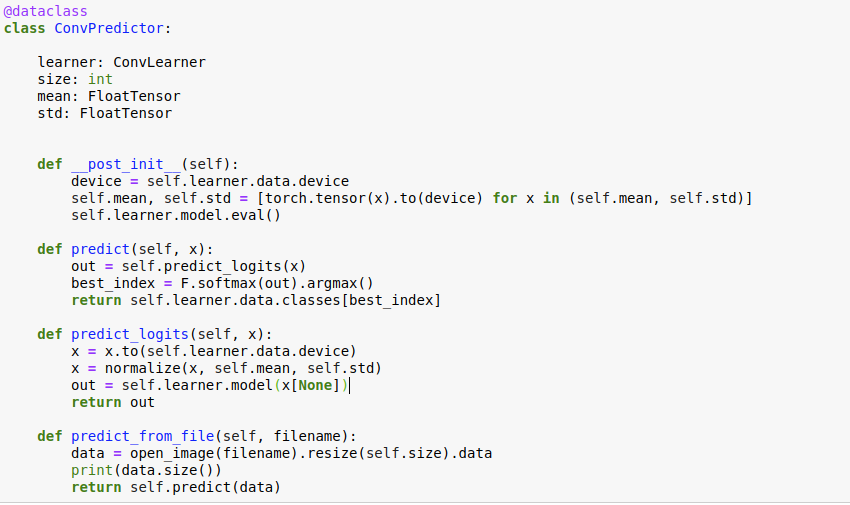
Update: posting the fastai-compliant way to predict custom image class.
Ok, finally, I think here is a more or less “canonical” approach to generate a prediction using fastai standard classes and methods:
img = open_image(filename)
losses = img.predict(learn)
learn.data.classes[losses.argmax()]
Original Post
I’m training a model on some dataset like this:
data = ImageDataBunch.from_name_func(..., size=224) # dataset creation goes here
data.normalize(imagenet_stats)
learner = ConvLearner(data, models.resnet34, metrics=[error_rate])
learner.fit_one_cycle(1)
Now I would like to run my model on some custom image. For example, let’s pretend that I have an image in my local file system. I read this image, and convert into a tensor of appropriate shape and type:
img_path = 'path/to/the/image.png'
pil_image = PIL.Image.open(img_path).convert('RGB').resize((224, 224))
x = torch.tensor(np.asarray(pil_image), dtype=torch.float)
w, h, c = x.size()
x = x.view(c, w, h).to(default_device)
Finally, I feed the image into model:
preds = learner.model(img[None])
However, the last step gives me an error:
~/anaconda3/envs/fastai/lib/python3.7/site-packages/torch/nn/functional.py in batch_norm(input, running_mean, running_var, weight, bias, training, momentum, eps)
1364 size = list(input.size())
1365 if reduce(mul, size[2:], size[0]) == 1:
-> 1366 raise ValueError('Expected more than 1 value per channel when training, got input size {}'.format(size))
1367 return torch.batch_norm(
1368 input, weight, bias, running_mean, running_var,
ValueError: Expected more than 1 value per channel when training, got input size [1, 1024]
Could anyone advise, what is the correct way to prepare new data before feeding into the model? I mean, I would like to do something similar to model.predict(X) from scikit-learn, or keras.
I guess I need to apply normalization as well but I think that probably source of the error is something else.