All good, it was an API change that I missed too ![]()
I am wondering thought. For my unlabeled inference sets, we wont have with_labels=True. Does that mean we can’t access dls.categroize?
Yes it does I suppose. However if you have access to test_dl, you should get your Categorize from where you made it from. (the original dls, which you still have with load_learner)
Ok. So after exporting a text classifier, i can no longer access the categorize method nor can i use with_labels=True when using load_learner. So strictly at inference, when receiving a large text dataframe, then converting that dataframe into a dl (dl= learner.dls.test_dl(df[‘Message’])) I receive an assertion error. For this reason, i also receive an attribute error from fastinference because there is not attribute categorize Full stack trace below from fastinference.
AttributeError Traceback (most recent call last)
<timed exec> in <module>
~/anaconda3/envs/fastai2_lm/lib/python3.7/site-packages/fastinference/inference/text.py in get_preds(x, ds_idx, dl, raw_outs, decoded_loss, fully_decoded, **kwargs)
65 outs.insert(0, raw)
66 if fully_decoded: outs = _fully_decode(x.dls, inps, outs, dec_out, False)
---> 67 if decoded_loss: outs = _decode_loss(x.dls.categorize.vocab, dec_out, outs)
68 return outs
69
/media/training/fastai2/fastcore/fastcore/foundation.py in __getattr__(self, k)
232 if self._component_attr_filter(k):
233 attr = getattr(self,self._default,None)
--> 234 if attr is not None: return getattr(attr,k)
235 raise AttributeError(k)
236 def __dir__(self): return custom_dir(self,self._dir())
/media/training/fastai2/fastcore/fastcore/foundation.py in __getattr__(self, k)
232 if self._component_attr_filter(k):
233 attr = getattr(self,self._default,None)
--> 234 if attr is not None: return getattr(attr,k)
235 raise AttributeError(k)
236 def __dir__(self): return custom_dir(self,self._dir())
/media/training/fastai2/fastai2/fastai2/data/core.py in __getattr__(self, k)
290 return res if is_indexer(it) else list(zip(*res))
291
--> 292 def __getattr__(self,k): return gather_attrs(self, k, 'tls')
293 def __dir__(self): return super().__dir__() + gather_attr_names(self, 'tls')
294 def __len__(self): return len(self.tls[0])
/media/training/fastai2/fastcore/fastcore/transform.py in gather_attrs(o, k, nm)
153 att = getattr(o,nm)
154 res = [t for t in att.attrgot(k) if t is not None]
--> 155 if not res: raise AttributeError(k)
156 return res[0] if len(res)==1 else L(res)
157
AttributeError: categorize
Pass without decoded_loss (decoded_loss = False) for now and I’ll see what I can come up with
(and also use regular fastai2, not fastinference while I investigate if you run into more issues. In the future regarding fastinference open an issue on the github: https://github.com/muellerzr/fastinference )
Awesome. Will do. FYI, when using fastinference I had 6x speed up. Great work.
1 Like
I am not sure if I’m doing something wrong or this a bug in v2.
I am trying to pre-tokenize tokenize a Dataframe using tokenize_df code I’m using for this:
df_tok, count = tokenize_df(df, text_cols=['title'])
when subsequently trying to use a DataBlock to load this data I obviously want to skip the tokenization since this has already been done in the previous step. The docs for TextBlock suggests passing noop too tok_func if tokenization has already been done.
dls_class = DataBlock(blocks=(TextBlock.from_df(['text'] ,tok_func=noop), CategoryBlock),
get_x=attrgetter('text'),
get_y=ColReader(['genres'])
splitter=RandomSplitter())
When I run dls_class.summary(df_tok) I get the following an error. The key error message seems to me to be TypeError: 'NoneType' object is not callable.
A longer snippet of the error:
Setting-up type transforms pipelines
Collecting items from movieId ... text_length
0 1 ... 5
1 2 ... 3
2 3 ... 7
3 4 ... 6
4 5 ... 11
... ... ... ...
58093 193876 ... 7
58094 193878 ... 6
58095 193880 ... 9
58096 193882 ... 3
58097 193886 ... 3
[58098 rows x 5 columns]
Found 58098 items
2 datasets of sizes 46479,11619
Setting up Pipeline: attrgetter -> Tokenizer -> Numericalize
Process Process-69:
Traceback (most recent call last):
Process Process-70:
File "/usr/lib/python3.6/multiprocessing/process.py", line 258, in _bootstrap
self.run()
Traceback (most recent call last):
File "/usr/lib/python3.6/multiprocessing/process.py", line 93, in run
self._target(*self._args, **self._kwargs)
File "/usr/lib/python3.6/multiprocessing/process.py", line 258, in _bootstrap
self.run()
Process Process-71:
File "/usr/lib/python3.6/multiprocessing/process.py", line 93, in run
self._target(*self._args, **self._kwargs)
File "/usr/local/lib/python3.6/dist-packages/fastai2/torch_core.py", line 733, in f
for i,b in enumerate(cls(**kwargs)(batch)): queue.put((start_idx+i,b))
File "/usr/local/lib/python3.6/dist-packages/fastai2/torch_core.py", line 733, in f
for i,b in enumerate(cls(**kwargs)(batch)): queue.put((start_idx+i,b))
File "/usr/local/lib/python3.6/dist-packages/fastai2/text/core.py", line 133, in __call__
return (L(o).map(self.post_f) for o in self.tok(maps(*self.rules, batch)))
Traceback (most recent call last):
File "/usr/local/lib/python3.6/dist-packages/fastai2/text/core.py", line 133, in __call__
return (L(o).map(self.post_f) for o in self.tok(maps(*self.rules, batch)))
File "/usr/lib/python3.6/multiprocessing/process.py", line 258, in _bootstrap
self.run()
TypeError: 'NoneType' object is not callable
Process Process-72:
File "/usr/lib/python3.6/multiprocessing/process.py", line 93, in run
self._target(*self._args, **self._kwargs)
TypeError: 'NoneType' object is not callable
Traceback (most recent call last):
File "/usr/local/lib/python3.6/dist-packages/fastai2/torch_core.py", line 733, in f
for i,b in enumerate(cls(**kwargs)(batch)): queue.put((start_idx+i,b))
File "/usr/local/lib/python3.6/dist-packages/fastai2/text/core.py", line 133, in __call__
return (L(o).map(self.post_f) for o in self.tok(maps(*self.rules, batch)))
File "/usr/lib/python3.6/multiprocessing/process.py", line 258, in _bootstrap
self.run()
TypeError: 'NoneType' object is not callable
File "/usr/lib/python3.6/multiprocessing/process.py", line 93, in run
self._target(*self._args, **self._kwargs)
File "/usr/local/lib/python3.6/dist-packages/fastai2/torch_core.py", line 733, in f
for i,b in enumerate(cls(**kwargs)(batch)): queue.put((start_idx+i,b))
File "/usr/local/lib/python3.6/dist-packages/fastai2/text/core.py", line 133, in __call__
return (L(o).map(self.post_f) for o in self.tok(maps(*self.rules, batch)))
TypeError: 'NoneType' object is not callable
I’ve tried searching for something similar in the forums but I may have missed something 
1 Like
I haven’t tried this way. Please ignore if this question is naive.
What about the vocab since you are passing tok_func=noop?
Thanks for that suggestion I have tried passing the vocab from a language model data loader (which loads correctly) but the same error appears. One possible solution might be to pass a fake tokenizer that doesn’t actually do anything but that seems a bit hacky 
Maybe hacky is in the eye of the beholder…in the Transformers tutorial example a dummy tokenizer was used (when using pre-processed data)

Thanks, I’ll take a look at that and see if using a dummy tokenizer might be a solution. Hacky is usually my middle name so I don’t have any qualms with a hacky solution ![]()
I suspect that I’m misunderstanding something here but I wonder whether the documentation for text block is then slightly misleading in this regard since currently passing noop doesn’t have the desired effect:
For efficient tokenization, you probably want to use one of the factory methods. Otherwise, you can pass your custom
tok_tfmthat will deal with tokenization (if your texts are already tokenized, you can passnoop), avocab, or leave it to be inferred on the texts usingmin_freqandmax_vocab.
I think this is because TextBlock.from_df returns tokenize.from_df source code which eventually passes noop to:
def __call__(self, batch):
return (L(o).map(self.post_f) for o in self.tok(maps(*self.rules, batch)))
which then returns TypeError: 'NoneType' object is not callable because noop is returning None.
I will wait and see if anyone points out something I’m missing but I guess it would be good to either update the documentation (which I can probably manage) or the behaviour (which I am less confident I could implement nicely)?
1 Like
Good catch, I’d open an Issue or submit a PR
I think a fix would be to test for noop in get_tokenizer, which I think would catch the problem early on:
Alternatively you could try catch it in TokenizeBatch, but then I think you’ll still hit an error in the case when _tokenize1 is called (which calls the tokenizer directly). Let me know if you’d like to discuss/check anything
2 Likes
I can see to possible solutions:
One would be to just catch when tok_func is noop and return a helpful error message (and remove the noop suggestion from the documentation). This would be easier but it probably removes functionality that is probably often useful.
Alternatively, catching tok_func as noop could return a dummy tokenizer which behaves like a tokenizer but doesn’t actually make changes.
The second would (hopefully) address the problem but my only concern is that it has some performance implications since it would mean a function gets applied accross the entire dataset and doesn’t actually do anything useful?
1 Like
You’re right…but I guess in the case of the noop error message, the user will have to create a dummy token anyways for it to work (unless they go down to the mid-level api like in the tutorial example above).
The alternative I guess would be to go through the tokenize functions and escape them one by one with tok_func is called. Which works for now but means that future contributors will have to remember to do the same for any new features that call tok_func…
Maybe theres a better 3rd option, but I’m not sure I’m imaginative enough to find it ![]()
I’ll try and have a look with fresh eyes tomorrow but probably passing a fake tokenizer is likely to be the best option.
1 Like
I used datasets and dataloaders a lot before with text (fastaiv2 0.0.8), be it for custom datasets with standard ULMFIT use, be it for using transformers adapted to fastaiv2 pipeline.
I recently upgraded to fastaiv2 last commit (0.0.17), and now I always get this error when using show_batch. Any thoughts?
`AttributeError: 'L' object has no attribute 'truncate'`
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-39-90634fcc3c9e> in <module>
----> 1 dls.show_batch()
~/anaconda3/envs/fastaiv2/lib/python3.6/site-packages/fastai2/data/core.py in show_batch(self, b, max_n, ctxs, show, unique, **kwargs)
97 if b is None: b = self.one_batch()
98 if not show: return self._pre_show_batch(b, max_n=max_n)
---> 99 show_batch(*self._pre_show_batch(b, max_n=max_n), ctxs=ctxs, max_n=max_n, **kwargs)
100 if unique: self.get_idxs = old_get_idxs
101
~/anaconda3/envs/fastaiv2/lib/python3.6/site-packages/fastcore/dispatch.py in __call__(self, *args, **kwargs)
96 if not f: return args[0]
97 if self.inst is not None: f = MethodType(f, self.inst)
---> 98 return f(*args, **kwargs)
99
100 def __get__(self, inst, owner):
~/anaconda3/envs/fastaiv2/lib/python3.6/site-packages/fastai2/text/data.py in show_batch(x, y, samples, ctxs, max_n, trunc_at, **kwargs)
107 def show_batch(x: TensorText, y, samples, ctxs=None, max_n=10, trunc_at=150, **kwargs):
108 if ctxs is None: ctxs = get_empty_df(min(len(samples), max_n))
--> 109 if trunc_at is not None: samples = L((s[0].truncate(trunc_at),*s[1:]) for s in samples)
110 ctxs = show_batch[object](x, y, samples, max_n=max_n, ctxs=ctxs, **kwargs)
111 display_df(pd.DataFrame(ctxs))
~/anaconda3/envs/fastaiv2/lib/python3.6/site-packages/fastcore/foundation.py in __call__(cls, x, *args, **kwargs)
45 return x
46
---> 47 res = super().__call__(*((x,) + args), **kwargs)
48 res._newchk = 0
49 return res
~/anaconda3/envs/fastaiv2/lib/python3.6/site-packages/fastcore/foundation.py in __init__(self, items, use_list, match, *rest)
316 if items is None: items = []
317 if (use_list is not None) or not _is_array(items):
--> 318 items = list(items) if use_list else _listify(items)
319 if match is not None:
320 if is_coll(match): match = len(match)
~/anaconda3/envs/fastaiv2/lib/python3.6/site-packages/fastcore/foundation.py in _listify(o)
252 if isinstance(o, list): return o
253 if isinstance(o, str) or _is_array(o): return [o]
--> 254 if is_iter(o): return list(o)
255 return [o]
256
~/anaconda3/envs/fastaiv2/lib/python3.6/site-packages/fastai2/text/data.py in <genexpr>(.0)
107 def show_batch(x: TensorText, y, samples, ctxs=None, max_n=10, trunc_at=150, **kwargs):
108 if ctxs is None: ctxs = get_empty_df(min(len(samples), max_n))
--> 109 if trunc_at is not None: samples = L((s[0].truncate(trunc_at),*s[1:]) for s in samples)
110 ctxs = show_batch[object](x, y, samples, max_n=max_n, ctxs=ctxs, **kwargs)
111 display_df(pd.DataFrame(ctxs))
AttributeError: 'L' object has no attribute 'truncate'
The code that generated this:
dsrc = Datasets(df, tfms=[tfms, [attrgetter("label"), Categorize()]], splits=splits)
dsrc[0]
Output:
(TensorText([ 0, 180, 1601, 1021, 987, 6497, 2304, 39181, 73478,
75504, 48, 214641, 8, 20655, 26465, 41, 86210, 302,
137156, 8, 184, 3181, 3369, 86233, 175754, 9, 114584,
11126, 54, 51301, 22, 97606, 10, 130653, 18836, 18652,
14462, 655, 84774, 90, 178579, 28, 48, 5776, 2304,
8656, 5, 2]),
TensorCategory(2))
def transformer_padding(tokenizer=None, max_seq_len=None, sentence_pair=False):
if tokenizer.padding_side == 'right': pad_first=False
else: pad_first=True
max_seq_len = ifnone(max_seq_len, tokenizer.max_len)
return partial(pad_input_chunk, pad_first=pad_first, pad_idx=tokenizer.pad_token_id, seq_len=max_seq_len)
bs = 1
max_seq_len=sl
padding=transformer_padding(xlmr_tok, max_seq_len)
dls = dsrc.dataloaders(bs=bs, before_batch=[padding])
o=dls.one_batch(); o[0].size(), o[1].size(), o[0]
Output:
(torch.Size([1, 119]),
torch.Size([1]),
TensorText([[ 0, 180, 73839, 8, 87853, 146454, 85, 110, 84372,
59197, 196, 113468, 220497, 196, 56649, 1255, 1027, 17914,
197499, 39531, 19329, 4, 167485, 42677, 1156, 8, 3332,
4100, 44778, 362, 38612, 107026, 1140, 10, 31810, 8,
60449, 1952, 5, 1413, 557, 10, 89266, 38845, 10369,
99, 525, 1138, 10, 70560, 9153, 381, 68481, 41,
22, 97606, 2198, 10, 220497, 1651, 15, 67987, 5,
714, 4, 30041, 991, 87, 4, 28, 106392, 4,
5360, 190, 31, 4, 48, 9335, 70885, 1530, 248,
11704, 16, 6, 4, 28, 23, 54376, 36735, 13395,
7, 8, 129718, 352, 2776, 21635, 1156, 4, 1027,
5059, 2456, 964, 329, 10, 41, 36, 113468, 1119,
56, 2968, 87853, 53647, 196, 1646, 6615, 28, 50047,
5, 2]], device='cuda:0'))
dls.show_batch()I think it might be to do with the transforms on your X (tfms), do any of them have decodes function? If so, make sure it returns a TitledStr, which is what truncate is expecting…maybe
@patch
def truncate(self:TitledStr, n):
"Truncate self to `n`"
words = self.split(' ')[:n]
return TitledStr(' '.join(words))
I’ve taken a look at this and passing a faketokenizers to TextBlock.from_df and this seems to work fine for a text that has already been tokenized in some external way e.g. tokenizing with Huggingface tokenizers.
I’m having some trouble getting this to work properly for data that has already been processed via tokenize_df though. tokenize_df returns text as an L object rather than a string or list. I don’t know if it is this or the other tokenization rules which are causing issues when trying to pass a faketokenizer to tokenize_df. I can get the data to load but on show_batch() it doesn’t look right.
I have tried a few different ways of turning off the rules but they didn’t seem to work so far. Does anyone have any suggestions for turning off the tokenization rules to see if that’s causing the issue? I’ve tried passing an empty list (since None is already the default parameter) but that doesn’t seem to work.
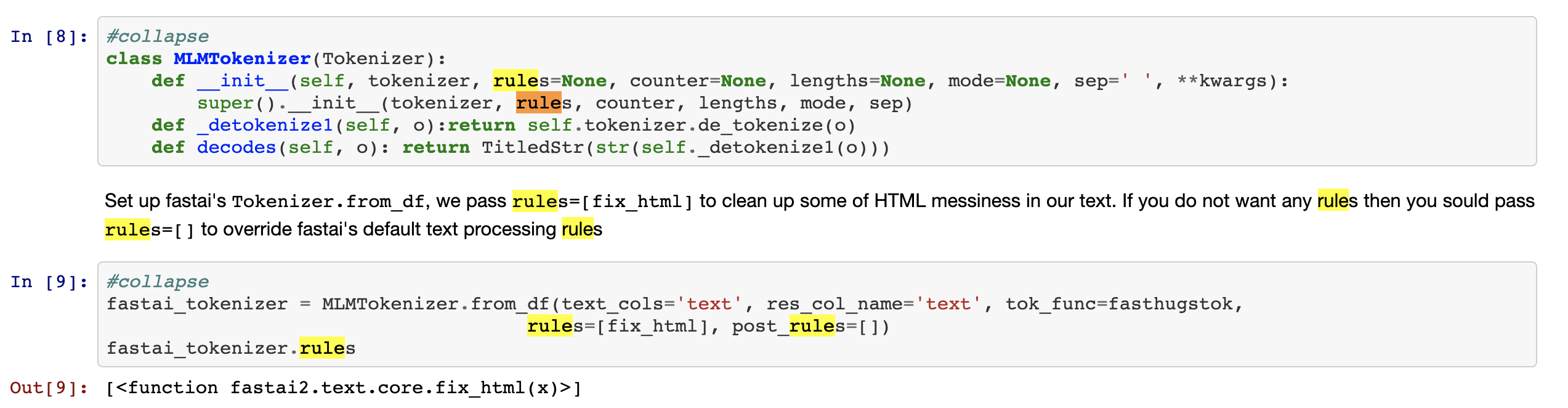
Hi, @morgan, thanks for the reply. I was using both truncate and show_batch. It worked before, but for some reason isnt working anymore (0.0.17):
@patch
def truncate(self:TitledStr, n):
words = self.split(' ')
words = [w for w in words if w != vocab[1]][:n]
return TitledStr(' '.join(words))
@typedispatch
def show_batch(x: TensorText, y, samples, ctxs=None, max_n=10, trunc_at=150, **kwargs):
if ctxs is None: ctxs = get_empty_df(min(len(samples), max_n))
samples = L((s[0].truncate(trunc_at),*s[1:]) for s in samples)
ctxs = show_batch[object](x, y, samples, max_n=max_n, ctxs=ctxs, **kwargs)
display_df(pd.DataFrame(ctxs))
return ctxs