I’m using an old (circa 2012) Dell Inspiron T3600 with a Xeon 8core/16t, 64GB DDR3, 1TB NVME, 1070ti running Ubuntu 20.04 … seems to work ok and gives me sustained performance above what I would get from a Tesla K80. I don’t think I’d be able to use it for a 30 or 40 series card unless I update the power supply which is 635W if I’m not mistaken. Based on some simple benchmarks posted on these forums it’s about 4x slower than a 3090 for smallish models.
Regarding noise, I’ve been alarmed at one time when I was running some training and the screen saver went haywire and all the fans came on at 100% all at once but it was quickly remedied by turning off the screensaver. During regular training (like fastai stuff, it revs up but calms down quickly after the training ends.)
I’ve had various different setups. My home box is 3 * 3090’s. Previous main university box was IIRC 10 * 2080ti’s. That one sounded like a rocket taking off!
I preferred not to go liquid for my home box due to reliability concerns, but I built a couple of liquid cooled machines for other people, and have observed that in order to keep them silent, you need to get one at least one 360mm radiator for each high-performance (~300W) card. In such a setting, you can afford to keep the fans below 800-1000 rpm, and even the cheapest fans are silent at these speeds.
Liquid or air? Maybe you can link that one if you want, it could be useful as a quick solution for people who are in search of a single gpu solution without being driven crazy by the noise
But the size of the batch size does not depend on the card, but on how much GPU memory it has, and how much memory you have available when running your work.
You can see how much memory you have on your card available by using this command on linux,
$ watch nvidia-smi
it will show you something like this:
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 510.47.03 Driver Version: 511.65 CUDA Version: 11.6 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA TITAN RTX On | 00000000:17:00.0 Off | N/A |
| 41% 34C P8 15W / 280W | 0MiB / 24576MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 NVIDIA TITAN RTX On | 00000000:65:00.0 On | N/A |
| 41% 42C P0 53W / 280W | 485MiB / 24576MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
you can see that in my first card I have 485MiB / 24576MiB, so I am using 485MiB just to run and have available to work with 24576MiB-485=24,091Mib. The Fewer things you have up on the screen the more memory you have to work with.
I have been able to do it on a 8GB 1070ti so I think a 1080ti should be able to do it as well (bs=64) but you may need to dial down the precision to fp16
Also, I let the onboard graphics handle the basic monitor I have hooked up, but then again, this is not my main machine and I only occasionally use the attached monitor for admin tasks on the machine. Usually I just remote into it anyway so I didn’t connect it to my GPU.
I wonder if someone tried renting a dedicated GPU instance and knows good providers for that? Something like Hostkey maybe? I’ve never tried any of them, but these should be more performant compared to virtual instances, I think. So one can off-load noise and hardware management to a dedicated team, but keep short training time.
Also, did you try to read data on the fly during training from some cloud storage, like S3 or Snowflake? The last time I trained something on the cloud, I was explicitly copying data back and forth between “locally” attached disk and blob store. But maybe it doesn’t make much sense, as it was still a mounted network drive, I believe. What is the best practice here?
And in general, it would be great to see some benchmarking that compares various approaches to setting up Deep Learning environments. Possibly there is one? So far, my self-built and a couple of times upgraded devbox still beats many other setups in terms of convenience and also performance of data reading/writing. But I would be happy to go with a full-cloud thing in case I find something with a good convenience/cost/performance balance. (Sounds like a unicorn…)
Can anyone tell me what is going wrong here? I am trying to do a clean install of fastai following the installation instructions given in https://docs.fast.ai/ → Getting started → Overview
The installation fails repeatedly and then hangs…
(base) malcolm@PC-GPU:~$ conda create --name fastai22
(base) malcolm@PC-GPU:~$ conda activate fastai22
(fastai22) malcolm@PC-GPU:~$ conda install -c fastchan fastai anaconda
Collecting package metadata (current_repodata.json): done
Solving environment: failed with initial frozen solve. Retrying with flexible solve.
Solving environment: failed with repodata from current_repodata.json, will retry with next repodata source.
Collecting package metadata (repodata.json): done
Solving environment: - |
I have an old GTX 1070 that I used for a year or so to mine crypto back in 2017. But what I always wanted was to train at least one machine learning model
At the beginning of 2019 I followed like 3 or 4 lessons of fastai, but it was impossible for me to set up the library in Windows. I think there wasn’t WSL2 yet, so I simply switch to Colab.
Now, watching the lesson 2 I followed the instructions and the installation seemed to work.
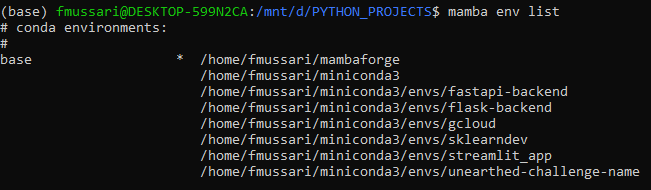
Although I had a conda installation, mamba created another (base) $ mamba env list
Listing the installed packages with $ mamba list I can see fastai 2.6.3 and pytorch 1.11.0.
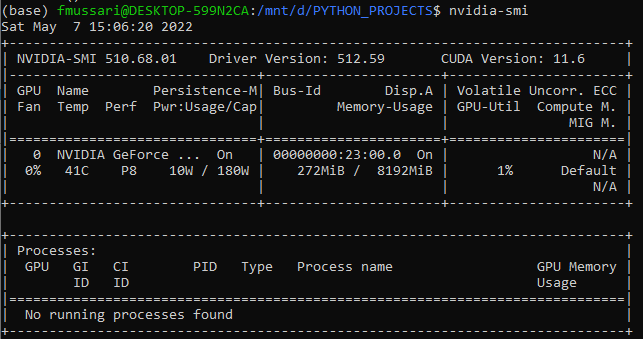
I can see the GPU $ nvidia-smi
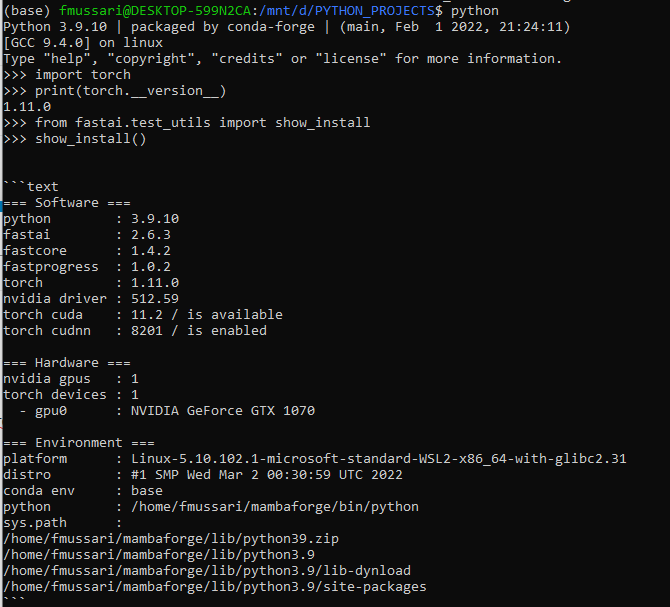
If I call python in the terminal I can import torch and fastai:
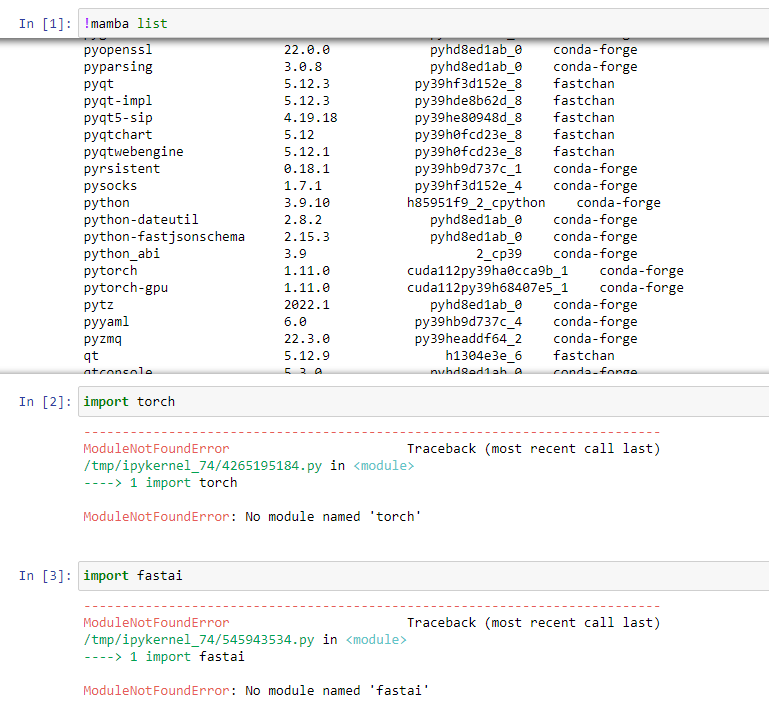
But then, when running jupyter notebook, I cannot import torch or fastai ModuleNotFoundError: No module named 'torch' ModuleNotFoundError: No module named 'fastai'
I know I can continue with Colab or Kaggle or any other online option, but I’m asking for help because it seems that I’m close to finally train a model locally, am I?
Have you activated the environment in which you installed fastai?
I.e. if you installed fastai in an environment called fastai2022, you should activate it with conda activate fastai2022. Then you can call the python interpreter and test it.
If you installed fastai in the base env, that’s generally a bad idea. Please create another environment for fastai. If that still doesn’t work, remove anaconda/miniconda altogether, then reinstall it, and leave the base env untouched.
There have been posts about it before (Fastai2 in Singularity Container), but it has been also evolved a lot since 2020, so I think worth mentioning it again.
It has been born as HPC containers solution and will take a couple of days learning curve (if you already familiar with a docker), but has a few nice properties which I found useful when you want to play with DL setups, including fastai:
Truly one single container file (if you want it to be 1 file of course) - copying and organizing different setups easier to me.
Better support for GPU’s and other ASICs (it is “closer” to PCI devices than docker)
You can work inside a container like inside a VM (interactive changes = persistent overlays) or/and use definition files. (can import docker containers as well)
Neat HPC features, MPI support and etc.
You can actually encrypt your container.
I found it convenient when I am still in experimenting mode (i.e. not ready to finalize a full definition file), but want to move containers easily between boxes or cloud instances or rollback quickly if an environment gets messed up.
Very interesting - I’ve never heard of this before. Might you consider writing a post about what this is, and why it’s interesting? I’m sure many people would find that helpful (I know I would!)
Hello, I am trying to set up FastAI on my Linux workstation using the fastchan channel. Installation went smoothly but something went wrong when I tried to import fastai in Jupyter notebook.
As soon as I import fastai using from fastai.vision.all import *, my notebook kernel died. I tried importing fastai via ipython and I received a Segmentation fault (core dumped) error.
nvidia-smi worked okay, so I do not think there’s a problem with CUDA.
It’s a bit tricky to debug without additional information. If you are in a hurry, just install docker, the nvidia container toolkit, and then install fastai inside a NGC container image (using the same installation instructions. I suggest miniconda and mamba).