I think the consensus last night was we should have read the 5 supporting papers Mast R-CNN builds on first. But I did meet the 2nd place winner of the Kaggle Whale spotting competition! Now he works at a medical imaging company using deep learning! In addition, one other participant introduced himself as “I’m here tonight because I’m interested in combining neural style transfer with object segmentation.” So I laughed at that.
To your question, “what is the bare minimum we need to implement?” I’d say we need to implement just enough to benchmark our results against theirs. And I agree we should do it in PyTorch. I also just found this WIP Tensorflow implementation we can reference.
What’s bare minimum?
To get their best result for image segmentation, we need ResNext-101 with Feature Pyramid Networks (another brand new paper), however they provide benchmarks for Resnet-50 and Resnet-101 that use both FPN or C4 features, so we can cut corners and still have something to benchmark.
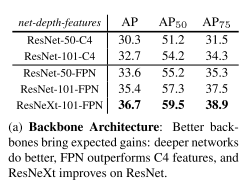
In terms of object detection they actually break it down and analyze the impact of each of the components
The gains of Mask R-CNN over [21] come from using RoIAlign (+1.1 APbb), multitask training (+0.9 APbb), and ResNeXt-101 (+1.6 APbb)
Even though ResNext isn’t introduced this paper, it generates the most improvement ironically.
50 vs 101 Layers
Let’s use 101 since it gives +2.0 AP improvement and shouldn’t be too hard to handle. Pytorch has a nice built in ResNet model with both 50 and 101 layers supported.
ResNet vs ResNext
We can prototype with ResNet and sacrifice +1.3 AP. But later we can try this script which ports the weights AND source code of ResNext from Torch to PyTorch. They report success on porting ResNext.
C4 vs FPN Features
It’s not required, but using FPN features is critical for both accuracy and speed. According to the authors: "We report that ResNet-101-C4 takes ∼400ms (vs ~200ms for FPN) as it has a heavier box head, so we do not recommend using the C4 variant in practice.
RoIAlign
We need to implement this to properly benchmark their result.

That’s all for now. More soon.