Sorry I introduced that bug here
Waiting on this issue to be addressed before I can push a fix
Sorry I introduced that bug here
Waiting on this issue to be addressed before I can push a fix
val_res fix submitted here now: https://github.com/fastai/fastai2/pull/435
well done, thanks.
Should be pushed now
Just noticed that WordTokenizer now calls SpacyTokenizer as the default tokenizer and passing lang to the Spacy Tokenizer is now no longer possible. Can we reinstate this, or add a kwargs argument to the init of WordTokenizer which then can be passed to SpacyTokenizer?
Or is there a new approach I should be taking when dealing with the default tokenizer and non-english text?
Specifically I’m using Tokenizer.from_df for Irish text (lang="ga") which would need a change like the below.
class Tokenizer(Transform):
"Provides a consistent `Transform` interface to tokenizers operating on `DataFrame`s and folders"
input_types = (str, list, L, tuple, Path)
def __init__(self, tok, rules=None, counter=None, lengths=None, mode=None, sep=' '):
store_attr(self, 'tok,counter,lengths,mode,sep')
self.rules = defaults.text_proc_rules if rules is None else rules
@classmethod
@delegates(tokenize_df, keep=True)
def from_df(cls, text_cols, tok=None, lang='en', rules=None, sep=' ', **kwargs): <--- ADDED lang
if tok is None: tok = WordTokenizer(lang=lang) <--- ADDED lang
res = cls(tok, rules=rules, mode='df')
res.kwargs,res.train_setup = merge({'tok': tok}, kwargs),False
res.text_cols,res.sep = text_cols,sep
return res
The new approach is to simply pass an instantiated tokenizer.
How did you end up resolving this?
Hi,
I am trying to build a seq2seq model with fastai2 (the example in the NLP course is still based on fastai v1), and I’m still stuck at the Dataloader creation…
I ran that the following lines (SEQ is the column with the input, TRG is the target column, each column has its own dictionary):
seq2seq = DataBlock(blocks=(TextBlock.from_df(SEQ, vocab=dbunch_lm.vocab, is_lm=False, seq_len=256),
TextBlock.from_df(TRG, vocab=dbunch_q3.vocab, is_lm=False, seq_len=256)),
get_x=ColReader('text'),
get_y=ColReader('text'),
splitter=RandomSplitter())
dbunch_seq2seq = seq2seq.dataloaders(df, path=path, bs=bs, verbose=True, seq_len=256)
And they ran without any error, but then, when I do show_batch(), I obtain the following error:
RuntimeError Traceback (most recent call last)
<ipython-input-84-5ffe658df9fc> in <module>
----> 1 dbunch_prot2prot.show_batch()
C:\ProgramData\Anaconda3\envs\fastai2\lib\site-packages\fastai2\data\core.py in show_batch(self, b, max_n, ctxs, show, unique, **kwargs)
95 old_get_idxs = self.get_idxs
96 self.get_idxs = lambda: Inf.zeros
---> 97 if b is None: b = self.one_batch()
98 if not show: return self._pre_show_batch(b, max_n=max_n)
99 show_batch(*self._pre_show_batch(b, max_n=max_n), ctxs=ctxs, max_n=max_n, **kwargs)
C:\ProgramData\Anaconda3\envs\fastai2\lib\site-packages\fastai2\data\load.py in one_batch(self)
130 def one_batch(self):
131 if self.n is not None and len(self)==0: raise ValueError(f'This DataLoader does not contain any batches')
--> 132 with self.fake_l.no_multiproc(): res = first(self)
133 if hasattr(self, 'it'): delattr(self, 'it')
134 return res
C:\ProgramData\Anaconda3\envs\fastai2\lib\site-packages\fastcore\utils.py in first(x)
189 def first(x):
190 "First element of `x`, or None if missing"
--> 191 try: return next(iter(x))
192 except StopIteration: return None
193
C:\ProgramData\Anaconda3\envs\fastai2\lib\site-packages\fastai2\data\load.py in __iter__(self)
96 self.randomize()
97 self.before_iter()
---> 98 for b in _loaders[self.fake_l.num_workers==0](self.fake_l):
99 if self.device is not None: b = to_device(b, self.device)
100 yield self.after_batch(b)
C:\ProgramData\Anaconda3\envs\fastai2\lib\site-packages\torch\utils\data\dataloader.py in __next__(self)
361
362 def __next__(self):
--> 363 data = self._next_data()
364 self._num_yielded += 1
365 if self._dataset_kind == _DatasetKind.Iterable and \
C:\ProgramData\Anaconda3\envs\fastai2\lib\site-packages\torch\utils\data\dataloader.py in _next_data(self)
401 def _next_data(self):
402 index = self._next_index() # may raise StopIteration
--> 403 data = self._dataset_fetcher.fetch(index) # may raise StopIteration
404 if self._pin_memory:
405 data = _utils.pin_memory.pin_memory(data)
C:\ProgramData\Anaconda3\envs\fastai2\lib\site-packages\torch\utils\data\_utils\fetch.py in fetch(self, possibly_batched_index)
32 raise StopIteration
33 else:
---> 34 data = next(self.dataset_iter)
35 return self.collate_fn(data)
36
C:\ProgramData\Anaconda3\envs\fastai2\lib\site-packages\fastai2\data\load.py in create_batches(self, samps)
105 self.it = iter(self.dataset) if self.dataset is not None else None
106 res = filter(lambda o:o is not None, map(self.do_item, samps))
--> 107 yield from map(self.do_batch, self.chunkify(res))
108
109 def new(self, dataset=None, cls=None, **kwargs):
C:\ProgramData\Anaconda3\envs\fastai2\lib\site-packages\fastai2\data\load.py in do_batch(self, b)
126 def create_item(self, s): return next(self.it) if s is None else self.dataset[s]
127 def create_batch(self, b): return (fa_collate,fa_convert)[self.prebatched](b)
--> 128 def do_batch(self, b): return self.retain(self.create_batch(self.before_batch(b)), b)
129 def to(self, device): self.device = device
130 def one_batch(self):
C:\ProgramData\Anaconda3\envs\fastai2\lib\site-packages\fastai2\data\load.py in create_batch(self, b)
125 def retain(self, res, b): return retain_types(res, b[0] if is_listy(b) else b)
126 def create_item(self, s): return next(self.it) if s is None else self.dataset[s]
--> 127 def create_batch(self, b): return (fa_collate,fa_convert)[self.prebatched](b)
128 def do_batch(self, b): return self.retain(self.create_batch(self.before_batch(b)), b)
129 def to(self, device): self.device = device
C:\ProgramData\Anaconda3\envs\fastai2\lib\site-packages\fastai2\data\load.py in fa_collate(t)
44 b = t[0]
45 return (default_collate(t) if isinstance(b, _collate_types)
---> 46 else type(t[0])([fa_collate(s) for s in zip(*t)]) if isinstance(b, Sequence)
47 else default_collate(t))
48
C:\ProgramData\Anaconda3\envs\fastai2\lib\site-packages\fastai2\data\load.py in <listcomp>(.0)
44 b = t[0]
45 return (default_collate(t) if isinstance(b, _collate_types)
---> 46 else type(t[0])([fa_collate(s) for s in zip(*t)]) if isinstance(b, Sequence)
47 else default_collate(t))
48
C:\ProgramData\Anaconda3\envs\fastai2\lib\site-packages\fastai2\data\load.py in fa_collate(t)
43 def fa_collate(t):
44 b = t[0]
---> 45 return (default_collate(t) if isinstance(b, _collate_types)
46 else type(t[0])([fa_collate(s) for s in zip(*t)]) if isinstance(b, Sequence)
47 else default_collate(t))
C:\ProgramData\Anaconda3\envs\fastai2\lib\site-packages\torch\utils\data\_utils\collate.py in default_collate(batch)
53 storage = elem.storage()._new_shared(numel)
54 out = elem.new(storage)
---> 55 return torch.stack(batch, 0, out=out)
56 elif elem_type.__module__ == 'numpy' and elem_type.__name__ != 'str_' \
57 and elem_type.__name__ != 'string_':
RuntimeError: stack expects each tensor to be equal size, but got [1188] at entry 0 and [1488] at entry 1
Does anyone know what’s the issue? In general, did someone publish a seq2seq example notebook (e.g. translation) with fastai2?
Thanks for any help!!
I’ve got a couple of transformer notebooks here if you’d like a look, it’s using fastai v2 and the PyTorch nn.Transformer implementation. Dataloader code might be useful too
Hi, I just started using SentencePiece, and I’m facing errors while trying to infer:
----> 1 test_dl = learn.dls.test_dl(test_items=test_df['text'], verbose=True)
21 frames
/usr/local/lib/python3.6/dist-packages/fastai2/data/core.py in test_dl(self, test_items, rm_type_tfms, with_labels, **kwargs)
356 test_ds = test_set(self.valid_ds, test_items, rm_tfms=rm_type_tfms, with_labels=with_labels
357 ) if isinstance(self.valid_ds, (Datasets, TfmdLists)) else test_items
--> 358 return self.valid.new(test_ds, **kwargs)
/usr/local/lib/python3.6/dist-packages/fastai2/text/data.py in new(self, dataset, **kwargs)
186 if 'val_res' in kwargs: res = kwargs['val_res']
187 else: res = self.res if dataset is None else None
--> 188 return super().new(dataset=dataset, res=res, **kwargs)
189
190 # Cell
/usr/local/lib/python3.6/dist-packages/fastai2/data/core.py in new(self, dataset, cls, **kwargs)
59 @delegates(DataLoader.new)
60 def new(self, dataset=None, cls=None, **kwargs):
---> 61 res = super().new(dataset, cls, do_setup=False, **kwargs)
62 if not hasattr(self, '_n_inp') or not hasattr(self, '_types'):
63 try:
/usr/local/lib/python3.6/dist-packages/fastai2/data/load.py in new(self, dataset, cls, **kwargs)
113 bs=self.bs, shuffle=self.shuffle, drop_last=self.drop_last, indexed=self.indexed, device=self.device)
114 for n in self._methods: cur_kwargs[n] = getattr(self, n)
--> 115 return cls(**merge(cur_kwargs, kwargs))
116
117 @property
/usr/local/lib/python3.6/dist-packages/fastai2/text/data.py in __init__(self, dataset, sort_func, res, **kwargs)
159 self.sort_func = _default_sort if sort_func is None else sort_func
160 if res is None and self.sort_func == _default_sort: res = _get_lengths(dataset)
--> 161 self.res = [self.sort_func(self.do_item(i)) for i in range_of(self.dataset)] if res is None else res
162 if len(self.res) > 0: self.idx_max = np.argmax(self.res)
163
/usr/local/lib/python3.6/dist-packages/fastai2/text/data.py in <listcomp>(.0)
159 self.sort_func = _default_sort if sort_func is None else sort_func
160 if res is None and self.sort_func == _default_sort: res = _get_lengths(dataset)
--> 161 self.res = [self.sort_func(self.do_item(i)) for i in range_of(self.dataset)] if res is None else res
162 if len(self.res) > 0: self.idx_max = np.argmax(self.res)
163
/usr/local/lib/python3.6/dist-packages/fastai2/data/load.py in do_item(self, s)
118 def prebatched(self): return self.bs is None
119 def do_item(self, s):
--> 120 try: return self.after_item(self.create_item(s))
121 except SkipItemException: return None
122 def chunkify(self, b): return b if self.prebatched else chunked(b, self.bs, self.drop_last)
/usr/local/lib/python3.6/dist-packages/fastai2/data/load.py in create_item(self, s)
124 def randomize(self): self.rng = random.Random(self.rng.randint(0,2**32-1))
125 def retain(self, res, b): return retain_types(res, b[0] if is_listy(b) else b)
--> 126 def create_item(self, s): return next(self.it) if s is None else self.dataset[s]
127 def create_batch(self, b): return (fa_collate,fa_convert)[self.prebatched](b)
128 def do_batch(self, b): return self.retain(self.create_batch(self.before_batch(b)), b)
/usr/local/lib/python3.6/dist-packages/fastai2/data/core.py in __getitem__(self, it)
287
288 def __getitem__(self, it):
--> 289 res = tuple([tl[it] for tl in self.tls])
290 return res if is_indexer(it) else list(zip(*res))
291
/usr/local/lib/python3.6/dist-packages/fastai2/data/core.py in <listcomp>(.0)
287
288 def __getitem__(self, it):
--> 289 res = tuple([tl[it] for tl in self.tls])
290 return res if is_indexer(it) else list(zip(*res))
291
/usr/local/lib/python3.6/dist-packages/fastai2/data/core.py in __getitem__(self, idx)
264 res = super().__getitem__(idx)
265 if self._after_item is None: return res
--> 266 return self._after_item(res) if is_indexer(idx) else res.map(self._after_item)
267
268 # Cell
/usr/local/lib/python3.6/dist-packages/fastai2/data/core.py in _after_item(self, o)
227 return super()._new(items, tfms=self.tfms, do_setup=False, types=self.types, split_idx=split_idx, **kwargs)
228 def subset(self, i): return self._new(self._get(self.splits[i]), split_idx=i)
--> 229 def _after_item(self, o): return self.tfms(o)
230 def __repr__(self): return f"{self.__class__.__name__}: {self.items}\ntfms - {self.tfms.fs}"
231 def __iter__(self): return (self[i] for i in range(len(self)))
/usr/local/lib/python3.6/dist-packages/fastcore/transform.py in __call__(self, o)
200 self.fs.append(t)
201
--> 202 def __call__(self, o): return compose_tfms(o, tfms=self.fs, split_idx=self.split_idx)
203 def __repr__(self): return f"Pipeline: {' -> '.join([f.name for f in self.fs if f.name != 'noop'])}"
204 def __getitem__(self,i): return self.fs[i]
/usr/local/lib/python3.6/dist-packages/fastcore/transform.py in compose_tfms(x, tfms, is_enc, reverse, **kwargs)
153 for f in tfms:
154 if not is_enc: f = f.decode
--> 155 x = f(x, **kwargs)
156 return x
157
/usr/local/lib/python3.6/dist-packages/fastcore/transform.py in __call__(self, x, **kwargs)
70 @property
71 def name(self): return getattr(self, '_name', _get_name(self))
---> 72 def __call__(self, x, **kwargs): return self._call('encodes', x, **kwargs)
73 def decode (self, x, **kwargs): return self._call('decodes', x, **kwargs)
74 def __repr__(self): return f'{self.name}:\nencodes: {self.encodes}decodes: {self.decodes}'
/usr/local/lib/python3.6/dist-packages/fastcore/transform.py in _call(self, fn, x, split_idx, **kwargs)
80 def _call(self, fn, x, split_idx=None, **kwargs):
81 if split_idx!=self.split_idx and self.split_idx is not None: return x
---> 82 return self._do_call(getattr(self, fn), x, **kwargs)
83
84 def _do_call(self, f, x, **kwargs):
/usr/local/lib/python3.6/dist-packages/fastcore/transform.py in _do_call(self, f, x, **kwargs)
86 if f is None: return x
87 ret = f.returns_none(x) if hasattr(f,'returns_none') else None
---> 88 return retain_type(f(x, **kwargs), x, ret)
89 res = tuple(self._do_call(f, x_, **kwargs) for x_ in x)
90 return retain_type(res, x)
/usr/local/lib/python3.6/dist-packages/fastcore/dispatch.py in __call__(self, *args, **kwargs)
97 if not f: return args[0]
98 if self.inst is not None: f = MethodType(f, self.inst)
---> 99 return f(*args, **kwargs)
100
101 def __get__(self, inst, owner):
/usr/local/lib/python3.6/dist-packages/fastai2/text/core.py in encodes(self, o)
295 else: return self._tokenize1(o.read())
296
--> 297 def encodes(self, o:str): return self._tokenize1(o)
298 def _tokenize1(self, o): return first(self.tokenizer([compose(*self.rules)(o)]))
299
/usr/local/lib/python3.6/dist-packages/fastai2/text/core.py in _tokenize1(self, o)
296
297 def encodes(self, o:str): return self._tokenize1(o)
--> 298 def _tokenize1(self, o): return first(self.tokenizer([compose(*self.rules)(o)]))
299
300 def get_lengths(self, items):
/usr/local/lib/python3.6/dist-packages/fastcore/utils.py in first(x)
189 def first(x):
190 "First element of `x`, or None if missing"
--> 191 try: return next(iter(x))
192 except StopIteration: return None
193
/usr/local/lib/python3.6/dist-packages/fastai2/text/core.py in __call__(self, items)
372
373 def __call__(self, items):
--> 374 for t in items: yield self.tok.EncodeAsPieces(t)
375
376 # Cell
AttributeError: 'NoneType' object has no attribute 'EncodeAsPieces'
Is there an extra argument I’m missing?
This is the training DataBlock:
blocks = (TextBlock.from_df('text', seq_len=dls_sp.seq_len, vocab=dls_sp.vocab, tok_func=SentencePieceTokenizer), CategoryBlock())
clas = DataBlock(blocks=blocks,
get_x=ColReader('text'),
get_y=ColReader('Category'),
splitter=RandomSplitter(valid_pct=0.2, seed=108))
dls_clas = clas.dataloaders(train_df, bs=64)
fastai2 0.0.20
sentencepiece-0.1.86Thanks a lot Morgan! Indeed, I used your dataloaders and now, the show_batch seems to work.
However, I see that different batches have different shapes. Is this logical?
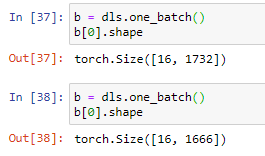
Yep this should be expected, the padding function only pads to the longest sequence in the batch. So I guess the longest sequence in the first batch is 1732 long, the second is 1666.
Side note, those sequence lengths are quite long for plain vanilla transformers, maybe you’d want to break them up into shorter ones if you can? (Longformer and Reformer are two transformer examples you can find in Huggingface’s transformers library that can deal with longer sequence lengths)
I saw this reported in another thread and Jeremy mentioned that he had fixed it in master (like 5 days ago), can you make sure you have the latest version of master?
That’s a very good point, and it is actually another thing that I don’t understand… Just to give a bit more context, I am using this Kaggle dataset, where:
Therefore, I really don’t see why the sequences would be so long… Any idea? I think it may be due to the fact that the padding doesn’t account for word repetitions, but I’m not sure.
Can you share your dataloader code?
I see from the histograms on the Kaggle data page that some sequences can be up to 1632 letters long (for the subset kaggle is showing). Are you just selecting sequences that are up to 128 from your dataset? If so then maybe you are missing something that is letting the longer sequences sneak by and into your dataloader…
(I don’t have a clue about proteins etc, but I find the topic really interesting, what would be the end use case of doing predictions like this?)
My apologies, you are totally right! Thought I filtered out the sequences of more than 128 but I actually didn’t. I’ve now managed to get to the point where I started fitting the model. It doesn’t give good results yet, but I have a few ideas why and how to improve.
I will send you a private message to tell you more about the project. Happy to collaborate if this sounds interesting to you !!
Thanks again for your help
fastai2-0.0.25
fastcore-0.1.30
sentencepiece-0.1.86
I’m seeing a slightly different error now. Previous one was with fastai2 0.0.20
AttributeError Traceback (most recent call last)
<ipython-input-13-bc4424e25113> in <module>()
----> 1 test_dl = learn.dls.test_dl(test_items=test_df['text'], verbose=True)
19 frames
/usr/local/lib/python3.6/dist-packages/fastai2/data/core.py in test_dl(self, test_items, rm_type_tfms, with_labels, **kwargs)
360 test_ds = test_set(self.valid_ds, test_items, rm_tfms=rm_type_tfms, with_labels=with_labels
361 ) if isinstance(self.valid_ds, (Datasets, TfmdLists)) else test_items
--> 362 return self.valid.new(test_ds, **kwargs)
/usr/local/lib/python3.6/dist-packages/fastai2/text/data.py in new(self, dataset, **kwargs)
186 if 'val_res' in kwargs and kwargs['val_res'] is not None: res = kwargs['val_res']
187 else: res = self.res if dataset is None else None
--> 188 return super().new(dataset=dataset, res=res, **kwargs)
189
190 # Cell
/usr/local/lib/python3.6/dist-packages/fastai2/data/core.py in new(self, dataset, cls, **kwargs)
62 @delegates(DataLoader.new)
63 def new(self, dataset=None, cls=None, **kwargs):
---> 64 res = super().new(dataset, cls, do_setup=False, **kwargs)
65 if not hasattr(self, '_n_inp') or not hasattr(self, '_types'):
66 try:
/usr/local/lib/python3.6/dist-packages/fastai2/data/load.py in new(self, dataset, cls, **kwargs)
113 bs=self.bs, shuffle=self.shuffle, drop_last=self.drop_last, indexed=self.indexed, device=self.device)
114 for n in self._methods: cur_kwargs[n] = getattr(self, n)
--> 115 return cls(**merge(cur_kwargs, kwargs))
116
117 @property
/usr/local/lib/python3.6/dist-packages/fastai2/text/data.py in __init__(self, dataset, sort_func, res, **kwargs)
159 self.sort_func = _default_sort if sort_func is None else sort_func
160 if res is None and self.sort_func == _default_sort: res = _get_lengths(dataset)
--> 161 self.res = [self.sort_func(self.do_item(i)) for i in range_of(self.dataset)] if res is None else res
162 if len(self.res) > 0: self.idx_max = np.argmax(self.res)
163
/usr/local/lib/python3.6/dist-packages/fastai2/text/data.py in <listcomp>(.0)
159 self.sort_func = _default_sort if sort_func is None else sort_func
160 if res is None and self.sort_func == _default_sort: res = _get_lengths(dataset)
--> 161 self.res = [self.sort_func(self.do_item(i)) for i in range_of(self.dataset)] if res is None else res
162 if len(self.res) > 0: self.idx_max = np.argmax(self.res)
163
/usr/local/lib/python3.6/dist-packages/fastai2/data/load.py in do_item(self, s)
118 def prebatched(self): return self.bs is None
119 def do_item(self, s):
--> 120 try: return self.after_item(self.create_item(s))
121 except SkipItemException: return None
122 def chunkify(self, b): return b if self.prebatched else chunked(b, self.bs, self.drop_last)
/usr/local/lib/python3.6/dist-packages/fastai2/data/load.py in create_item(self, s)
124 def randomize(self): self.rng = random.Random(self.rng.randint(0,2**32-1))
125 def retain(self, res, b): return retain_types(res, b[0] if is_listy(b) else b)
--> 126 def create_item(self, s): return next(self.it) if s is None else self.dataset[s]
127 def create_batch(self, b): return (fa_collate,fa_convert)[self.prebatched](b)
128 def do_batch(self, b): return self.retain(self.create_batch(self.before_batch(b)), b)
/usr/local/lib/python3.6/dist-packages/fastai2/data/core.py in __getitem__(self, it)
291
292 def __getitem__(self, it):
--> 293 res = tuple([tl[it] for tl in self.tls])
294 return res if is_indexer(it) else list(zip(*res))
295
/usr/local/lib/python3.6/dist-packages/fastai2/data/core.py in <listcomp>(.0)
291
292 def __getitem__(self, it):
--> 293 res = tuple([tl[it] for tl in self.tls])
294 return res if is_indexer(it) else list(zip(*res))
295
/usr/local/lib/python3.6/dist-packages/fastai2/data/core.py in __getitem__(self, idx)
268 res = super().__getitem__(idx)
269 if self._after_item is None: return res
--> 270 return self._after_item(res) if is_indexer(idx) else res.map(self._after_item)
271
272 # Cell
/usr/local/lib/python3.6/dist-packages/fastai2/data/core.py in _after_item(self, o)
230 return super()._new(items, tfms=self.tfms, do_setup=False, types=self.types, split_idx=split_idx, **kwargs)
231 def subset(self, i): return self._new(self._get(self.splits[i]), split_idx=i)
--> 232 def _after_item(self, o): return self.tfms(o)
233 def __repr__(self): return f"{self.__class__.__name__}: {self.items}\ntfms - {self.tfms.fs}"
234 def __iter__(self): return (self[i] for i in range(len(self)))
/usr/local/lib/python3.6/dist-packages/fastcore/transform.py in __call__(self, o)
200 self.fs.append(t)
201
--> 202 def __call__(self, o): return compose_tfms(o, tfms=self.fs, split_idx=self.split_idx)
203 def __repr__(self): return f"Pipeline: {' -> '.join([f.name for f in self.fs if f.name != 'noop'])}"
204 def __getitem__(self,i): return self.fs[i]
/usr/local/lib/python3.6/dist-packages/fastcore/transform.py in compose_tfms(x, tfms, is_enc, reverse, **kwargs)
153 for f in tfms:
154 if not is_enc: f = f.decode
--> 155 x = f(x, **kwargs)
156 return x
157
/usr/local/lib/python3.6/dist-packages/fastcore/transform.py in __call__(self, x, **kwargs)
70 @property
71 def name(self): return getattr(self, '_name', _get_name(self))
---> 72 def __call__(self, x, **kwargs): return self._call('encodes', x, **kwargs)
73 def decode (self, x, **kwargs): return self._call('decodes', x, **kwargs)
74 def __repr__(self): return f'{self.name}:\nencodes: {self.encodes}decodes: {self.decodes}'
/usr/local/lib/python3.6/dist-packages/fastcore/transform.py in _call(self, fn, x, split_idx, **kwargs)
80 def _call(self, fn, x, split_idx=None, **kwargs):
81 if split_idx!=self.split_idx and self.split_idx is not None: return x
---> 82 return self._do_call(getattr(self, fn), x, **kwargs)
83
84 def _do_call(self, f, x, **kwargs):
/usr/local/lib/python3.6/dist-packages/fastcore/transform.py in _do_call(self, f, x, **kwargs)
86 if f is None: return x
87 ret = f.returns_none(x) if hasattr(f,'returns_none') else None
---> 88 return retain_type(f(x, **kwargs), x, ret)
89 res = tuple(self._do_call(f, x_, **kwargs) for x_ in x)
90 return retain_type(res, x)
/usr/local/lib/python3.6/dist-packages/fastcore/dispatch.py in __call__(self, *args, **kwargs)
97 if not f: return args[0]
98 if self.inst is not None: f = MethodType(f, self.inst)
---> 99 return f(*args, **kwargs)
100
101 def __get__(self, inst, owner):
/usr/local/lib/python3.6/dist-packages/fastai2/text/core.py in encodes(self, o)
292 else: return self._tokenize1(o.read())
293
--> 294 def encodes(self, o:str): return self._tokenize1(o)
295 def _tokenize1(self, o): return first(self.tok([compose(*self.rules)(o)]))
296
/usr/local/lib/python3.6/dist-packages/fastai2/text/core.py in _tokenize1(self, o)
293
294 def encodes(self, o:str): return self._tokenize1(o)
--> 295 def _tokenize1(self, o): return first(self.tok([compose(*self.rules)(o)]))
296
297 def get_lengths(self, items):
AttributeError: 'Tokenizer' object has no attribute 'tok'
=============================================================
I am now trying to create DataBlock with fastai2 0.0.25 for SentencePiece, and I’m seeing this error:
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-5-31c08ee3d74f> in <module>()
----> 1 imdb = DataBlock(blocks=(TextBlock.from_folder(path, tok=SentencePieceTokenizer), CategoryBlock),
2 get_items=get_text_files,
3 get_y=parent_label,
4 splitter=GrandparentSplitter(valid_name='test'))
5 frames
/usr/local/lib/python3.6/dist-packages/fastai2/text/data.py in from_folder(cls, path, vocab, is_lm, seq_len, backwards, min_freq, max_vocab, **kwargs)
210 def from_folder(cls, path, vocab=None, is_lm=False, seq_len=72, backwards=False, min_freq=3, max_vocab=60000, **kwargs):
211 "Build a `TextBlock` from a `path`"
--> 212 return cls(Tokenizer.from_folder(path, **kwargs), vocab=vocab, is_lm=is_lm, seq_len=seq_len,
213 backwards=backwards, min_freq=min_freq, max_vocab=max_vocab)
214
/usr/local/lib/python3.6/dist-packages/fastai2/text/core.py in from_folder(cls, path, tok, rules, **kwargs)
274 path = Path(path)
275 if tok is None: tok = WordTokenizer()
--> 276 output_dir = tokenize_folder(path, tok=tok, rules=rules, **kwargs)
277 res = cls(tok, counter=(output_dir/fn_counter_pkl).load(),
278 lengths=(output_dir/fn_lengths_pkl).load(), rules=rules, mode='folder')
/usr/local/lib/python3.6/dist-packages/fastai2/text/core.py in tokenize_folder(path, extensions, folders, output_dir, skip_if_exists, **kwargs)
182 files = get_files(path, extensions=extensions, recurse=True, folders=folders)
183 def _f(i,output_dir): return output_dir/files[i].relative_to(path)
--> 184 return _tokenize_files(_f, files, path, skip_if_exists=skip_if_exists, **kwargs)
185
186 # Cell
/usr/local/lib/python3.6/dist-packages/fastai2/text/core.py in _tokenize_files(func, files, path, output_dir, output_names, n_workers, rules, tok, encoding, skip_if_exists)
165
166 lengths,counter = {},Counter()
--> 167 for i,tok in parallel_tokenize(files, tok, rules, n_workers=n_workers):
168 out = func(i,output_dir)
169 out.write(' '.join(tok))
/usr/local/lib/python3.6/dist-packages/fastai2/text/core.py in parallel_tokenize(items, tok, rules, n_workers, **kwargs)
146 "Calls optional `setup` on `tok` before launching `TokenizeWithRules` using `parallel_gen"
147 if tok is None: tok = WordTokenizer()
--> 148 if hasattr(tok, 'setup'): tok.setup(items, rules)
149 return parallel_gen(TokenizeWithRules, items, tok=tok, rules=rules, n_workers=n_workers, **kwargs)
150
/usr/local/lib/python3.6/dist-packages/fastai2/text/core.py in setup(self, items, rules)
355 from sentencepiece import SentencePieceProcessor
356 if rules is None: rules = []
--> 357 if self.tok is not None: return {'sp_model': self.sp_model}
358 raw_text_path = self.cache_dir/'texts.out'
359 with open(raw_text_path, 'w') as f:
AttributeError: 'L' object has no attribute 'tok'
Opened an issue for this.
Thanks for the info @muellerzr
recently I am having a similar idea for porting AWD-LSTM as ONNX. could you share more on why it doesn’t work? Does it have something to do with the custom dropout classes (e.g. WeightDropout, RNNDropout … etc.) fastai has made for AWD-LSTM?
Hi,
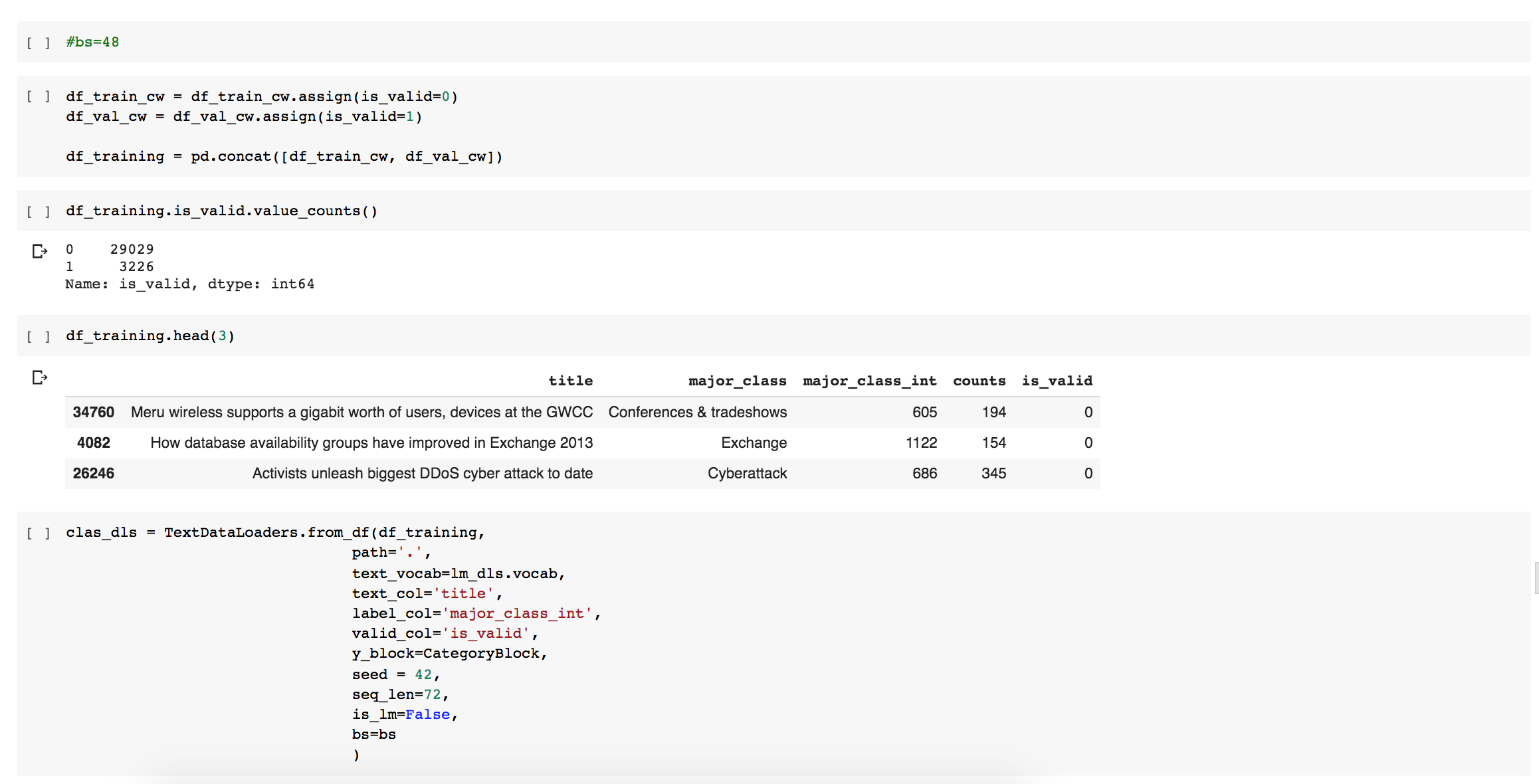
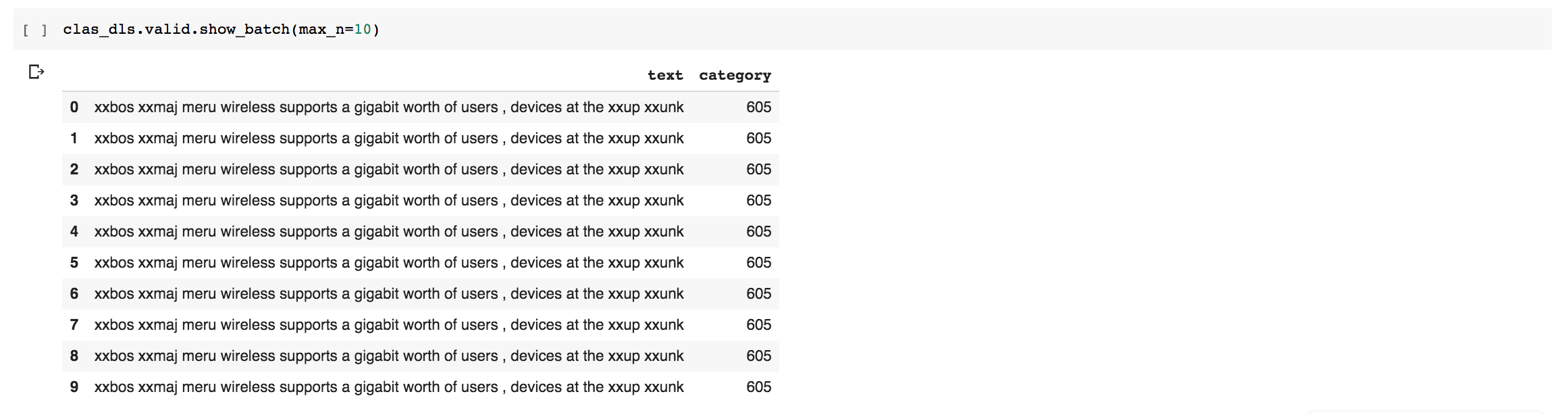
I’ve spotted some unexpected behaviour with TextDataLoaders and wanted to flag it up. Apologies if this is old news. This is also my first time posting here and I can only pass one image per post. I will try attaching images to subsequent posts.
If you look here, you’ll see I pass in a value for the ‘valid_col’ - this seems to break this dataloader.
It results in only having a single row repeated throughout the validation set (the training set is fine).
It doesn’t matter if the contents of that column are a string or int, only if it’s passed in as an argument. If I comment it out, it works fine.
The documentation shows that this valid can be passed in as an argument so it took me a while to figure that this was the problem!