Some more numbers by reddit user u/seraschka (is it the Sebastian Raschka?)
Thank you for this patch. Can you please specify how I can apply this patch? Do I need to uninstall fastai (which I’ve installed using conda) first?
Yeah uninstall fastai and pytorch.
Use the updated environment.yml to install the new conda environment and make sure it installs pytorch 1.13. After that you can build the patched fastai module by running pip install -e fastai
Thanks. I still get the ‘fake _loader’ error. Do I need to specify any new options related to mps in the dataloader?
I also had to add the highlighted line as line 29 to load.py.

But, now this is the problem. I guess we cannot use any of the existing model architectures until PyTorch implements them.
NotImplementedError: The operator 'aten::adaptive_max_pool2d.out' is not current implemented for the MPS device.
1 Like
Ok, I thought I had merged the fix from fast.ai master which set pin_memory_device to an empty string. I didn’t have any trouble running the first part of the first fastbook notebook but haven’t tested it much… I didn’t see that error pop up for me, might need to fallback to cpu for that operation.
1 Like
torch.backends.mps.is_available() is the equivalent to torch.cuda.is_available()
on this forum post @sgugger mentioned.
What is the equivalent when you have an Apple M1 processor?
learn = vision_learner(dls, resnet18, metrics=error_rate)
does not have device to be assigned
1 Like
Honestly have anyone run successfully a test with fastai on Apple M1?
Can you share a notebook?
I found this notebook but does not include any fastai
You can see the GPU (Activity Monitor → Window → GPU history)
Actually I fixed this error by chucking this in the top of the notebook i was using(before import torch)
#Crashes unless can fallback to cpu if an operation missing
os.environ["PYTORCH_ENABLE_MPS_FALLBACK"] = "1"
Yeah I got it running with some MPS support, you can see in this screenshot it took 4:30 to fine tune the resnet34 model in the first notebook 01_intro.ipynb :
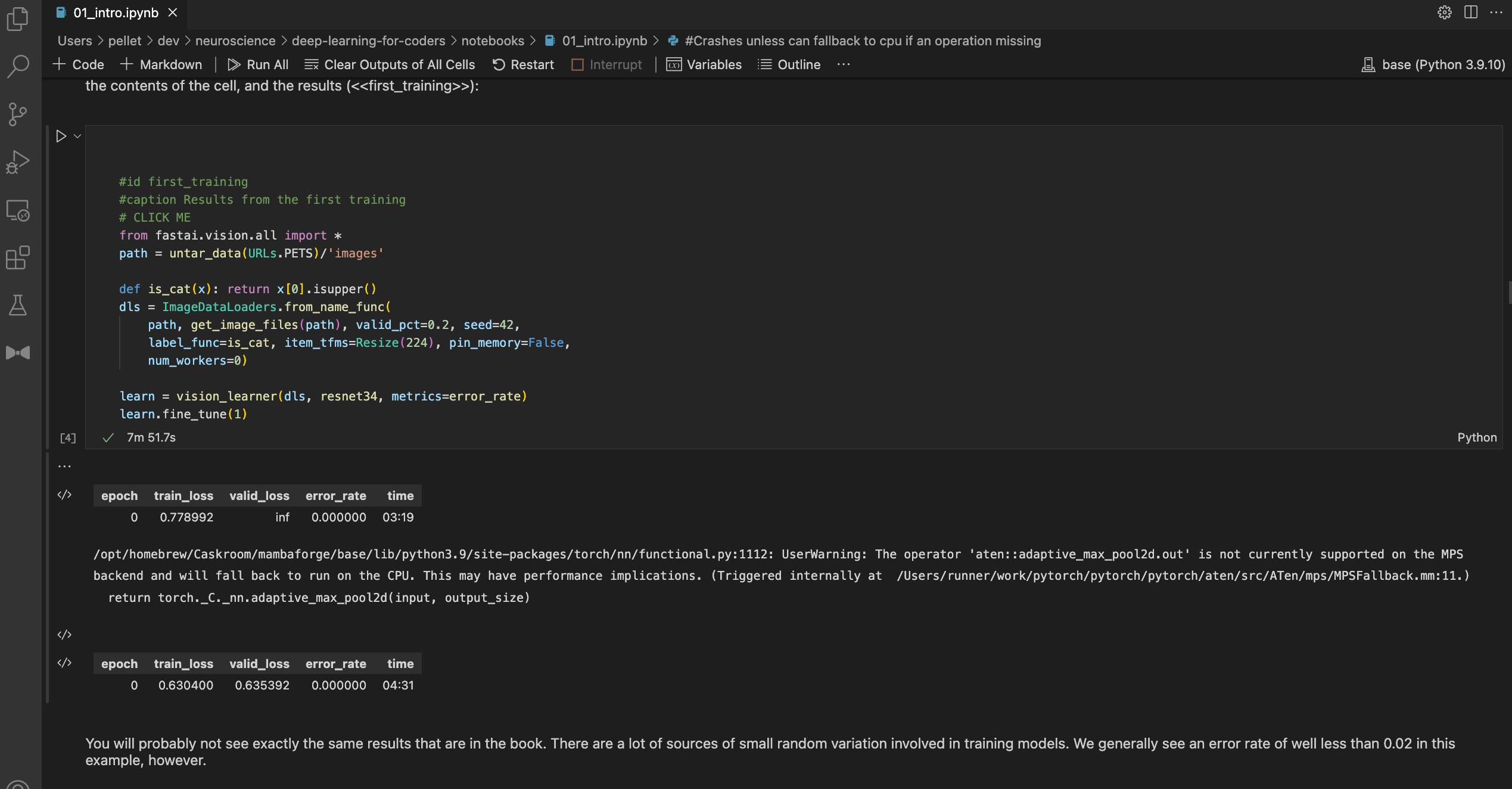
Here is a link to my notebook: deep-learning-for-coders/01_intro.ipynb at master · pellet/deep-learning-for-coders · GitHub
2 Likes
Hi Ben, what are the specs of the M1 machine on which you got these results?
But with os.environ["PYTORCH_ENABLE_MPS_FALLBACK"] = "1", fast would run all the built-in architectures (eg, resnet34) on CPU, so it’s as if MPS does not exist and the nightly-build of PyTorch is and the changes that you have made to fastai are not needed.
I think we just need to wait for the PyTorch team to implement some of the layers that are used in all of the built-in architectures.
M1 air
1 Like
Nah it’s just a fallback - it should only be running functions on the cpu which don’t exist on the gpu. I think the missing function might not even be called often though I could be wrong, there probably isn’t much performance difference.
One pathway to compatibility could be updating the function for detecting the default device to use mps if cuda is not available, I mentioned something similar above.
The missing layer is the last layer of the model so it is called all the time. Also, for a model to run on MPS, all layers must be supported on MPS. Models cannot run partially on one device and partially on another device.
Your own number that shows one epoch took more than 4 minutes is a good indication of this.
@tcapelle posted some new numbers recently for M1 Pro Max (not sure if it’s fast.ai specific though):
I am waiting for fastai on M1, as it has so many dependencies (like spacy, tokenizers, etc…)
3 Likes
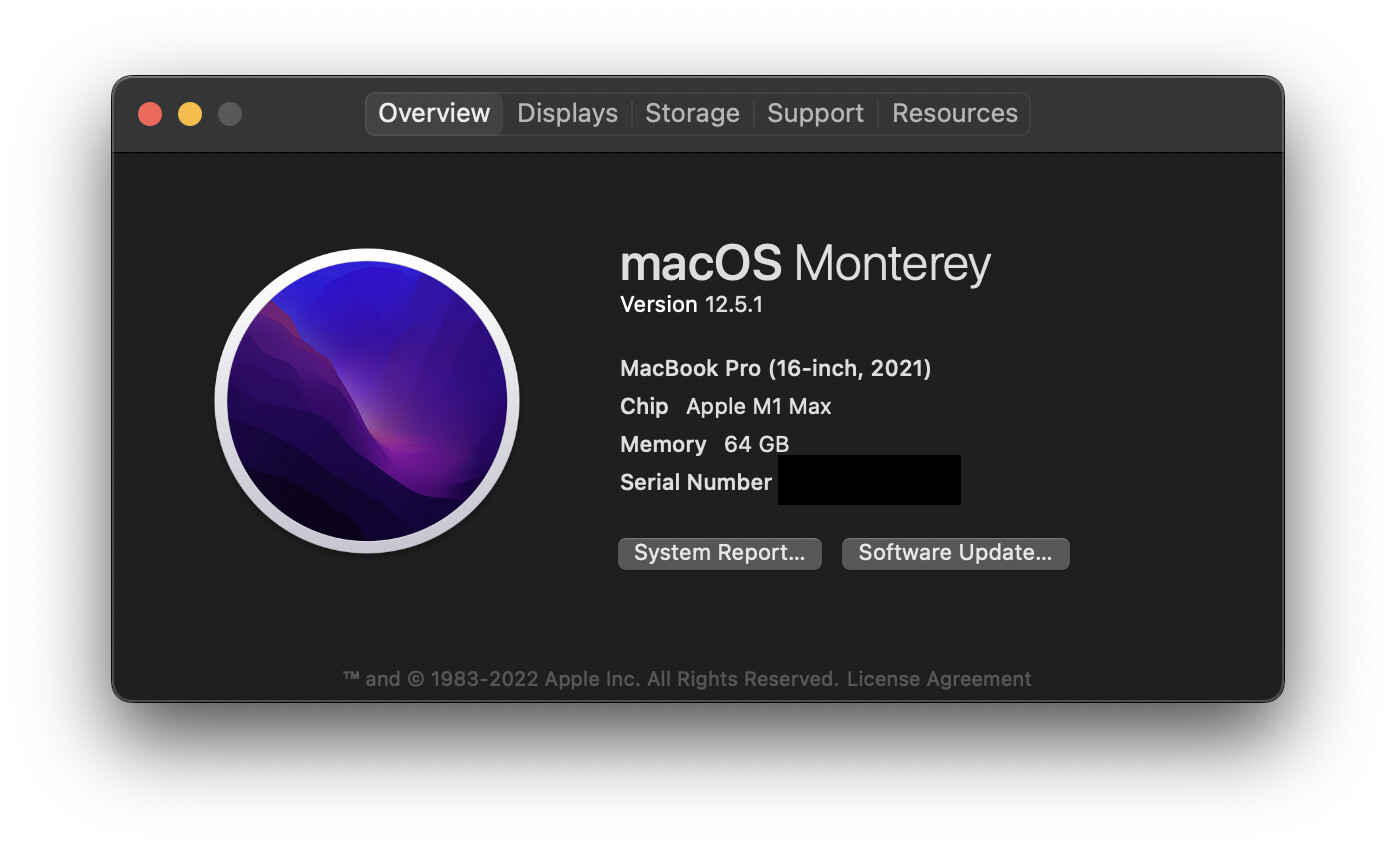
I’ve setup a condo environment on my MacBook Pro with 24 Core M1 Max. I’m able to run the first notebook from the book without any issues. The only change I’ve made is this:
import os os.environ["OMP_NUM_THREADS"] = "1"
When creating a the conda environment, use conda install -c fastchan fastai fastbook jupyterlab sentencepiece.
sentencepiece is an important dependency, but condo doesn’t install it by default for some reason. if you don’t install it, you’ll end up getting some weird dependency error.
Its training the model in reasonable time. Its not as fast as 3080/3090 but its decent, I feel like I can run this whole thing locally on my Mac.
It is in-fact faster than running it on a free paperspace GPU. It took paperspace 1:37 for the same training.
Here’s a video of GPU memory and cores being triggered when training starts:
I don’t actually understand how/why this works with the OMP_NUM_THREADS = 1. It in fact is confusing. The last time I tried this setup about a year ago, this exact setting only made it possible to train the model with CPU, that too on a single thread, which took forever. I know since then PyTorch has officially started supporting M1 Macs, so maybe that’s what has fixed it. If I don’t use this setting, I end up getting an error like this, and it seems to be getting stuck into some infinite loop(sorry they’ll only let me upload one image). I might share more later.
Not sure how it works, but its working, so I’ll take it ![]()
1 Like
This is quite interesting. It seems fastai started working on M1 processors ![]() … What are your MBP specs? And what version of pytorch was it that you were running? These numbers are equivalent to my Dell t3600 Xeon box with 1070ti … so this is definitely “useable” now. Thanks for posting!
… What are your MBP specs? And what version of pytorch was it that you were running? These numbers are equivalent to my Dell t3600 Xeon box with 1070ti … so this is definitely “useable” now. Thanks for posting!