Works perfectly!
1 Like
yeah, ddg_images is depricated
you can replace
from duckduckgo_search import ddg_images
def search_images(term, max_images=30):
print(f"Searching for '{term}'")
return L(ddg_images(term, max_results=max_images)).itemgot('image')
with
from duckduckgo_search import DDGS
def search_images(keywords, max_images = 30):
print(f"Searching for {keywords}")
return L(DDGS().images(keywords,max_results=max_images)).itemgot('image')
10 Likes
This worked for me. Thank you very much!
1 Like
Going into the notebook options and following these settings helped me. I also restarted and cleared my cell output if that helps.
1 Like
Hi all,
I had the same issues with downloading images using Bing/Azure, and I found two versions of the Duckduckgo code. I messed it even more by being blacklisted by ddg a whole day ![]()
It seems that there is an alternate solution using Hugging Face Image API.
It gives something like that:
SEARCH_URL = "https://huggingface.co/api/experimental/images/search"
def get_image_urls_by_term(search_term: str, count=150):
params = {"q": search_term, "license": "public", "imageType": "photo", "count": count}
response = requests.get(SEARCH_URL, params=params)
response.raise_for_status()
response_data = response.json()
image_urls = [img['thumbnailUrl'] for img in response_data['value']]
return image_urls
def gen_images_from_urls(urls):
num_skipped = 0
for url in urls:
response = requests.get(url)
if not response.status_code == 200:
num_skipped += 1
try:
img = Image.open(BytesIO(response.content))
yield img
except UnidentifiedImageError:
num_skipped +=1
print(f"Retrieved {len(urls) - num_skipped} images. Skipped {num_skipped}.")
def urls_to_image_folder(urls, save_directory):
for i, image in enumerate(gen_images_from_urls(urls)):
image.save(save_directory / f'{i}.jpg')
I found this snippet here.
Thank you for this, Christian!
Helped me immensely.
Regards,
Beau
Not sure if this is the same thing, but in lesson 1, I ran the cell that contains this code:
#NB: `search_images` depends on duckduckgo.com, which doesn't always return correct responses.
# If you get a JSON error, just try running it again (it may take a couple of tries).
urls = search_images('bird photos', max_images=1)
urls[0]
And got this error output:
---------------------------------------------------------------------------
HTTPError Traceback (most recent call last)
/tmp/ipykernel_17/2432147335.py in <module>
1 #NB: `search_images` depends on duckduckgo.com, which doesn't always return correct responses.
2 # If you get a JSON error, just try running it again (it may take a couple of tries).
----> 3 urls = search_images('bird photos', max_images=1)
4 urls[0]
/tmp/ipykernel_17/1717929076.py in search_images(term, max_images)
4 def search_images(term, max_images=30):
5 print(f"Searching for '{term}'")
----> 6 return L(ddg_images(term, max_results=max_images)).itemgot('image')
/opt/conda/lib/python3.7/site-packages/duckduckgo_search/compat.py in ddg_images(keywords, region, safesearch, time, size, color, type_image, layout, license_image, max_results, page, output, download)
80 type_image=type_image,
81 layout=layout,
---> 82 license_image=license_image,
83 ):
84 results.append(r)
/opt/conda/lib/python3.7/site-packages/duckduckgo_search/duckduckgo_search.py in images(self, keywords, region, safesearch, timelimit, size, color, type_image, layout, license_image)
403 assert keywords, "keywords is mandatory"
404
--> 405 vqd = self._get_vqd(keywords)
406 assert vqd, "error in getting vqd"
407
/opt/conda/lib/python3.7/site-packages/duckduckgo_search/duckduckgo_search.py in _get_vqd(self, keywords)
93 def _get_vqd(self, keywords: str) -> Optional[str]:
94 """Get vqd value for a search query."""
---> 95 resp = self._get_url("POST", "https://duckduckgo.com", data={"q": keywords})
96 if resp:
97 for c1, c2 in (
/opt/conda/lib/python3.7/site-packages/duckduckgo_search/duckduckgo_search.py in _get_url(self, method, url, **kwargs)
87 logger.warning(f"_get_url() {url} {type(ex).__name__} {ex}")
88 if i >= 2 or "418" in str(ex):
---> 89 raise ex
90 sleep(3)
91 return None
/opt/conda/lib/python3.7/site-packages/duckduckgo_search/duckduckgo_search.py in _get_url(self, method, url, **kwargs)
80 )
81 if self._is_500_in_url(str(resp.url)) or resp.status_code == 202:
---> 82 raise httpx._exceptions.HTTPError("")
83 resp.raise_for_status()
84 if resp.status_code == 200:
What’s going on? Any help is much appreciated, and thanks in advance!
thank you kindly!! that works!!
Thank you this worked for me too!
Hi All - I’ve spent a bit of time in the forums trying various solutions proposed but wasn’t able to resolve my error. I kept encountering the 403 error no matter what I did. I eventually was able to adjust the code using pieces from 2 different solutions.
I amended the first code cell under STEP 1
from duckduckgo_search import ddg_images, DDGS
from fastcore.all import *
def search_images(term, max_images=200):
with DDGS(headers = {“Accept-Encoding”: “gzip, deflate, br”}) as ddgs:
results = ddgs.images(keywords=term)
images = [next(results).get(“image”) for _ in range(max_images)]
return L(images)
This resolved the error for me when using Kaggle.
3 Likes
This worked for me too. Thanks @periculo
Only thing I had to do was swap the double quotes for single quotes and nudge the indent on a few lines.
from duckduckgo_search import ddg_images, DDGS
from fastcore.all import *
def search_images(term, max_images=200):
with DDGS(headers = {'Accept-Encoding': 'gzip, deflate, br'}) as ddgs:
results = ddgs.images(keywords=term)
images = [next(results).get('image') for _ in range(max_images)]
return L(images)
2 Likes
this works for me too! Thank you!
def search_images(term, max_images=30):
print(f"Searching for ‘{term}’")
with DDGS() as ddgs:
ddgs_images_gen = ddgs.images(term)
count = 0
ddgs_images_list =
while count < max_images:
image = next(ddgs_images_gen)
ddgs_images_list.append(image.get(‘image’))
count = count+1
return ddgs_images_list
search_images(“dog”)
OI copied this code from another forum but it doesn’t work and said HTTPStatusError: Client error ‘403 Forbidden’ for url.
Does it has anything related to IP blocking from ddg?
It works! Thanks so much, would you mind explain this code please?
So, I’m not able to recreate the example on Kaggle—seems like this code doesn’t work for me (perhaps duckduckgo_search functionality has changed? Or something else is wrong with how I’m running it):

The issue here is that in the line:
images = [next(results).get('image') for _ in range(max_images)]
the function next is expecting an iterator as an input and here results is actually a list which can be seen explicitly by running the following code:
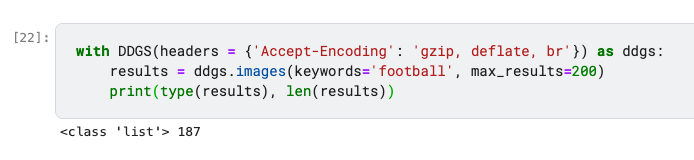
Here is what results looks like—it’s a list of dict objects containing metadata, including the image URL:
Here’s the code that currently works for me in a Kaggle notebook:
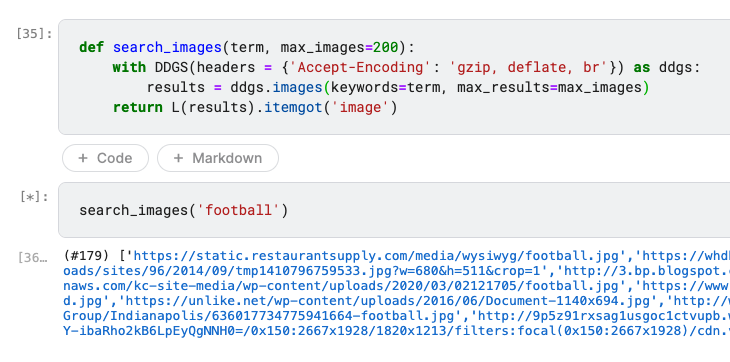
ddgs.images takes keywords and returns a list of dictionaries with the search result metadata.
L(results) takes the list of dictionaries results and constructs a fastai L object from it. The L object is like a list but with more helper methods.
The itemgot method of the L object in this case gets all of the image items from the list of dictionaries. So as a final result you have an L object with a bunch of image URLs.
I was going through the same issue recently, I ended up just using simple_image_download instead. I was training a shonen_mc classifier so the code illustrates that:
Here is the code for downloading and you can find my notebook there
search_queries = [
"Natsu Dragneel", "Ichigo Kurosaki", "Asta Black Clover", "Naruto Uzumaki", "Son Goku", "Moneky D. Luffy", "Yuji Itadori"
]
from simple_image_download import simple_image_download as simp
response = simp.simple_image_download
for mc in search_queries:
response().download(f"{mc}", 300)
Hope this helps.
this worked for me, I appreciate the help!
Thank you so much – this has resolved my “HTTP 403” error too.
Best,
BY
I was also getting a 403 every time (using notebook cloned and executed on Jun 7 2024) and this solution worked for me.
Minor note: If I copy+paste the above text and paste it into a notebook, it doesn’t work exactly as is, because the double quotes in the text above are smart quotes, and thus don’t properly delineate the strings. Deleting each double quote and retyping it fixes the problem.
I noticed a comment farther up in which somebody copied and pasted some other solution, and claimed that they made it work by changing double quotes to single quotes. That probably made a difference not because of the change to single quotes, but because their edit changed smart quotes to dumb quote characters.
1 Like