Hi,
I have joined the Kaggle Humpback Whale Identification challenge. Humpback Whale Identification Challenge
Here is the link to my github repo - https://github.com/bhuvanakundumani/humb_back_whale_identification.git
I have
data = ImageDataBunch.from_csv(path ,csv_labels=‘train.csv’, ds_tfms=tfms, size=24);
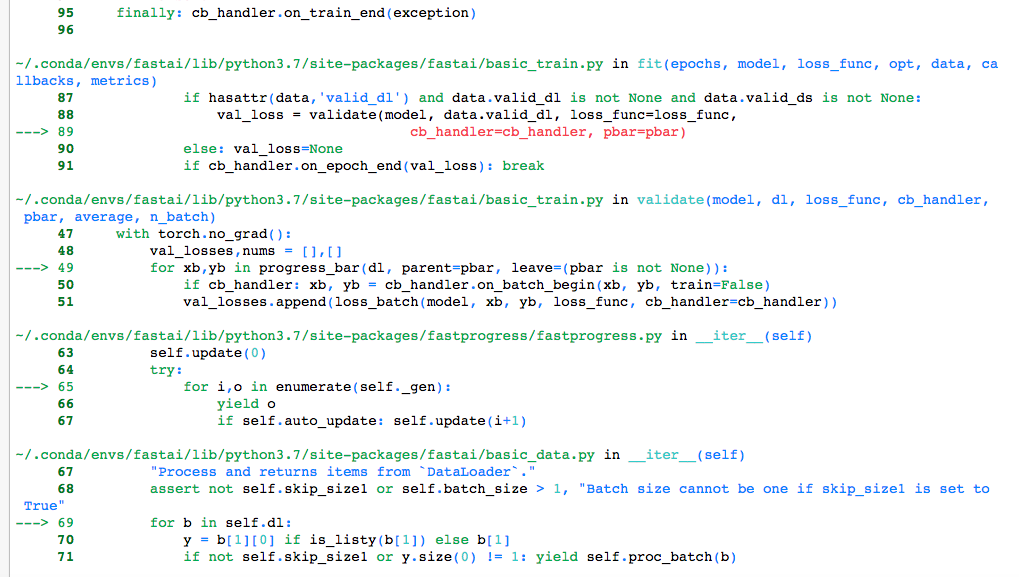
I am getting an error when i run
data.show_batch(rows=3, figsize=(6,6))
FileNotFoundError Traceback (most recent call last)
in
----> 1 data.show_batch(rows=3, figsize=(6,6))
/opt/anaconda3/lib/python3.6/site-packages/fastai/basic_data.py in show_batch(self, rows, ds_type, **kwargs)
121 if rows is None: rows = int(math.sqrt(len(b_idx)))
122 ds = dl.dataset
–> 123 ds[0][0].show_batch(b_idx, rows, ds, **kwargs)
124
125 def alt_show_batch(data, rows:int=None, ds_type:DatasetType=DatasetType.Train, **kwargs)->None:
/opt/anaconda3/lib/python3.6/site-packages/fastai/data_block.py in getitem(self, idxs)
413 def getitem(self,idxs:Union[int,np.ndarray])->‘LabelList’:
414 if isinstance(try_int(idxs), int):
–> 415 if self.item is None: x,y = self.x[idxs],self.y[idxs]
416 else: x,y = self.item ,0
417 if self.tfms:
/opt/anaconda3/lib/python3.6/site-packages/fastai/data_block.py in getitem(self, idxs)
80
81 def getitem(self,idxs:int)->Any:
—> 82 if isinstance(try_int(idxs), int): return self.get(idxs)
83 else: return self.new(self.items[idxs], xtra=index_row(self.xtra, idxs))
84
/opt/anaconda3/lib/python3.6/site-packages/fastai/vision/data.py in get(self, i)
288 def get(self, i):
289 fn = super().get(i)
–> 290 res = self.open(fn)
291 self.sizes[i] = res.size
292 return res
/opt/anaconda3/lib/python3.6/site-packages/fastai/vision/data.py in open(self, fn)
284 self.sizes={}
285
–> 286 def open(self, fn): return open_image(fn)
287
288 def get(self, i):
/opt/anaconda3/lib/python3.6/site-packages/fastai/vision/image.py in open_image(fn, div, convert_mode, cls)
440 “Return Image object created from image in file fn.”
441 #fn = getattr(fn, ‘path’, fn)
–> 442 x = PIL.Image.open(fn).convert(convert_mode)
443 x = pil2tensor(x,np.float32)
444 if div: x.div_(255)
/opt/anaconda3/lib/python3.6/site-packages/PIL/Image.py in open(fp, mode)
2607
2608 if filename:
-> 2609 fp = builtins.open(filename, “rb”)
2610 exclusive_fp = True
2611
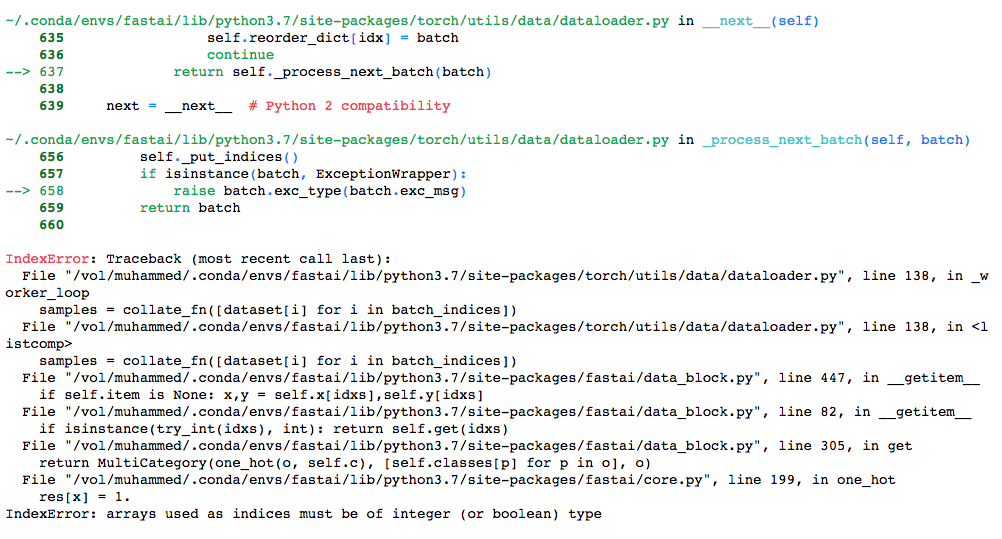
FileNotFoundError: [Errno 2] No such file or directory: ‘data_whale/./0000e88ab.jpg’
How do i fix this?