I took the sacrifice , I have installed ubuntu 22.04 LTS with windows 11 in dual boot. I have found many problems when installing Fastai using fastchan; then I made a new environment where I installed the following in this order:
1- PyTorch 1.10.2
2- pip install fastai
3- conda install Jupyter notebook
The order mattered a lot; now, everything is working correctly.
I am using the default GPU driver and CUDA installation with ubuntu for the GPU and CUDA. I didn’t have to install or update anything. (when you first launch ubuntu and type Nvidia-smi in the terminal, you will find that the driver is already installed version 510 and CUDA version 11.4).
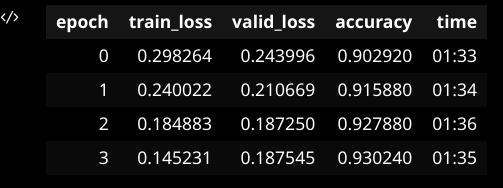
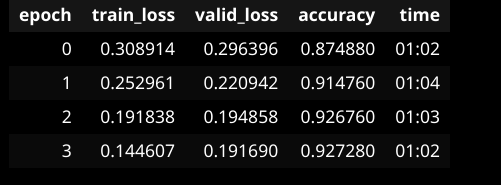
With my 3080 GPU, all the learning models in the intro notebook from the fastbook worked fine. However, for the IMDB classification model, it was extremely slow relative to the other models, and I had to make the batch size (bs=16) to overcome the (CUDA out of memory) problem.
Thanks for sharing the details aboutnyour setup @falmerbid , I’m thinking of upgrading to 22.04 so this is really helpful.
I’d also be interested in your IMDB training times. I find that IMDB training is usually slower compared to to the other examples in that notebook. I also had to set the BS to 16. Later on I noticed I could get up to 24 on my 1070ti (8GB) … With fp16, I could go up to bs=32 IIRC.
You will find below my training time for each epoch trained with a standard precision floating point… I need to learn more about the half-precision floating point (fp16) concept and its trade-offs
Maybe I’m wrong but I think you can auto-install drivers but not CUDA-has that changed recently? Did you have to configure anything seperately to make this work (while installing)?
Thank you Jeremy. The reason I install CUDA separetely still-I had read (IIRC it was Ross) had shared that installing CUDA separetely and compiling from source gives a slight better performance for the latest GPU architectures (Ampere, RTX 3000 series etc)
The other suggestion was to use NGC containers for most optimised speeds, I run my longer experiments inside the containers.
In my vanilla fastai conda env all the stuff works flawlessly. But in the fastbook environment (pip install fastbook), a warning about cuda capabilities is issued:
Keep in mind that Nvidia uses ONLY docker containers upon its very, very expensive DGX systems. Of course you can work on the bare metal, but such a practice is discouraged by Nvidia (and if something doesn’t work as expected, their technical support will give you a reprimand
Oh, it’s not only DGX, it can be run on any NGC certified servers which are available from makers like Dell, Asus, Supermicro, and more.
We have been using it for the last 2+ years and did not face such challenges, and we can modify them easily. The creator of timm has also been using NGC containers based on his tweets.
Of course. But you can run them on any machine whatsoever, not only NGC certified servers.
I cited DGX systems to highlight the fact that Nvidia itself, on its own systems, prefers not to work directly on the bare metal for AI (and other) appliances.
@VishnuSubramanian I would love to team up with you (Or @balnazzar) on this since three of us have access to a bit of hardware.
I always wanted to benchmark in numbers for practical knowledge:
How does compiling PyTorch from source Vs Conda install affect perf
Same for NGC Vs Others
SATA SSD Vs M.2 Premium (Samsung) Vs M.2 cheaper ones (WD Black)'s effect on performance
Having GPUs on x4 Vs x8 Vs x16 lanes’ effect in performance
Please let me know if any of these are of interest to you but these are some questions that I wanted to check how much do they change things.
Ex: You should ideally always get an M.2 drive but what if you get a super good deal on a 4TB SATA SSD, what are you losing compared to a 512GB Samsung highest end M.2?
I don’t have any SATA drive, but I got a bunch of nvme ones. Apart from the usual ‘speedy’ consumer drives in m.2 format, I got two Samsung Z-drives.
These units are quite interesting because they are SLC drives and beat any consumer drive in random data rate and random latency, and that’s what really matters in DL workloads (see below). I.e. they behave like something in between normal nvme ssds and DRAM modules.
It will be interesting to compare them with other consumer drives of mine, for example the 980 pro or the firecuda 530 (both in 2tb size), or with your big sata units.
We should take a bit of care in selecting the right workloads, tough. If you already have notebooks/datasets you used to benchmark your sata drives and that leverage a lot of little data points (typically NLP and tabular stuff) rather than a relatively small number of big data points (i.e. images), that would be ideal to see how such low-latency units behave.
I never compiled it from source, but there shouldn’t be any appreciable difference.
I did that back in 2018, and albeit I don’t remember the exact figures, the containerized environment was a bit faster than the bare metal. Nothing dramatic, tough.
The main advantage of docker, however, is that you don’t need to meddle with drivers/libraries at system level, and if you screw up something you won’t do any serious damage.
A conda env is something in between.
I actually did that, just out of curiosity, with two 3090s. I tried to set the slots in gen3 4x (as opposed to 16x) and it had shown little or no difference (but note that the gpus were nvlinked).
Consider that, having phased out my dual-3090 system, I now use only one gpu. I can benchmark by reducing both the number of lanes and the whether the slot should run at gen2/3/4 but it would be a lot less interesting w.r.t. a multi-gpu setup. For the record, Tim Dettmers found that with a single gpu, even going from 16x to 4x (gen3) amounted to 1-2% difference in performance.
One interesting benchmark you can perform @init_27, since you have the gpus, would be pitting one single a6000 against two 3090, of course selecting a batch size that exceeds the vram of a single 3090.
Also, try to lure nvidia into giving you a new 3090ti specimen
Other stuff doable:
RAPIDS vs bare CPU (various kinds of preprocessing steps)
Same here, still have a rather old devbox equipped with a couple of NVIDIA oldies, and they’re still enough even for rather heavy competitions, i.e., DICOM data segmentation.
The biggest challenge for me was (and still is, actually) to find a cloud setup with good I/O performance. I tried gcloud with x2-x4 GPUs V100/A100, but the throughput was ridiculous. Sometimes, it was slower (!) compared to running things on a dedicated devbox. I guess it was related to a too slow mounted storage. I mean, it is not a problem for smaller datasets, but for bigger ones it becomes a bottleneck. (Maybe an on-premise disk would help?)
I guess the question of “optimal” setup was raised multiple times on the forum. But still, I am a bit struggling with this topic of getting a good cloud setup with nice cost/performance balance. Like fast SSD/M.2 storage plus lots of VRAM which is not wasted due to slow read from a disk.
For anyone that’s installing this stuff on their own Linux box, needs CUDA 11 (to support the NVIDIA 3090) and happens to be upgrading an older fast.ai installation. I have a big box 64GB RAM, a 2TB M.2 SATA drive and an NVIDIA 3090 GPU. I’m now running:
Ubuntu Version 18.04.6 LTS (use system settings to see your version) mine is old but still works fine
MiniConda version 4.12.0 (use conda -V to see yours)
Python 3.9 use python to see yours)
Pytorch 1.11.0 (in python use import torch print(torch.__version__) to see yours)
CUDA 11.4 (use nvidia-smi to see yours
fastbook 0.0.21 (in python use import fastbook print(fastbook.__version__) to see yours)
Here’s are the steps I took to upgrade my old (2020 fast.ai) installation:
updated Miniconda - conda update conda
created a new repository for fastai5 - conda create --name fastai5
changed into the new conda environment -source activate fastai5
 , I have installed ubuntu 22.04 LTS with windows 11 in dual boot. I have found many problems when installing Fastai using fastchan; then I made a new environment where I installed the following in this order:
, I have installed ubuntu 22.04 LTS with windows 11 in dual boot. I have found many problems when installing Fastai using fastchan; then I made a new environment where I installed the following in this order:

 .
.