Hey,
I have a batch of 4 pairs, with each pair (item,item) to have two items (input,target) of images (TensorImage).
Now I’m trying to add this augment of RandomErasing() only on the input image of each pair (I don’t want that to apply on the target image).
This is the augment:
# Cell
def cutout_gaussian(x, areas):
"Replace all `areas` in `x` with N(0,1) noise"
print(x.shape)
chan,img_h,img_w = x.shape[-3:]
for rl,rh,cl,ch in areas: x[..., rl:rh, cl:ch].normal_()
return x
# Cell
def _slice(area, sz):
bound = int(round(math.sqrt(area)))
loc = random.randint(0, max(sz-bound, 0))
return loc,loc+bound
# Cell
class RandomErasing(RandTransform):
"Randomly selects a rectangle region in an image and randomizes its pixels."
order = 100 # After Normalize
def __init__(self, p=0.5, sl=0., sh=0.3, min_aspect=0.3, max_count=1):
store_attr()
super().__init__(p=p)
self.log_ratio = (math.log(min_aspect), math.log(1/min_aspect))
def _bounds(self, area, img_h, img_w):
r_area = random.uniform(self.sl,self.sh) * area
aspect = math.exp(random.uniform(*self.log_ratio))
return _slice(r_area*aspect, img_h) + _slice(r_area/aspect, img_w)
def encodes(self,x:TensorImage):
count = random.randint(1, self.max_count)
_,img_h,img_w = x.shape[-3:]
area = img_h*img_w/count
areas = [self._bounds(area, img_h, img_w) for _ in range(count)]
return cutout_gaussian(x, areas)
I tried to adjust this line:
for rl,rh,cl,ch in areas: x[..., rl:rh, cl:ch].normal_()
into:
for rl,rh,cl,ch in areas: x[0, :, rl:rh, cl:ch].normal_()
Which then applies the augment only on the first pair (both input and target) out of the 4 pairs (in the batch).
How can I change that function or line so that erasing would apply only on the input item of each pair in the batch?
Thanks


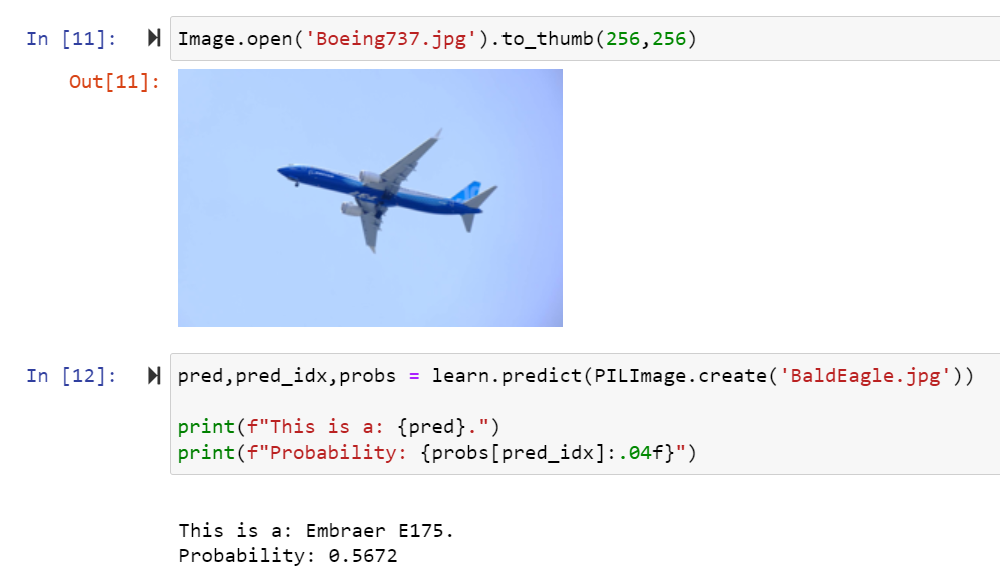
 Maybe we need a “classic fails” thread?
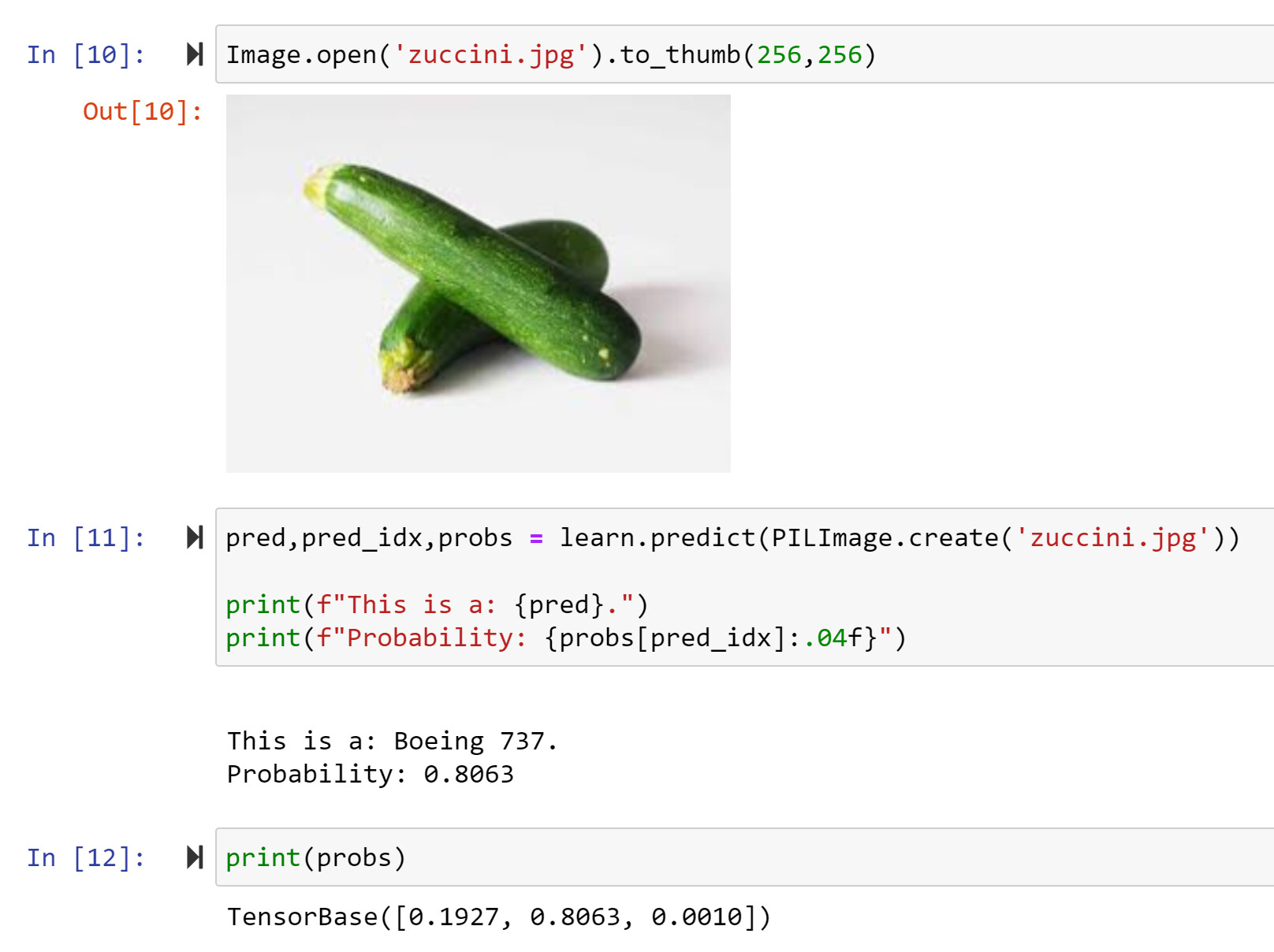
Maybe we need a “classic fails” thread?