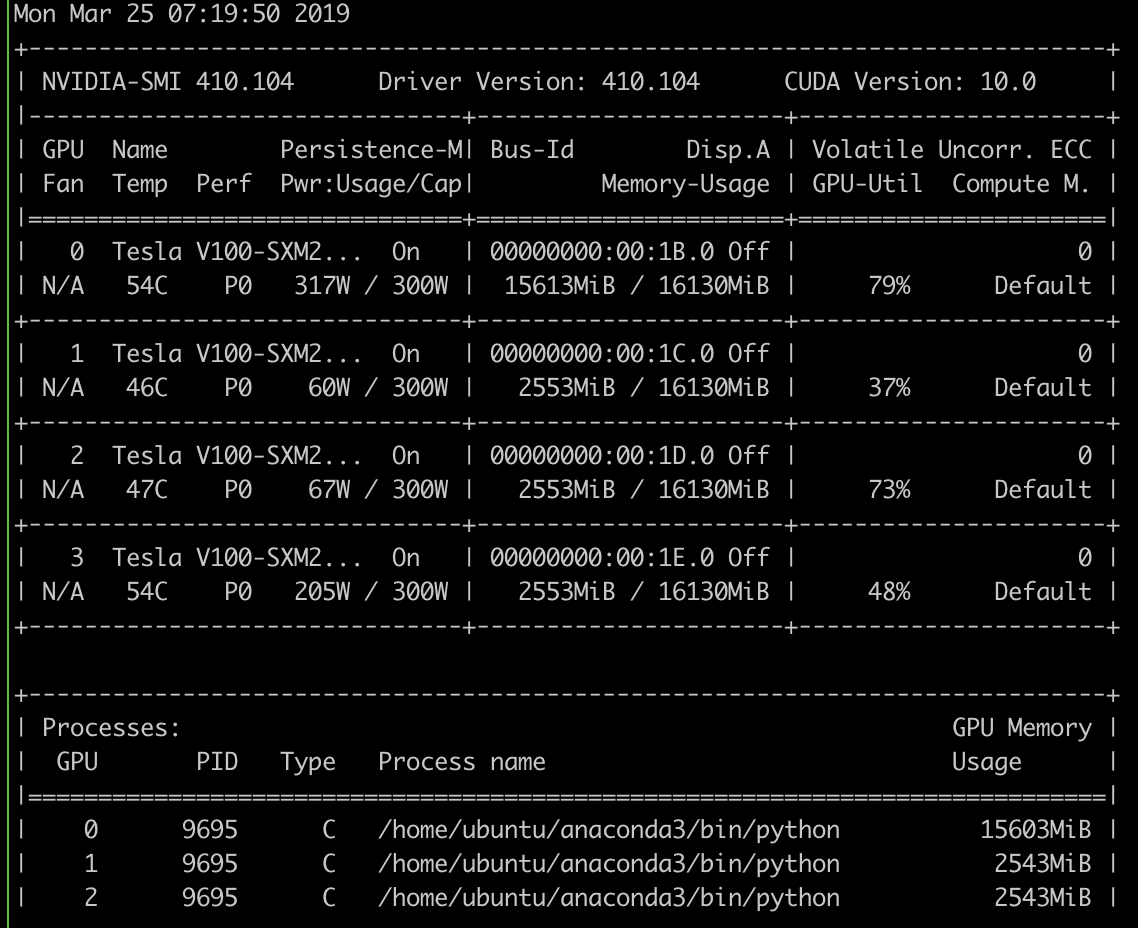
Your first line is incorrect, it should be:
learn.model = torch.nn.DataParallel(learn.model, device_ids=[0, 1])
Your first line is incorrect, it should be:
learn.model = torch.nn.DataParallel(learn.model, device_ids=[0, 1])
Thanks for your reply. this works now but I cannot save the model that is being trained via DataParallel. what am I doing wrong here? :
mName_S = str('bestModel_+ aName)
learnS = create_cnn(data, arch,
metrics=[accuracy, error_rate],
callback_fns=[partial(CSVLogger, filename =str(‘stat_’ +str(tr)+‘S’+ aName)), ShowGraph,
partial(SaveModelCallback, monitor =‘val_loss’, mode =‘auto’, name = mName_S )])
learnS.model=torch.nn.DataParallel(learnS.model, device_ids=[0,1])
learnS.load(mName_S)
log_preds, y_true = learnS.TTA()
y_true = y_true.numpy()
y_preds = np.argmax(np.exp(log_preds), axis=1)
What I ideally want to do is to train a model on multiple GPU, then save it, and later on be able to load it and predict some data via TTA.
We can’t help without seeing the full error message and your version of fastai.
hi @sgugger
this is the error it generates:
Traceback (most recent call last):
File “GpyCode.py”, line 85, in
learnS.load(m)
File “/homes/…/python3.6/site-packages/fastai/basic_train.py”, line 217, in load
state = torch.load(self.path/self.model_dir/f’{name}.pth’, map_location=device)
File “/homes/…/python3.6/site-packages/torch/serialization.py”, line 365, in load
f = open(f, ‘rb’)
FileNotFoundError: [Errno 2] No such file or directory: ‘data/LC_B_5/models/bestModel_5_S__resnet101.pth’
it says it cannot load the trained model, however this line of code :
partial(SaveModelCallback, monitor =‘val_loss’, mode =‘auto’, name = mName_S )])
which is responsible for saving the trained model is not saving the model neither generates any error message while in single GPU and multi CPU mode it saves the trained model perfectly and therefore load it without problem.
Thanks
I’m looking into training a language model on a fairly large dataset and I’m hoping to use multiple GPUs. Is it still the case that RNNs don’t work with multi-GPU?
No it works properly. It’s the SaveModelCallback that might have some problem.
Hi
I am training ULMFiT on multiple GPUs. I am facing this issue that my GPUs usage is heavily imbalanced.
System configurations:
Used fastai and torch version:
1.0.51.dev0 1.0.1.post2
Here is the code:
save_model = partial(SaveModelCallback,
monitor=‘accuracy’,
every=‘improvement’,
name=‘best_lm’)
early_stop = partial(EarlyStoppingCallback,
monitor=‘val_loss’,
min_delta=0.01,
patience=2)
lm_learner = language_model_learner(data_lm, ARCHITECTURE,
drop_mult = DROP_OUT_MULTIPLIER,
callback_fns = [early_stop, save_model])
lm_learner= lm_learner.to_parallel()
lm_learner.freeze_to(-1)
lm_learner.fit_one_cycle(cyc_len = 1,
max_lr = 0.04,
moms = (0.8, 0.7))
I have the same problem as @soorajviraat i.e. when training language models only one gpu memory is fully utilized (in the case of CNNs everything is working correctly). I’ve run some benchmarks. Here are the results:
ARCH, GPU type, Dataset
note: jeremy suggested that limiting factor might be loaders and to use torchvision to fix it. It’s an old post. I don’t know if it the problem was already addressed so I’m planning to check it and add the results to this post
Resnet34, 4xK80 GPU, FastAI PETS
GPU type, Dataset
4xK80 GPU, FastAI idbm
AWD_LSTM
Transformer
TransformerXL
AWD_LSTM
Code I used for parralelization is following
learn = cnn_learner(data, models.resnet34, metrics=error_rate)
learn.model = torch.nn.DataParallel(learn.model)
I’m not sure what’s the cause. Maybe it is working correctly (we can see a speed up in language models even though memory is limiting the batch size and thus parallelization speed up). It would be great if someone experienced could interpret the results we have here
I tried this but, in the following line:
learn.lr_find()
I got the following error:
Expected tensor for argument #1 ‘input’ to have the same device as tensor for argument #2 ‘weight’; but device 2 does not equal 0 (while checking arguments for cudnn_batch_norm)
Thank you @shaun1 this is very helpful. I am struggling with point (5), loading the state_dict into the model. When I do
model.load_state_dict(new_state_dict)
I get the error message:
‘LanguageLearner’ object has no attribute ‘load_state_dict’
Any help would be great!
Does multi gpu works with unet learner?
Like anything else, as long as you use distributed training. DataParallel does not work with the unet_learner.
Hi @soorajviraat,
I have the same issue as yours with following code:
learn = language_model_learner(data_lm, AWD_LSTM, config=config, model_dir=self.model_dir.relative_to(data_lm.path), pretrained=False, **trn_args)
learn = learn.to_parallel()
Did you find any solution or reason? Is it maybe because of the famous python’s Global Interpreter Lock (GIL) that allows only one thread to run in multi threading application? I used 4 GPUs, so I though that the performance could increase at least more than 3x, but instead of 50s/epoch (with 1 GPU), I got only 37s/epoch (with 4GPUs). Here is my screenshot:
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 418.126.02 Driver Version: 418.126.02 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla V100-SXM2... Off | 00000000:06:00.0 Off | 0 |
| N/A 30C P0 41W / 300W | 11MiB / 32480MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla V100-SXM2... Off | 00000000:07:00.0 Off | 0 |
| N/A 30C P0 41W / 300W | 11MiB / 32480MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 2 Tesla V100-SXM2... Off | 00000000:0A:00.0 Off | 0 |
| N/A 30C P0 41W / 300W | 11MiB / 32480MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 3 Tesla V100-SXM2... Off | 00000000:0B:00.0 Off | 0 |
| N/A 27C P0 41W / 300W | 11MiB / 32480MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 4 Tesla V100-SXM2... Off | 00000000:85:00.0 Off | 0 |
| N/A 43C P0 78W / 300W | 4220MiB / 32480MiB | 56% Default |
+-------------------------------+----------------------+----------------------+
| 5 Tesla V100-SXM2... Off | 00000000:86:00.0 Off | 0 |
| N/A 43C P0 68W / 300W | 4220MiB / 32480MiB | 64% Default |
+-------------------------------+----------------------+----------------------+
| 6 Tesla V100-SXM2... Off | 00000000:89:00.0 Off | 0 |
| N/A 45C P0 72W / 300W | 4220MiB / 32480MiB | 53% Default |
+-------------------------------+----------------------+----------------------+
| 7 Tesla V100-SXM2... Off | 00000000:8A:00.0 Off | 0 |
| N/A 43C P0 141W / 300W | 26998MiB / 32480MiB | 37% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 4 21447 C python 4209MiB |
| 5 21447 C python 4209MiB |
| 6 21447 C python 4209MiB |
| 7 21447 C python 26987MiB |
+-----------------------------------------------------------------------------+
There was similar issue in https://github.com/pytorch/pytorch/issues/3917. The user mentioned the imbalanced memory usage might be caused by a memory leak in the loop of the main thread. Maybe fastai has also a memory leak in the main loop? Btw I use fastai 1.0.61 and pytorch 1.3.1
After some more searches, I found out that such imbalance GPU usage using DataParallel is an expected behaviour. It occurs because the result of all parallel computation are gathered in the main GPU as explained in the following article by Thomas Wolf from huggingface: https://medium.com/huggingface/training-larger-batches-practical-tips-on-1-gpu-multi-gpu-distributed-setups-ec88c3e51255. The Pythons GIL could further slow down the multi threading used by DataParallel. A better approach is using Distributed training with torch.distributed.launch. It uses multi processing instead of multi threading and provides balanced GPU usage. It is also mentioned in fastai : https://docs.fast.ai/distributed.html
Did anybody out there figure out how to use multiple GPUs with language_model_learner, using fast.ai version 2? Links to code examples would really help.
I am trying to use a Jupyter notebook in AzureML with 4 GPUs, but only 1 GPU gets utilized. I am trying to adjust code from https://github.com/fastai/fastbook/blob/master/10_nlp.ipynb to work with multiple GPUs.
For example, my changes look like this:
learn.model.cuda()
dls_lm.cuda()
learn.to_parallel(device_ids=[0,1,2,3])
I encounter “RuntimeError: Input and hidden tensors are not at the same device, found input tensor at cuda:1 and hidden tensor at cuda:0”
I understand that CUDA wants me to send the model and the input to all GPUs, but after trying a few different things, I still see only 1 GPU being used:
Help with fast.ai would be really appreciated.