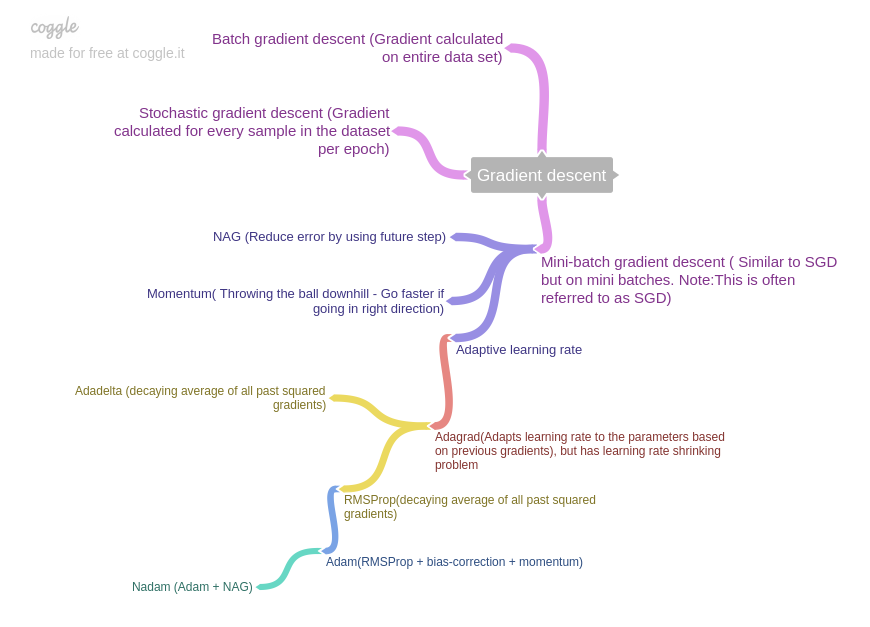
Here is another mind map I created which shows relation between different optimizers. From this, seems like Nadam is the best, but Adam is the most popular right now.