Hi @thebenedict, I’m struggling to implement the chargrid myself. I’m pretty much done with chargrid representation itself (though it might need some upgrades too), and now working on the neural network part. Could you perhaps share your code with me? I’m a little stuck and could use some inspiration. Thanks!
1 Like
Hi, sorry that I might not be able to share the code yet because it is not a personal project, but I plan to put in on GitHub someday, but if you want to share about where you stuck, I might be able to give some hints. Thanks 
Thank you @Neeb! I’m stuck at neural network implementation stage. I’m not entirely new to Python and machine learning, but haven’t really built a neural network before. If I understand correctly, I’d need to feed Chargrids to the neural network, and provide annotations to each colored box so that network learns to identify each box as its corresponding letter. I can save each box’s coordinates during Chargrid creation and use them to create annotations. Then, I’d need create larger bounding boxes for each of document element’s, so that the network learns to identify these too, and here I’ll have to get box coordinates manually. I still can’t figure how do I store these coordinates though, and how do I add them to the network itself. I couldn’t really find any examples online, so I’d really appreciate any leads.
Another, less crucial question is whether you found a way to prevent Chargrid boxes from overlapping with each other?
Hi, it’s awesome that you’ve implemented the rossum paper 
Could you please give me a few pointers on how you constructed the neighborhood graph?
It seems they are connecting each side to the opposite side of another wordbox. But I’m still working out how to do that.
Thank you. 
Thanks for your feedback @nkgra! I somehow forgot about tensor layers. Do I understand it correctly that with tensor representation, I won’t need to create any labels / annotations for characters and I’d only need them for document elements? How do I make sure the algorithm decodes character boxes to the corresponding characters?
Hi nkgra,
Not sure that I implemented what the author implies, but from the paper they mention that
“every other box is assigned to an edge of W, that has it in its field of view (being fair 90°) then the closest (center to center Euclidian distance) n neighbours are chosen for that edge.”
So what I did was divide the field of view as below (ignore my ulgy drawing xD)
and then find the edge for every wordbox as image below,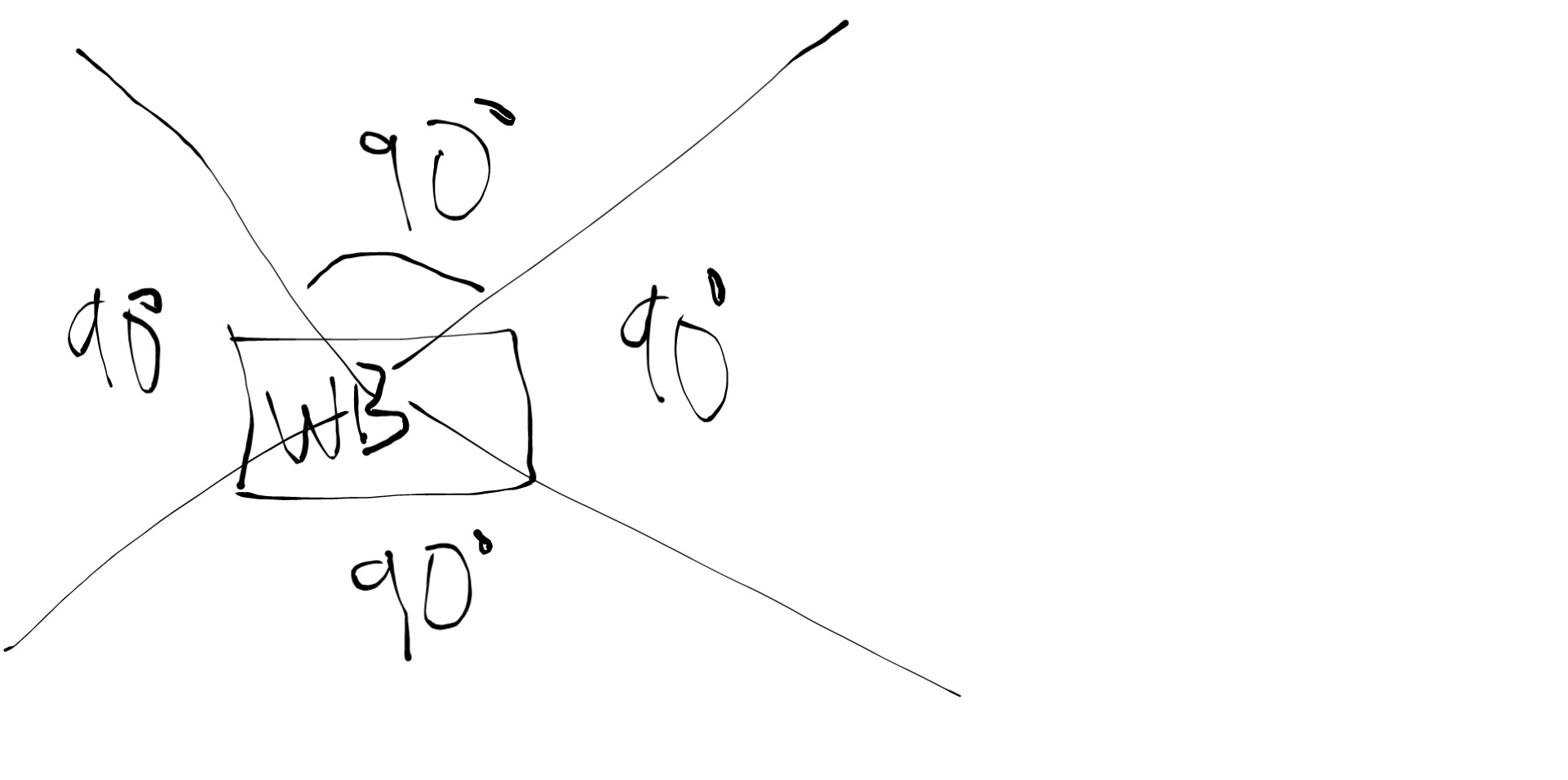
1)bruteforce find every wordbox in this field of view,
2)then calculate their distance and then get the closest N wordbox,
repeat this step for every side(up,down,left,right) and for every wordbox.
*e.g. example drawing to find edge on right side
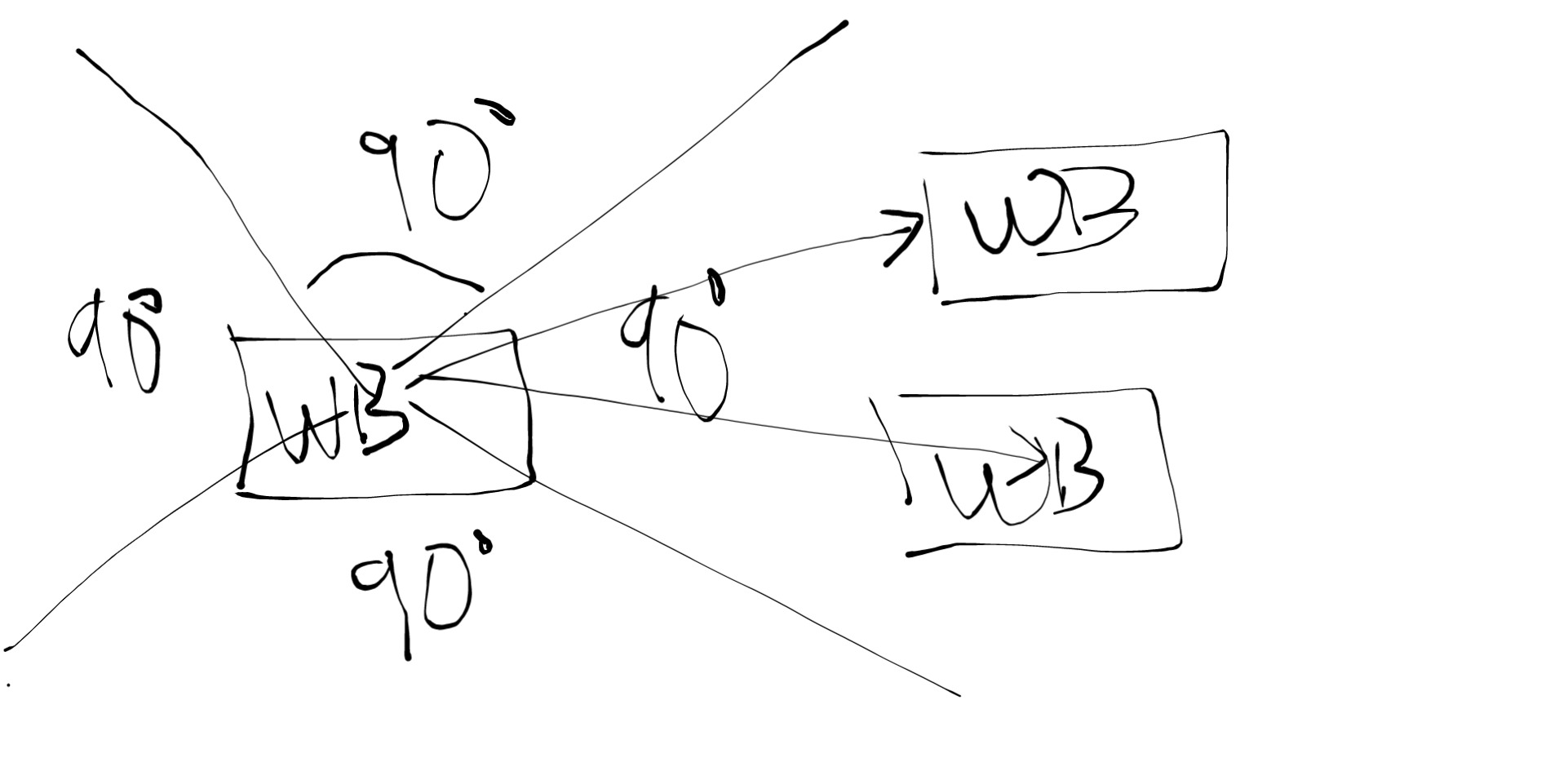
So to connect to opposite side of another wordbox, just calculate distance based on the points on the edges instead on the midpoint.
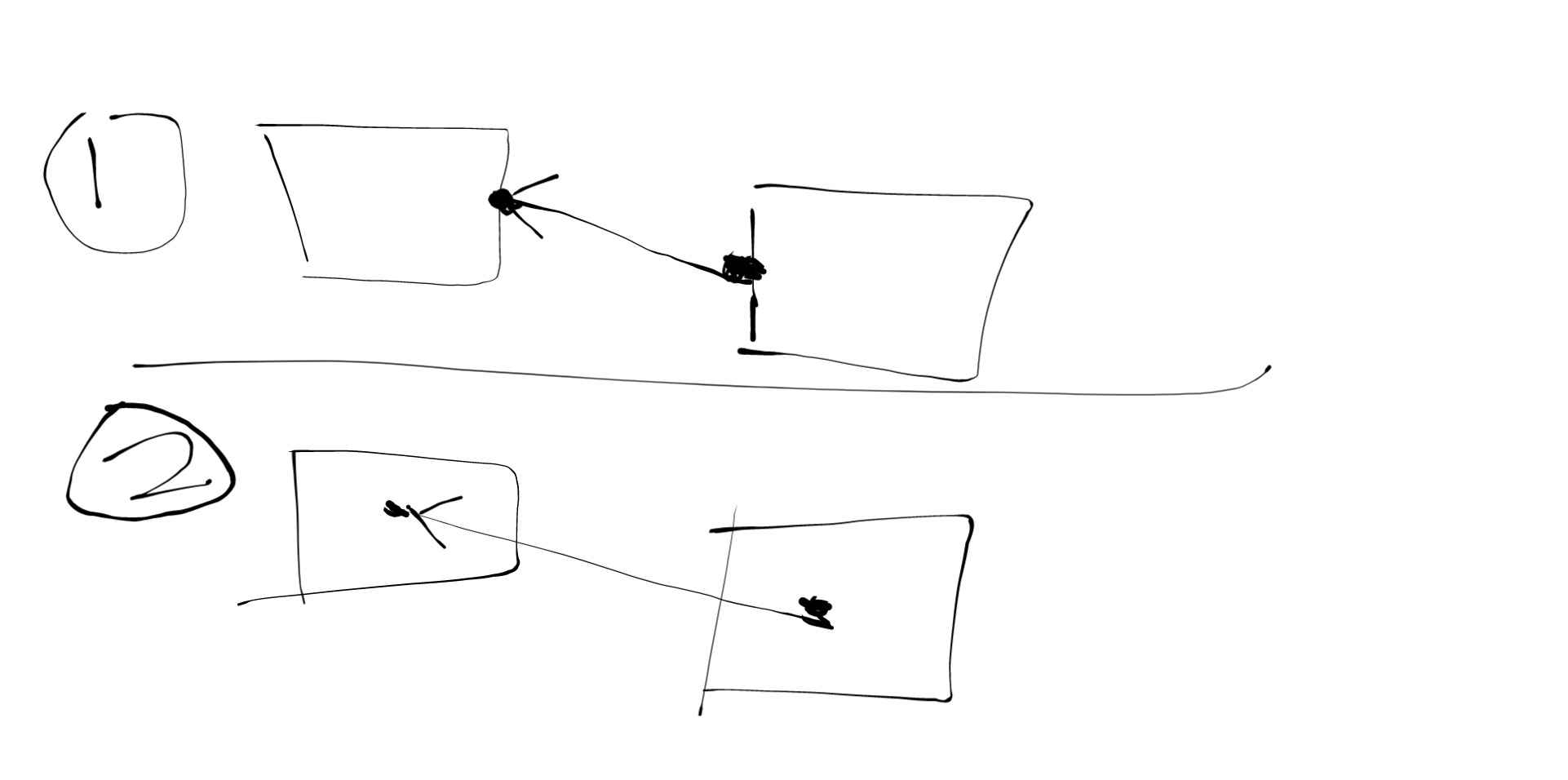
Feel free to give suggestion to my approach, thank you!
1 Like
Sorry that I cant help you on this, I haven’t try on the chargrid representation.
Wow, thank you for the detailed reply And for the drawing as well, it paints a clear picture of your method.
I think your approach is sound. Will implement it and let you know how it turns out.
Also, just for curiosity’s sake, did you use this paper for ‘table items’ or for other classes such as ‘date’, ‘address’, etc. Reading the paper seemed to suggest that it could be used for both.
Again, thank you for taking the time to reply 
1 Like
Yeah, I use it on table items/line item and other item as well, seems to work pretty well for now.
Hi @Neeb, for the graph convolution, did you concatenate all the neighbors and feed it to a fully connected/Dense layer,
Or did you use a convolutional layer on it?
Edit: Went with Concat then Conv
1 Like
Hi Neeb,
In the paper it says,
Our attention transformer unit does not use causality,nor query masking
Does it mean that we don’t mask the input sequence when we feed it to the multi-head attention? But I understand that without the masking we can’t associate a particular output label with a given input sequence.
The paper is quite confusing at places 
Have a great day!
I used concat into dense
From my understanding, masking is used to hide certain input, I saw tensor flow implementation of transformer they use masking to mask out padded value, so if we does not have padded value then is fine to go without mask?
And from the transformer paper : “We implement this inside of scaled dot-product attention by masking out (setting to −∞) all values in the input of the softmax which correspond to illegal connections”, I assume they mean padded value is illegal so they mask out, so if you think anything that the network should not focus on, it should be mask I guess.
So I just let the network figure out which part of input sequence to place their attention on in training phase. Associate with output label will happen after the sigmoid layer right?
Actually I am also quite confused on the attention block architecture also, is X on it matmul?, if so the dimension doesn’t match the output of a matmul …
Hi,
Can anyone guide on the approach used for creating ground truth masks for Chargrid?
Having some trouble understanding how to label the data for training.
Hi Neeb,
Wonderful that you implemented rossum paper.
What dataset did u use for the implementation?
Hi Diego,
I have drooped you a note to your email address.
Many thanks in advance for the help.
Regards
Saurabh Jha