I’m okay with this! Please help me make my code better ![]()
I think we’d have to do something like so:
def get_items(*_, **__): return data
Unless you’ve tested your get_items @radek? (also this was another idea of Lucas’)
I’m okay with this! Please help me make my code better ![]()
I think we’d have to do something like so:
def get_items(*_, **__): return data
Unless you’ve tested your get_items @radek? (also this was another idea of Lucas’)
The problem with this is that if fastai changes and instead start passing two args to get_items this breaks =/
Another option would be:
def get_items(*_, **__): return data
EDIT: @muellerzr was faster than me hahahah
Ideally, you want your code to break  You don’t want it functioning when something meaningful changes somewhere else.
You don’t want it functioning when something meaningful changes somewhere else.
Also, as a principle, your software shouldn’t rely on code that changes more often than your code does. Things that change more often should depend on things that change less often. Otherwise it becomes a very complex mess that is very hard to navigate.
In summary, I think I would want my code to break should fastai start passing some other parameter there. And also I am a strong believer, like really strong, that code is meant to be read. You don’t write code for the machine, but for the people who will read it. Here I would for sure go for the option that better clarifies your intention, which is imo the one I proposed.
Well, I’m going to mark all of that down in my course notebook. This is some super interesting opinion thanks!
@muellerzr, thank you for sharing baseline…
What I find interesting is that on windows I got terrible result not close to 0.7.
|epoch |train_loss |valid_loss |accuracy |time|
|0 |5.323863 |4.554179 |0.073006
|1 |4.312253 |4.180884 |0.048222
|2 |4.185628 |4.160336 |0.048222
|3 |4.140559 |4.150017 |0.058459
|4 |3.964385 |3.919490 |0.085129
I start to wonder what may be the cause? Mish???
just ignore the blog’s ugliness just experimenting it, too.
Biggest difference I see is you have some added augmentation (specific parameters in aug_transforms())
@muellerzr, The first results were with out modification… Thank you… I should try more combinations to reach the base line…
Could I please make a submission?  72.36% with only 2 res50 models
72.36% with only 2 res50 models
This result is maybe not all that interesting in itself, there are a couple of things that might be of interest.
I learned what sa stands for -> self attention (defined in layers.py).
I tried to run experiments in the notebook learning a bit how res50 would train, but after training 3 models (despite not saving anything) I would get an out of memory (OOM) error. I remember seeing some better way of going about this used by the fast.ai crew, but forgetting what that was I opted to reach out for google fire.
The idea is to run
bash run_experiments.sh | tee res50.txt
this will run the bash script to train the models and save output into a txt file. Unfortunately I had a bug in my experiment.py and need to rerun
I’m using nbdev, because for relatively that little code, I find it very helpful. It helps me DRY (do not repeat yourself) up my code.
I guess the interesting bit is doing the correlation matrix between results. If your models are less correlated, they do uncorrelated mistakes, you can hope for quite a score boost. Might be a nice way to figure out which models to combine.
Not sure if that was @muellerzr and @init_27 intention, but the techniques one can pick up when working on this can be quite helpful to getting one’s feet wet with kaggle, and probably to quite a good result
It was not, mostly meant for a straight average IE model 1 got 72%, model 2 got 74%, reported average is 73% with standard deviation of ~1 (probably less than that just mental numbers)
However, we could possibly ![]()
Nah, that is okay, so I got this wrong
In such a scenario is not clear why one wouldn’t want to just make a submission of a single, best scoring model
So that in general we know how the model performs and it’s not a one off.
Also the second post is a Wiki post ![]()
PS: Sorry about the weird delay, my phone was glitching and wouldn’t respond ![]()
How do you do that?
You train 2 models then at inference take the mean of both models predictions before applying XEloss?
Looks that way to me ![]()
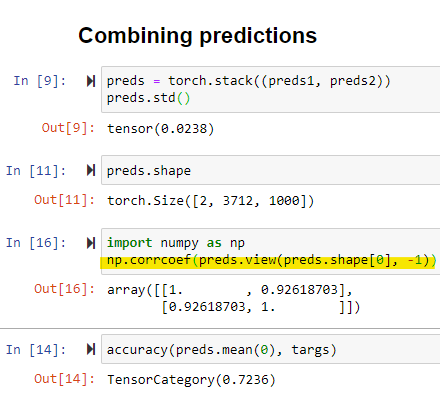
accuracy(preds.mean(0), targs)
(snippet from the end of the notebook)
Does “preds” is a concat of both model’s predictions?
Yes, see @radek’s bit on “Combining Predictions”
Which I might add, the covarience stuff is super cool!!!
Edit: I lied, it’s a torch.stack!
Sorry a did not see the notebook was provided 
Indeed he does a torch.stack of his preds. (damn 1000 classes to predict!)
How do you read that covariance matrix though?
Are we looking for bigger numbers in the covariance diagonal, meaning the 2 predictions are strongly correlated?
or do we want the opposite?
Do we compare the covariance at all to the Variances of the individual predictions?
{ Var(x) E[(x-E[x])(y-E[y])] }
{ E[(y-E[y])(x-E[x])] Var(y) }
(Sorry not latex fluent here, somehow numpy returns a flipped matrix with variances in the other diagonal)
Yes, this is just the mean of the predictions (probabilities outputted by softmax).
This is a correlation matrix. For anyone who might want to learn more about this, Jeremy covers covariance (and correlation) in p2 v3 here. I also prepared these quiz / notes if this should be helpful - link will likely stop working sometime this weekend.
Since correlation is covariance normalized to (-1, 1) , the diagonal is 1 (the values vary linearly perfectly in the same direction).
Looking at 2nd row first column
we have 0.93 - this is the correlation of the predictions of the second model with the first.
Ideally, for combining model output (ensembling) we want our models to perform well and their predictions to be as uncorrelated as possible (the lower the number the better). Ideally, we would like the models to err in an uncorrelated way. Their uncorrelated errors cancel out and we get better predictions.
For some models (Random Forest for instance) we use bagging and feature sampling to aim for this.
If pre-trained models are not allowed from the start, is there a loophole to instead try knowledge distillation?
Mainly asking since we’ve seen pretty great results (granted, on an unrelated task) by combining KD models trained at different resolutions, and think it’d be fun to apply here!
Thanks, I think that’s what I understood:
The areas where our models differ are the areas where it’s basically difficult to learn so taking their mean has a chance to cancel their errors.
In your linked notebook it’s still a covariance matrix:
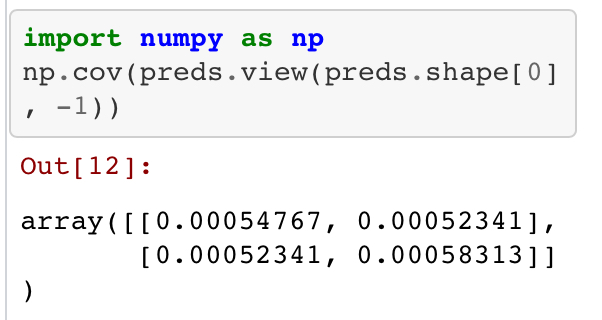
You are right, sorry, my bad.
Fixed it now (git push failed yesterday when I was working on this and didn’t notice it)