000994]
Eval: 100%|██████████| 481/481 [00:17<00:00, 50.42it/s, accuracy=0.975, avg_loss=0.081, loss=0.214, lr=]
Train: 100%|██████████| 4324/4324 [03:28<00:00, 22.39it/s, accuracy=0.968, avg_loss=0.105, loss=0.0717, lr=0.000462]
Eval: 100%|██████████| 481/481 [00:16<00:00, 55.14it/s, accuracy=0.988, avg_loss=0.0354, loss=0.02, lr=]
Train: 100%|██████████| 4324/4324 [03:28<00:00, 21.94it/s, accuracy=0.99, avg_loss=0.0315, loss=0.00148, lr=4.03e-9]
Eval: 100%|██████████| 481/481 [00:16<00:00, 53.87it/s, accuracy=0.995, avg_loss=0.0173, loss=0.000331, lr=]
There is much more testing to do, but I think it’s at a point where I feel comfortable making a tutorial for Ubuntu.