Could this architecture be something for fastai v2?
If, I’m happy to contribute! ![]()
Could this architecture be something for fastai v2?
If, I’m happy to contribute! ![]()
Yes we’re certainly planning to look into that architecture. The most useful contribution for us (and I think a very useful contribution to the global deep learning community) would be an investigation into how well it works with ULMFiT on the IMDb dataset.
(In general, writing code isn’t the thing that takes us time - but rather figuring out what code to write. i.e. we try to curate the best ways to do things in fastai, and figuring out what’s best is not easy!)
Great, next week I have time to start with the model and then look into ULMFiT with it! ![]()
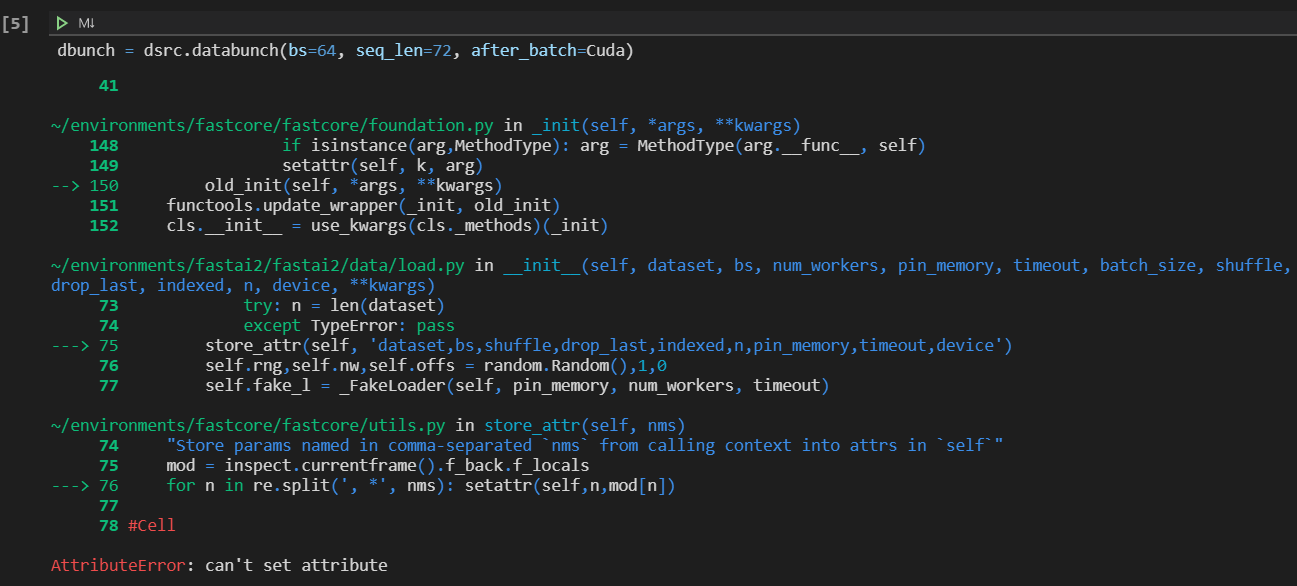
It’s an error with the most recent two commits. Use a version before it for now 
Thanks @muellerzr
I have a problem when using learner.predict, when the item is a pandas data frame. I solve the problem by removing the around ‘item’ in the predict function as below:
> def predict(self, item, rm_type_tfms=0):
dl = test_dl(self.dbunch, [item], rm_type_tfms=rm_type_tfms) inp,preds,_,dec_preds = self.get_preds(dl=dl, with_input=True, with_decoded=True) i = getattr(self.dbunch, 'n_inp', -1) full_dec = self.dbunch.decode_batch((*tuplify(inp),*tuplify(dec_preds)))[0][i:] return detuplify(full_dec),dec_preds[0],preds[0]
It seems “[item]” works for a list or similar, but not for pandas data frame. Could you have a look?
Predict is supposed to work on one item. If you have a dataframe, you have several items so you should be using get_preds after building a new dl with test_dl. Predict should work on one row of the dataframe, but not on the whole.
Yes, I see. but when I use most simple way like below:
dl = test_dl(dbunch, [tensor([2.])], rm_type_tfms=0)
my dbunch is based on
dsrc = DataSource(df_tok, splits=splits, tfms=[
[attrgetter(“text”), Numericalize(vocab)],
[attrgetter(“rating”), Categorize()]], dl_type=SortedDL)dbunch = dsrc.databunch(before_batch=partial(pad_input,pad_idx=pad_idx,pad_first=pad_first), after_batch=Cuda, bs=64)
I got an error:
‘Tensor’ object has no attribute ‘text’
Seems learn.predict still not work with text.
Yi Fan
It does, but look at the examples. Predict does not work on a tensor but on a tokenized text, and you will have to add rm_type_tfms=1 since you have a transform attrgetter(“text”) in your DataSource (so it will try to grab the attribute text).
If you’re confident you have the right tensor with numbers, you can pass rm_type_tfms=2 (which will remove the attrgetter and the numericalize).
@sgugger, great, now I fully understand the meaning of rm_type_tfms.
Thanks.
Hi, I am trying to implement machine translation in v2, and extend it with a pretrained LM. I am wondering what the best approach is to tokenize both source and target language in a df.
I was thinking of doing something like
df_tok,count = tokenize_df(df, “en”)
df_tok,count_fr = tokenize_df(df_tok, “fr”)
but then, in the second call the function overwrites the “text” column. I could add a param to tokenize_df that specifies the output column name. Would that work with the rest of the pipeline? I am not that familiar with v2 yet.
Why are you tokenizing the same texts in english and french? It sounds like you need to pass along a different column in your second call to tokenize_df.
I think I am missing something. The second argument is specifying the column right? And it is different in the second call
Ah yes, sorry I didn’t read your code properly. Yes I’ll had an arg for the column name for the tokenized results (will default to "text") so you can customize it.
Hello, sorry if this is too early to ask, but is there a way to use transformers in Fastai V2?
I found this excellent article on using transformers with V1 but was curious if there is a way to use with V2, thanks!
I simply want to use a GPT-2 tokenizer from the hugging face library using fastai v2
@arora_aman from what I can see here: https://github.com/fastai/fastai2/blob/master/nbs/33_text.models.core.ipynb it looks like they intend to but it’s not quite done yet!
The plan is ultimately to make it easy to use the transformers library yes (as easy as torchvision models in vision). I didn’t get any time to work on that yet so you will have to wait a few weeks before this lands.
Thank you very much for all the excellent work at fastai and at the same time for finding the time for the forums
Hello, is there any plan to add NER models to fastai2?
A commonly used architecture for this task is a bi-LSTM with a conditional random field (CRF) layer added onto the end. Writing the CRF logic is pretty straightforward, but I am not sure how difficult these things would be: (1) modifying the fastai text learner code to support sequence labeling, and (2) appending the CRF layer to the end of the text learner.
I am happy to try tinkering with this in fastai2 if there is no plan to support NER yet, and I would appreciate any advice for doing so!