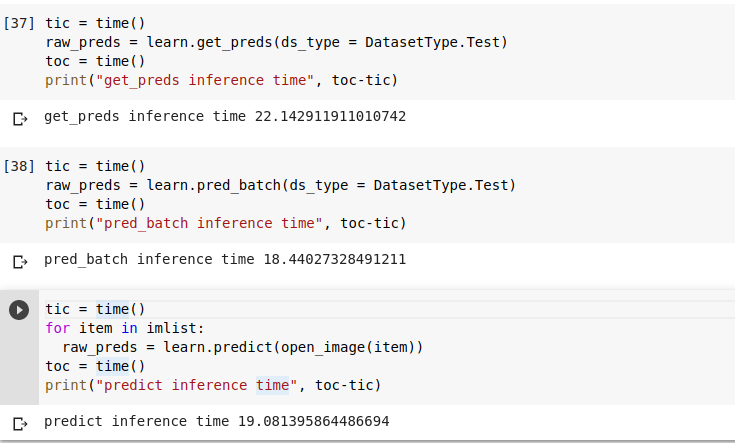
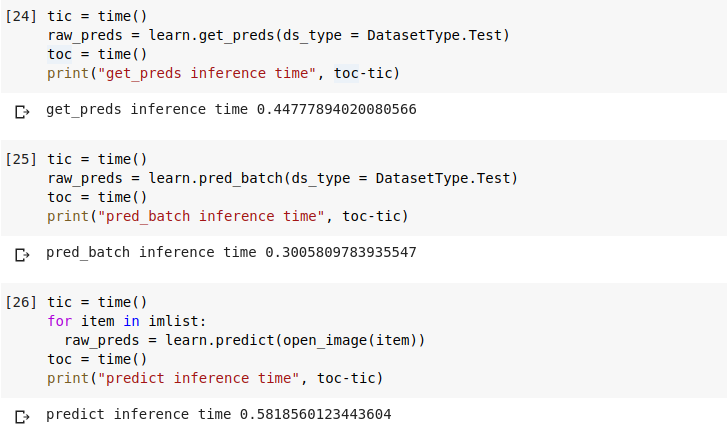
I have to run inference on 6 images at a time. So, instead of using predict(), I created a batch of 6 images and tried get_preds() and pred_batch(). There is not much difference in time. How is this possible?
@muellerzr has done some great work on inference which covers the inner workings of different inference approaches. This thread might be a good starting point for learning more about the speed of different approaches 
2 Likes
I saw the thread. My project is based on fastai v1 and he is shown results in fastaiv2.
The concepts can still apply to v1, its underlying PyTorch. (Some of it)
1 Like
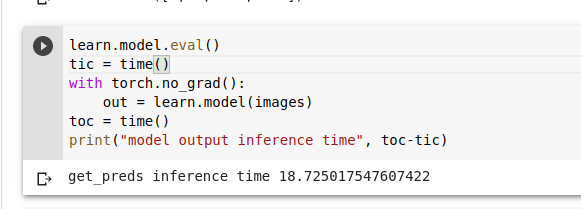
I tried the last resort and made predictions directly using learn.model(image_batch) and surprisingly even that took around 18 seconds on CPU. @muellerzr
Then that’s your bottleneck basically. What’s your model? You could also try converting it over to torchscript
https://forums.fast.ai/t/speeding-up-fastai2-inference-and-a-few-things-learned/66179/25
It’s a fastai Image segmentation model. Bsically a unet with resnet34 encoder.
That’s unsurprising then on the CPU, and it’s a very large model that won’t convert to torchscript well IIRC
Actually I am surprised by the fact that there is no significant diffference in time, when passing images in batch versus passing images in a loop.
I may look into this shortly this morning then and see what I find too (I haven’t looked into CPU specific yet)
thank you. waiting for your response
There’s not really much I can say about that, segmentation models need a GPU (atleast fastai’s) to be run efficiently. The timings I got were better (or worse sometimes) than what you have right now, using a very basic loop (either in v1 or v2), so it is a model bottleneck. (as I said earlier)