I think we can bother @sgugger to use his powers and wiki-fy this discussion.
Then we could collaborate and maintain a list above?
I’ll volunteer to help although all of the wonderful papers shared here seem very intimidating to me.
@nbharatula Very interested in the topic of ethics, as I’m sure many others here would be too. As DL/ML practitioners, I think it would be irresponsible of all of us not to take ethics very seriously and always put this into consideration. For the fastai forum, my personal opinion though is that AI Ethics is so important it more than deserves its own separate topic - not just some posts that could get buried in some other topic I actually started a similar topic in the previous Part 2 (2018). I anticipate that this topic would probably spark more conversation now as this subject has gradually (finally) started to reach top-of-mind awareness as a critical issue in our industry.
Also I highly recommend following Rachel on twitter if you aren’t already as she has been championing AI Ethics for quite some time now (even before the big companies took serious notice) and she provides excellent content/references on this subject.
Could be great!! But to be very effective we should carefully select among the papers linked here. I think of a list with no more of 10 entries and ordered by topic. We could start with 4 main topics :
Computer vision : #CV
Natural language Processing : #NLP
Optimizations and Training tricks : #OTT
Ethics and Good Practices : #EGP (seems there exists a new thread on this topic. To be removed)
Any suggestion ? Might hashtag like #CV be useful here?
I can help with the NLP list btw.
Hi @jamesrequa, Yes I agree, this deserves its own topic/thread. But sprinkling it across other posts also helps keep it top of mind! I’ll summarise my findings here as well as on the other thread.
@init_27 thanks for starting the 2019 thread for this topic.
And yes, I follow Rachel and a few other awesome folks focused on ethics research. Thanks for the suggestion!
There’re a few robotics papers I’m looking at. The RCAN paper seems interesting. There was also a link today on twitter about ‘Neural Task Graphs’ claiming to be essential to future robotics work – I haven’t taken a look at it yet.
@fabris I’ve deleted the OP. However, It’s not a “personal blog” that I had shared. I’ve started a “5-minute paper discussion series” to share quick highlights from papers and I had requested for feedback for my first attempt at this.
I’ve tried classifying papers into single categories. Eventually there was so much overlap between categories that I switched to using multiple tags/keywords.
The authors have shared their approaches of performing Transfer Learning in NLP and with these tricks, they claim to perform better than the ULMFiT approach on a few datasets, specially when using lesser training examples .
Most interesting one was defining an auxiliary loss ,by adding a new layer and also accounting for the orignal loss value
TIL, if you want to do 2 tasks using 1 NN or if you’re doing 1 task using a NN, you can create 2 loss values that you want to optimize and that would lead to better performance!
Edit: Here is the amazing explanation of the “2 loss strategy” by @lesscomfortable: (Copy paste from our slack group, Francisco’s words:)
“I think it’s more about generalizing predictive models. I don’t know if it applies to any model, it seems to be restricted to generalizing predictive series (predict next sound, next word, next stock price etc) to new tasks (classification).
It’s like being less ‘harsh’ when changing tasks. I think about it like 'hey I know that you know how to do this but slowly you will have to use what you know to do that” you’re telling the model ‘take your time to learn’ "
If I remember correctly the RCNN methods are either obsolete or most of what they can do is done better by SSD-type models. Maybe they’re higher accuracy? I saw some Facebook research on detecting faces in crowds. SSDs don’t use the region-proposal part of RCNNs.
EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
5 minute summary link:
The paper investigates 4 “Easy Data Augmentation” Techniques in NLP (!!)
Synonym Replacement
Random Insertion
Random Swap
Random Deletion
These are tested on 5 text classification data sets, using simple RNN and CNN (yes,CNN) architectures and the authors demonstrate some performance improvements, especially when using “smaller” subsets of training data
Sharing some papers that explore ethics issues of AI. Wanted to post a more comprehensive and better annotated list of blogs and papers, but I really need to stop letting the perfect get in the way of the good. So here is a start:
Describes the Mechanism Design for Social Good (MD4SG) research agenda, which involves using insights from algorithms, optimization, and mechanism design to improve access to opportunity
Provides a simple framework to understand the various kinds of bias that may occur in machine learning - going beyond the simplistic notion of dataset bias.
Really enjoyed this paper, gives very solid theoretical motivation for their new recurrent architecture called “AntiSymmetric RNN”. Well-designed experiments demonstrate improvements along virtually every dimension of interest over LSTM and GRU (less parameters, faster training, more stability, better end-results).
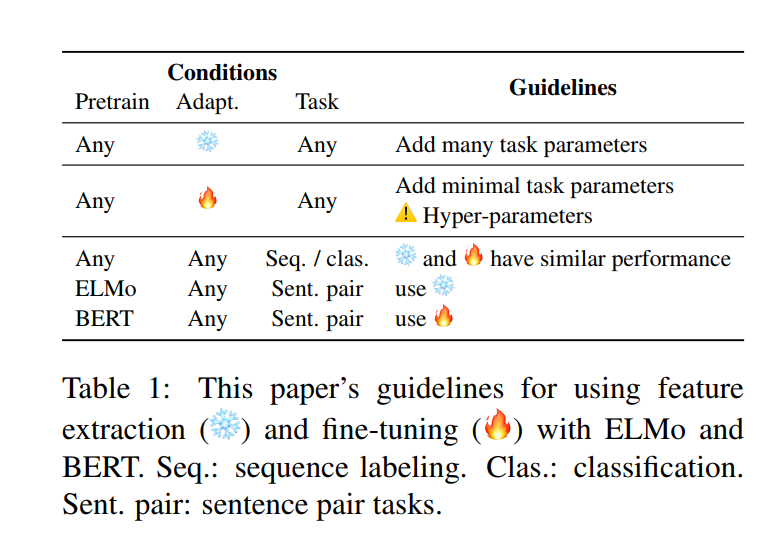
This paper focuses on sharing the best methods to “adapt” your pretrained model to the target task. (answering the question: “To Tune or Not to Tune?”)
It compares two approaches feature extraction Vs Fine Tuning
(Yes the authors use emojis!)
There is also a quick guideline for practitioners:
In Self-Supervised Generative Adversarial Networks authors exploit two popular unsupervised learning techniques, adversarial training and self-supervision, to close the gap between conditional and unconditional GANs.
The DeepMind team also updated the Compare GAN library, which contains all the components necessary to train and evaluate modern GANs.
 I’ll summarise my findings here as well as on the other thread.
I’ll summarise my findings here as well as on the other thread.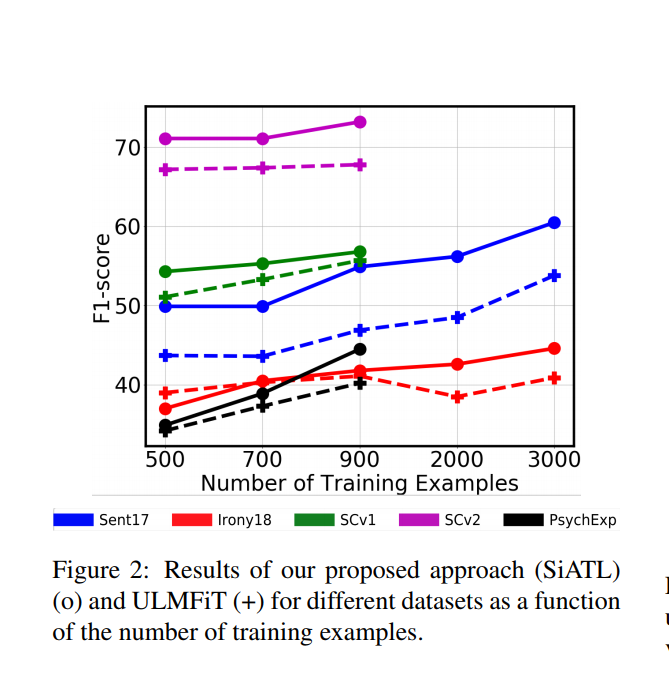

 Vs Fine Tuning
Vs Fine Tuning