Yep, thats pretty amazing. Can you please share what steps worked for you?
Going to document everything in a medium post tomorrow and will reply back here when its up.
Btw @sermakarevich , really enjoyed your posts on using K-Fold validation with this competition! It’s nice to be placing up there with you and the other fastai students doing the comp 
2 Likes
I dont get your score with a single model, so maybe cv works not that well  Thanks for intend to share. Can you please add my @ so I wont miss your post?
Thanks for intend to share. Can you please add my @ so I wont miss your post?
1 Like
Do you mean that when you switched to other architectures you just directly trained with the whole dataset (following your initial process learned from the first architecture)?
How are you ensembling?
Are you averaging model weights to create a super model? Or are you averaging predictions against an identicially trained model that uses different training and validation data sets (e.g., like k-fold cv)?
Exactly.
1 Like
I am averaging predictions currently.
Which Kaggle competition is this?
Yah, I’m interested to see what @jeremy has to say on the value of K-Fold CV in neural networks in general and CNN architectures specifically.
It looks like @sermakarevich used it towards great results. I’m not sure exactly what his process was (e.g., did he use the same architecture or multiple architectures, did he use the same process to train each model or did it vary, etc…, etc…).
I started with resnet34 (using validation set) and got to rank 60 (the model was decent). I then moved to resnext101_64 with the same data split, and the ranking improved to 22.
I am now trying to use this resnext101_64 to train using the full dataset and val_idxs = [0], but I get an accuracy of 1. and training loss of about 0.62. I am not quite sure I am comfortable with what I see.
This means I’m overfitting right (given there is no validation set)? Am I right in assessing that this does not look as good as it should?
If you’re changing architecture, you need a proper validation set. Don’t use a validation set with just one image in!
My bad. I think I got it now.
So just to clarify, in order to utilize the complete training data in this case, if I train my model first using some data split and then recreate the data object and set val_idxs = [0] and train again, that should give me better results?
Yes - you need to exactly replicate a full process that worked with the validation set in place. Otherwise you don’t know if you’re over or under fitting!
These bigger models have far more parameters, so they overfit easily…
1 Like
Thanks! Makes much more sense now.
hi @wgpubs,
to confirm my understanding:
return data if sz>300 else data.resize(340,‘tmp’)
if the image size is greater than 300 then we use it as it is in ‘train’ ‘valid’ ‘test’ folder.
and if the image size is less than 300, we resize it into 340 size and place it in /tmp folder and use it.
Is my understanding correct?
Correct.
And any request we make for a size less than 300 will simply use the saved images in the /tmp folder. So if you first train against size 224 and then 299, the transforms will simply be resizing the same set of saved images.
3 Likes
ok. Thank you.
I tried to use val_idxs=[0] but I get an assertion error when trying to load the pretrained convnet.
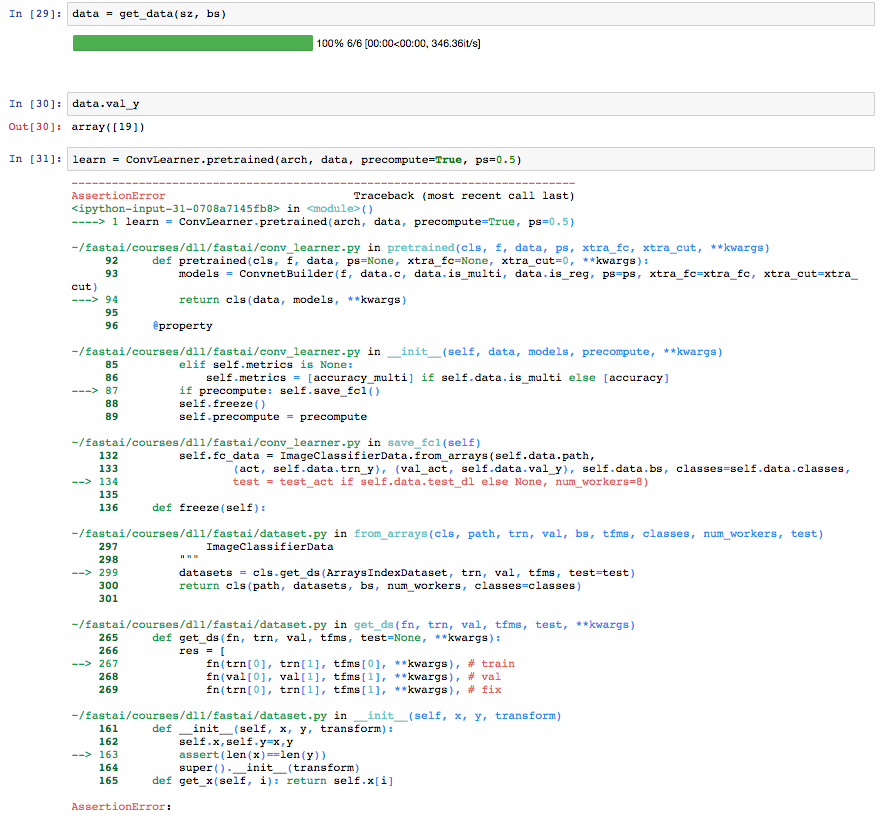

@stathis I think its because you have Precompute=True. It’s giving the error because you previously had activations generated on the validation set but now the validation set isn’t there. I believe if you switch to Precompute=False then it should work. In other words, training on all of the data doesn’t really work with Precompute=True.
3 Likes