See the fp16 notebook to see how to use it, of course 
Is there a way to use torch.optim Optimizers (e.g. torch.optim.SGD) in v2? I’m trying to reproduce a result and want to use the exact same Optimizer, if possible. Looking at the v2 docs for Optimizers, it seems that all optimizers are implemented from scratch and not using torch.optim at all. Thanks in advance!
1 Like
I am trying to understand the __call__ inside MetaClass:
def __call__(cls, *args, **kwargs):
f = args[0] if args else None
n = getattr(f,'__name__',None)
for nm in _tfm_methods:
if not hasattr(cls,nm): setattr(cls, nm, TypeDispatch())
if isinstance(f,Callable) and n in _tfm_methods:
getattr(cls,n).add(f)
return f
return super().__call__(*args, **kwargs)
Are there any good resources that could help me understand what’s really going on? I can’t seem to get when it get’s called .
I haven’t tried it, but I think it should work - or at least not need too much fiddling. Give it a go and tell us what you find. Possibly not all the callbacks will work with them though.
The schedulers definitely won’t work since the hyper-params have different names in PyTorch.
Yup a to_fp16 is missing in that notebook with a patch to Learner, will do tomorrow.
Any metaclass tutorial or the Python Data Model docs should cover it. Basically, it’s going to be called whenever a new object is created from that type. e.g. if you have class A(metaclass=B):... then B.__call__ will be called when you later say a=A(). And it will in turn normally call A.__new__.
Remember that class A:... is just syntax sugar for A = type('A',(object,),{}). If you use a metaclass, then it calls that instead of type().
3 Likes
Hi @arora_aman , it is called whenever the class which uses this as a metaclass is called. I had tried to understand this using the below example. This is basically the example used by Jeremy in his code walkthrough 4. We define a _norm function and then call @Transform on the same.
def _norm(x,m,s): return (x-m)/s
norm_t = Transform(_norm)
I did a %%debug on norm_t = Transform(_norm) . I found that the first thing the code was doing was calling __call__ of _TfmMeta as Transform uses the meta class _TfmMeta .
def __call__(cls, *args, **kwargs):
f = args[0] if args else None
n = getattr(f,'__name__',None)
if not hasattr(cls,'encodes'): cls.encodes=TypeDispatch()
if not hasattr(cls,'decodes'): cls.decodes=TypeDispatch()
if isinstance(f,Callable) and n in ('decodes','encodes','_'):
getattr(cls,'encodes' if n=='_' else n).add(f)
return f
return super().__call__(*args, **kwargs)
Here the cls is the Transform class and the function _norm is in args. f becomes _norm as args[0] is _norm. n gets the __name__ attribute of the function if there is one else it is None. Then the code checks if there is an encodes or decodes attribute in cls. The cls here is the Transform class. At this time it does not have any encodes or decodes.
So there are no encodes and decodes set here and neither is n in _ or encodes or decodes. So the last line of the function super(). __call__ (*args, **kwargs) gets called. The super() of 'TfmMeta is the type. type.__call__() leads too type.__new__ and then Transform.__init__. Here the type.__new__ is called as Transform has no __new__ defined. But it has the __init__ defined. So it is called instead of type.__init__. Hope this clarifies.
2 Likes
I tried using torch.optim.SGD, but get the following error:
opt = partial(torch.optim.SGD, lr=1e-3, momentum=0.9, weight_decay=5e-4*batch_size, nesterov=True)
learn.lr_find()
AttributeError: 'SGD' object has no attribute 'hypers'
So my guess is that I need to at least somehow wrap the torch.optim.SGD in v2’s Optimizer.
See my earlier post. None of the schedulers will work with a non-fastai Optimizer. All the fastai v2 optimizers implementations are tested against the corresponding formulas so you should have no problem of regression with them.
Hi! Probably, I am missing some piece, but I cannot get the number of classes out of DataBunch, or DataSource: I mean no easy way to reach the attribute vocab from the instance of Categorize inside the ds transforms.
1 Like
There is a function in vision/learner.py:91 that provides this functionality
def _get_c(dbunch):
for t in dbunch.train_ds.tls[1].tfms.fs:
if hasattr(t, 'vocab'): return len(t.vocab)
Good!! Your reply is the confirm I was looking for: there is no convenient variable/attribute used to store this piece of information. The only way is through dbunch.train_ds.tls[1].tfms.fs, that is under the assumption that Categorize is the last tfm:
c_out = len(dbch.train_ds.tls[-1].tfms.fs[-1].vocab)
Thank you 
1 Like
It’s one of the things we are thinking of currently, to make it more accessible.
In the next day or two this should be fixed.
1 Like
There is a functionality I google relatively frequently and that is how to flatten a list of lists. Working on a multilabel problem using MultiCategorize() I came across such a need as well.
I was wondering if that maybe would make a good addition to L?

Happy to open a PR, just not sure if that is something that would fit in well with the rest of the functionality.
(I’m also really not sure if there wouldn’t exist a way to write it more nicely)
I just do this, which is just as easy IMO:

3 Likes
Little note: as highlighted Here the above approach only works on lists of lists. For lists of lists of lists, we’ll need another solution. Keep that in mind.
This is great! I didn’t know you could do this. I searched for how to do this a bunch of times but never got an answer along these lines. Works great for me, thank you for sharing!
Still like the approach you mention a lot because of its functional nature, how it is a map with a memo with an addition operator, only downside to it is how slow it is:
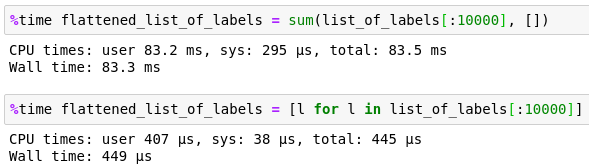
No complains from me, just something worth being aware of
1 Like