I guess you could create the data object again, and call learn.set_data(data).
I am not a 100% sure since I haven’t tried this, maybe someone else can chime in.
I guess you could create the data object again, and call learn.set_data(data).
I am not a 100% sure since I haven’t tried this, maybe someone else can chime in.
I believe it should be possible to go back and load the saved model and then create data again this time assigning the test folder and skip training to directly predict on the test set. The issue others on the forum were having is that they didn’t assign the test folder and then later ran into issues predicting on the test set (directly after training). So I think its just a good rule of thumb to assign the test folder from the beginning so you don’t have to repeat any steps.
Thanks a lot @A_TF57 ! 
The following methodology works to make predictions on the test set when it was not initially given to the data object :
data=... with test_name='test' :data = ImageClassifierData.from_csv(PATH, 'train', f'{label_csv}', test_name='test', num_workers=4, val_idxs=val_idxs, suffix='.jpg', tfms=tfms, bs=bs)
run : learn.set_data(data)
then, you can run : log_preds,y = learn.TTA(is_test=True)
Thanks @jamesrequa for your answer. @A_TF57 gave me the working metodology :
So, the only difference is that the guys who get <.1 loss aren’t removing the last layer from pretrained models ? Why does it work better ?
I’m just guessing, but I think its because the dog breeds are already part of the 1000 categories in ImageNet? In fact I think there are a total of 133 dog breeds in ImageNet but we only need 120. So you could technically just grab those subset of the 1000 class predictions corresponding to the breeds in the competition.
Yeah so they are using the fully connected layers where we take those off and calculate our own right?
'+ 1 guess - at imagenet competition there might be another train/test split, so some of images we have in test were used to train original imagenet models.
Correct guess!
i just submitted to this challenge. i used resnet34.
submission ranking is 106. the loss is 0.40946
Wellcome @mprabhu 
James and others, here is a notebook that takes some images and gets predictions for the original imagenet categories. Note that it will predict on the validation images.
https://github.com/yanneta/pytorch-tutorials/blob/master/predict_from_pretrained.ipynb
This is using the new API that Jeremy just developed for cifar.
So after hours of trying to figure out how to set up the data, code, and run things, I finally got it to works! Right now I have a learning rate of about 0.91, which isn’t that great. I think it’s because I set my learning rate to 0.01 (aka the default from the cats vs dogs program). I’m going to look through the lessons to see how to properly predict the best learning rate and try again with that later. Any tips for me in the meantime?
Use the lr finder to predict the best learning rate ![]()
lrf=learn.lr_find()
I knew I forgot something, thanks!
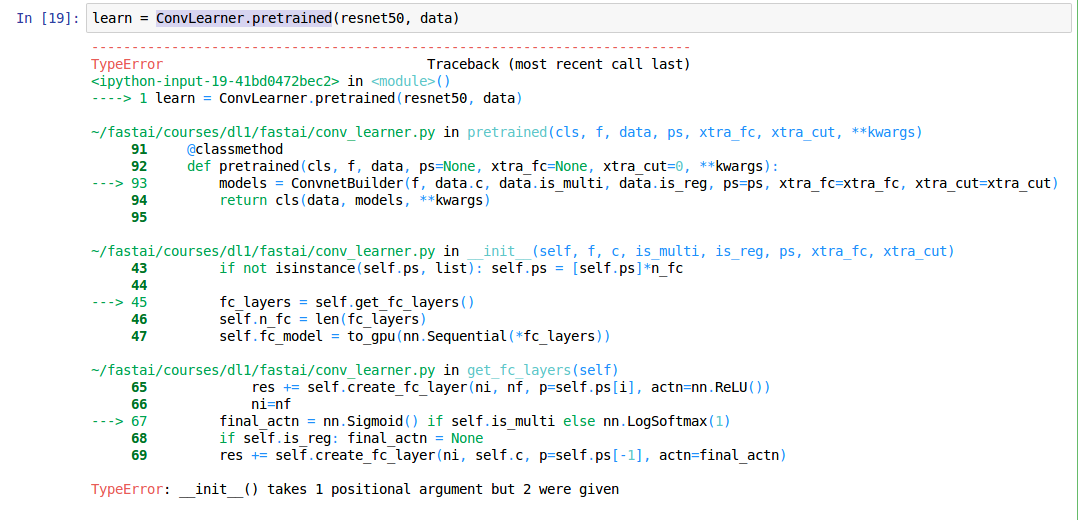
I am getting the following error when I run ConvLearner.pretrained on aws. The script runs fine on my laptop.
What could be the issue?
I just got that too. I deleted the 1 in the nn.LogSoftmax(1) and it worked.
Not sure if fastai changed or pytorch changed, but one is out of sync …
EDIT: It looks like fastai is expecting the master branch of pytorch, whereas I have 2.0 installed.
Can you also screenshot the line where data is generated?
sure:
btw the convlearner was trained with resnet50. this screenshot is from unsaved file.
I am getting the same error on multiple scripts that were running fine. I guess something is amiss as @rob said.
Yeah, you could report it as an issue over on github too just to make sure it is known. Sounds like a simple fix, but I’m not sure what the implications of that change are.