This seems fairly important: why is RandomSplitter camel cased despite being just a function?
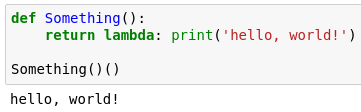
The naming convention that was adopted is that if Something when called will return a callable (anything that can be called), Something will be camel cased.
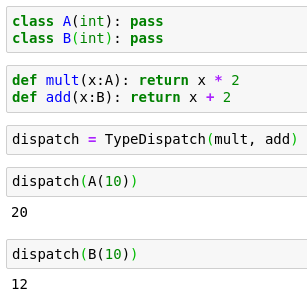
This magic was not even that arcane since I figured out how it works from reading the class definition
class TypeDispatch:
"Dictionary-like object; `__getitem__` matches keys of types using `issubclass`"
def __init__(self, *funcs):
self.funcs,self.cache = {},{}
for f in funcs: self.add(f)
self.inst = None
def _reset(self):
self.funcs = {k:self.funcs[k] for k in sorted(self.funcs, key=cmp_instance, reverse=True)}
self.cache = {**self.funcs}
def add(self, f):
"Add type `t` and function `f`"
self.funcs[_p1_anno(f) or object] = f
self._reset()
def returns(self, x): return anno_ret(self[type(x)])
def returns_none(self, x):
r = anno_ret(self[type(x)])
return r if r == NoneType else None
def __repr__(self): return str({getattr(k,'__name__',str(k)):v.__name__ for k,v in self.funcs.items()})
def __call__(self, x, *args, **kwargs):
f = self[type(x)]
if not f: return x
if self.inst: f = types.MethodType(f, self.inst)
return f(x, *args, **kwargs)
def __get__(self, inst, owner):
self.inst = inst
return self
def __getitem__(self, k):
"Find first matching type that is a super-class of `k`"
if k in self.cache: return self.cache[k]
types = [f for f in self.funcs if issubclass(k,f)]
res = self.funcs[types[0]] if types else None
self.cache[k] = res
return res
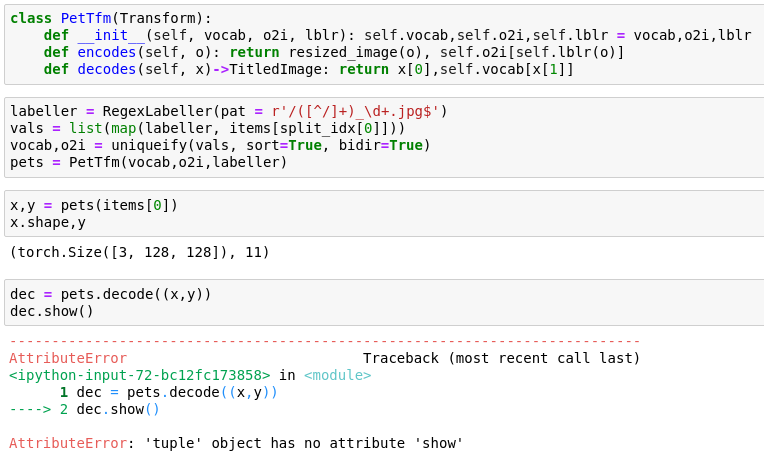
On the other hand, how is the returned object cast based on type annotation in decodes?!
Now that is some powerful wizardry I tried looking in Transform, retain_type, TypeDispatch and _TfmDict but got nothing Quite sure it will be explained later down the road though
As they say, curiosity killed the cat, or at least the time the cat was supposed to put into following the walk through, but instead it got attracted to the shiny low level functionality
We used to use the type annotations before we introduced the subclasses of Tensors/PIL.Images etc. Now that the object have the proper types, there is no need for them anymore and it can be confusing that a function with a type annotation Foo doesn’t return an object of type Foo.
I just love this kind of literate programming. There are many times I need to go back and forth the notebook to experiment things. Now, I can stay safely in the notebook and everything is created automatically. I am trying to integrate it to others projects, and write here how it works (use just notebook_core and notebook_export) https://medium.com/@dienhoa.t/fast-ai-literature-programming-2d0d4230dd81 . This is very very shallow but anyway, I hope someone can find it useful
class RegexLabeller():
“Label item with regex pat.”
def init(self, pat, match=False):
self.pat = re.compile(pat)
self.matcher = self.pat.match if match else self.pat.search
def __call__(self, o, **kwargs):
res = self.matcher(str(o.as_posix()))
assert res,f'Failed to find "{self.pat}" in "{o}"'
return res.group(1)
If RegexLabeller is chaned like that, then it will work both windows and Linux. It is only a small change, when converting Pathlib path to string. The String conversion needs to change from str(o) to str(o.as_posix())
class RegexLabeller():
"Label `item` with regex `pat`."
def __init__(self, pat, match=False):
self.pat = re.compile(pat)
self.matcher = self.pat.match if match else self.pat.search
def __call__(self, o, **kwargs):
res = self.matcher(str(o.as_posix()))
assert res,f'Failed to find "{self.pat}" in "{o}"'
return res.group(1)
Change RegexLabeller to that, it will wok fine in windows also. str(o)–> str(o.as_posix())
I just watched the first walk-thru at fast speed. I’m going to watch it again and code along. I am really interested in the L data structure that replaces lists. Is it possible to replicate it easily for other programs we can be working on?