I’m puzzled by the implementation of positional encoding in the transformer model. The following code from here joined the cosine wave after the sine wave as follows:
class PositionalEncoding(Module):
"Encode the position with a sinusoid."
def __init__(self, d:int): self.register_buffer('freq', 1 / (10000 ** (torch.arange(0., d, 2.)/d)))
def forward(self, pos:Tensor):
inp = torch.ger(pos, self.freq)
enc = torch.cat([inp.sin(), inp.cos()], dim=-1) # sine wave, followed by cosine wave
return enc
But the actual equations seem to suggest that the sine wave takes up the even dimensions such as column 0,2,4,5…512.
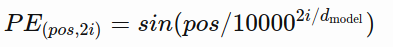
, and the cosine wave the odd dimensions such as column 1,3,5,7,…511 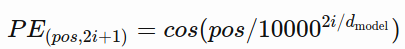
So if, for example, the dimension is 512, then the positional encoding should be [sin, cos, sin, cos,…sin] rather than [sin,sin,sin…sin, cos,cos,cos…cos]
The Annotated Transformer implemented something like this:
class PositionalEncoding(Module):
"Encode the position with a sinusoid."
def __init__(self, d:int): self.register_buffer('freq', 1 / (10000 ** (torch.arange(0., d, 2.)/d)))
def forward(self, pos:Tensor):
inp = torch.ger(pos, self.freq)
enc = torch.zeros(pos,d)
enc[:, 0::2] = inp.sin() # sine wave takes up the even dimensions
enc[:, 1::2] = inp.cos() # cosine wave takes up the odd dimensions
return enc
Are the two implementations effectively the same?