Hi Morgan. After some tests, I’m back to you about this issue: the MASK tokens distribution (80% of 15% of tokens of each training and validation sequence) by your class MLMTokensLabels(Transform).
Are you sure that this MASK tokens distribution is calculated at Dataloaders level when batches are generated (that would be great as it would mean that at each batch generation, the MASK tokens distribution is changed) and not at Datasets level (that would mean that the MASK tokens distribution is calculated just one time and never changes)?
When I see the following code in your notebook, the time needed by running it and the files size (dsets and dls files), I think that the MASK tokens distribution is done just one time. What do you think?
@pierreguillou I think a new mask distribution is going to be called every batch as MLMTokensLabels.encodes called for each batch. And in each call to encodes we get a different masked_indices:
I’m pretty sure thats the case anyways, happy to be corrected if my thinking is fuzzy!
# Create random mask indices according to probability matrix
masked_indices = torch.bernoulli(probability_matrix).bool()
....
# Randomly replace with mask token
inputs, indices_replaced = self._replace_with_mask(inputs, labels, masked_indices)
I understand @morgan but let’s me explain why I’m still wondering what is happening.
I did check with the function dls.show_batch() that a same sequence appears with a different MASK tokens distribution each time I run this function (ie, each time a batch is created). One point for you
But, when I save my dls file (Dataloaders) through torch.save(dls, path_to_dls_file), its size is 6 Go when the training dataset has a size of 2Go. Why this gigantic size if dls is only a series of instructions to get batches of sequences?
On top of that, I remember that Jeremy had mentioned in a video that in order to avoid a break between the generation of batches (per CPU) and the speed of data processing at the input of the GPU, text transform processes of fastai are applied when the Datasets and Dataloaders are created (see your code in my post). This would mean that text transforms are applied just one time on sequences (with just a bit of randomness between sequences of similar length applies at batch generation time). But this point goes against the point 1, no?
special token_ids (ids of the tokens [CLS] and [SEP] in the case of BERT, for example) are added to the sequence of numericalized tokens by the object instantiated by the class AddSpecialTokens(Transform).
This operation is done in the Datasets creation by the following code:
My understanding is that the special tokens_ids are added before the sequence transformation to a sequence with MASK tokens by the object instantiated by the class MLMTokensLabels(). If it is correct, it means that the special tokens_ids can be replaced as well by the MASK token id.
What do you think? If I’m right, this could be a problem because BERT-like models are trained and used in production with sequences always with special tokens_ids.
dl_type=SortedDL
Do you think an efficient idea to shuffle the object instantiated by the class SortedDL, moving the code
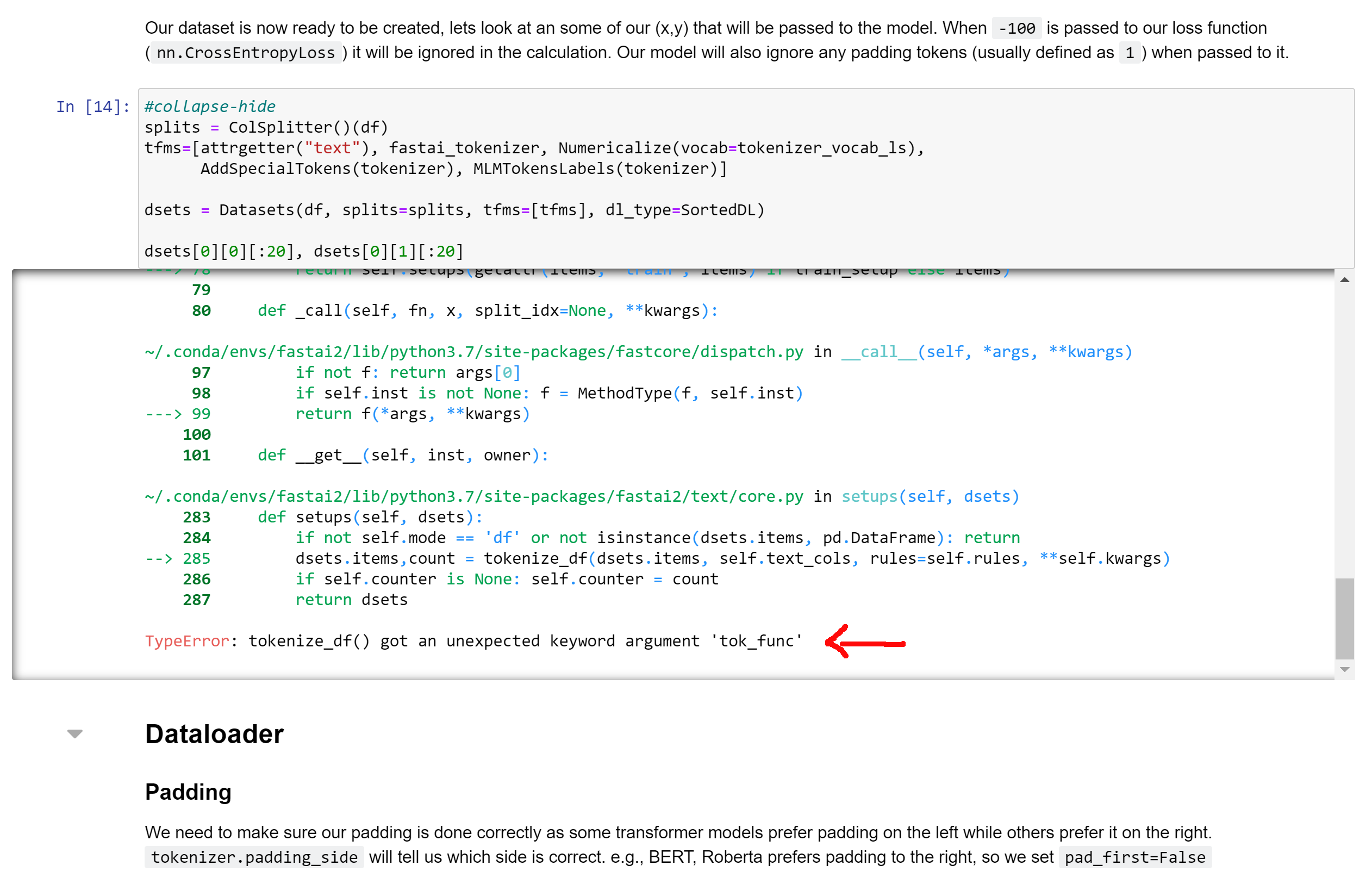
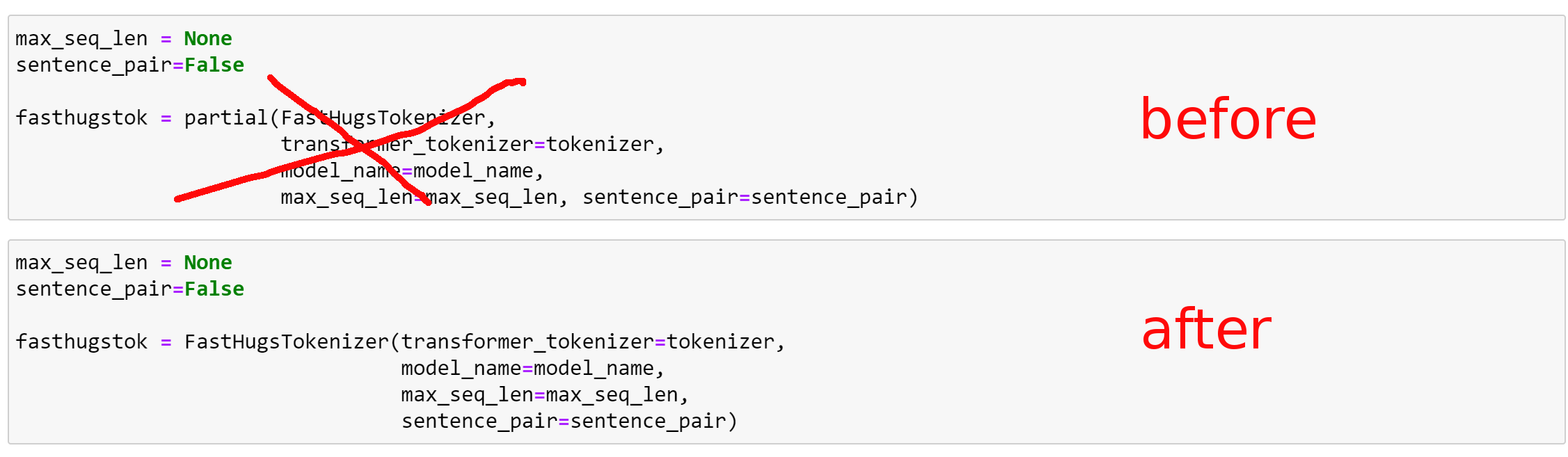
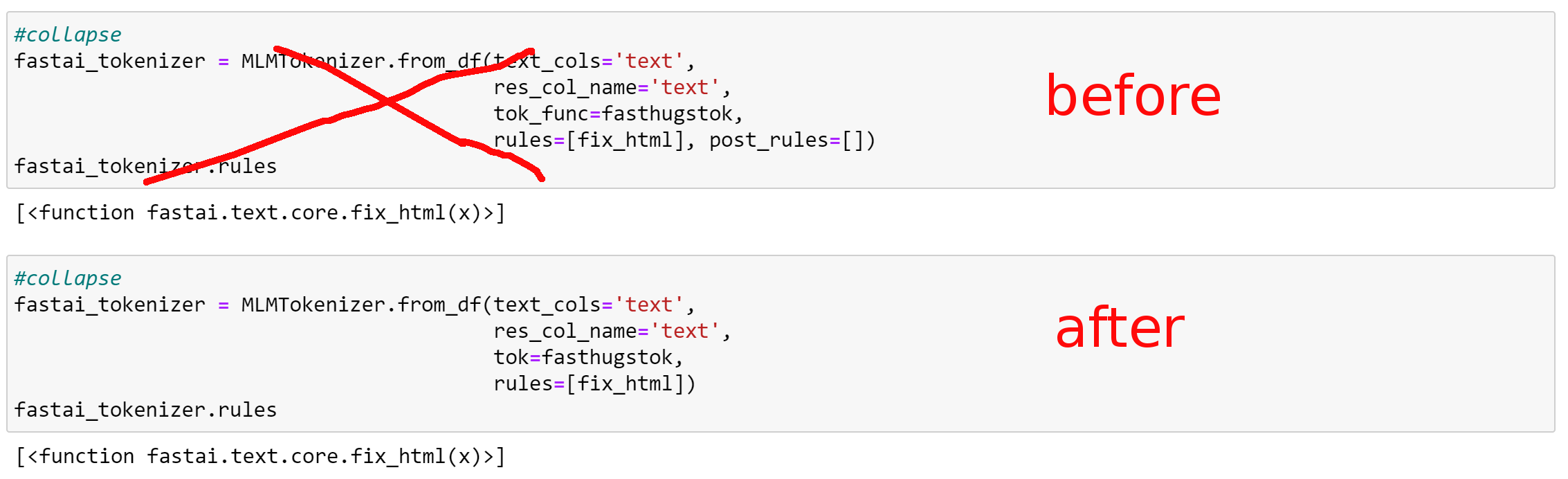
For example, I do not see how your class MLMTokenizer that inherits from the class Tokenizer can have a function fastai_tokenizer (MLMTokenizer.from_df) with arguments tok_func and post_rules: the function tokenize_df does not have these arguments but tok and rules (see my screen shots).
In the following screen shot, the error that comes from recent changes in fastai v2 libraries (I’m still searching where…) in your notebook 2020-04-24-fasthugs_language_model.ipynb:
I keep running into tons of errors around versioning. This code did not work with the latest versions of torch, fastai, and transformers. I downgraded to:
but it keeps breaking in several spots. Rather than go through each error, could you share what versions you are using of everything in your environment to get this to work?