I’m running the various fit commands (both on 224 and 299), and they’re taking quite a long time. Very slow.
learn.fit(1e-2, 5, cycle_len=1) takes 5-10+ minutes. I’ve been watching it run for the past 5 minutes, and it’s still on epoch 1. Is there any way to check that I’m properly utilizing my GPU? I’m using AWS.
I ran this command, it seems like some of the GPU is being used by Python, but not more than about 20%. Any tips?
(fastai) ubuntu@ip-172-31-37-237:~$ nvidia-smi
Fri Mar 2 00:54:57 2018
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 384.81 Driver Version: 384.81 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla K80 On | 00000000:00:1E.0 Off | 0 |
| N/A 81C P0 134W / 149W | 2447MiB / 11439MiB | 95% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 1541 C ...tu/src/anaconda3/envs/fastai/bin/python 2434MiB |
+-----------------------------------------------------------------------------+
Took some test array hacking things together to get this to work.
Here’s what I did that worked, but I’d like to improve upon it as it feels slow. I would guess there’s a way to manipulate the dataframe directly that’s much more efficient, instead of pulling things out, manipulating the list, then making a new dataframe.
%time test_probs = np.mean(np.exp(test_log_preds),0) # average across the 5 TTA's
test_probs.shape # (10357, 120)
len(data.test_dl.dataset.fnames) # 10357
# Remove file paths and jpg extension from ids
idnames = []
for filepath in data.test_dl.dataset.fnames:
idnames.append( filepath.split('/')[-1].split('.jpg')[0])
headerrow = (['id'] + data.classes) # 1x121 list, header of the csv columns
# This part in particular feels wrong and is a bit slow to run. Any tips here to avoid converting nparrays to lists?, or to do it all in the context of a dataframe?
datarows = []
for idname, testproblist in zip(idnames, test_probs):
datarows.append([idname] + list(testproblist))
df_submit_tta = pd.DataFrame.from_records(datarows, columns=headerrow)
df_submit_tta.head()
df_submit_tta.to_csv('test_df.csv', index=False)
Great stuff. After this lesson, I have two questions.
Is there a function in the fastai where I can view the multiclass log loss per epoch, instead of accuracy? Since this is what the end score is based on, makes sense to monitor it the whole time. I’d like to compare directly to the Kaggle leaderboard, but I currently can’t as the metrics are different. Thought I’d check if something already exists before going down the DIY route.
Jeremy mentioned doing away with the validation set and training on 100% of the training data then submitting, after the model is set up. What are the steps to doing this? And how does it train without knowing what its validation set is for doing sgd? Do you retrain and ensemble a handful of models on different training/validation groupings of the same training data? Or is there a simpler way?
Really appreciate your help.
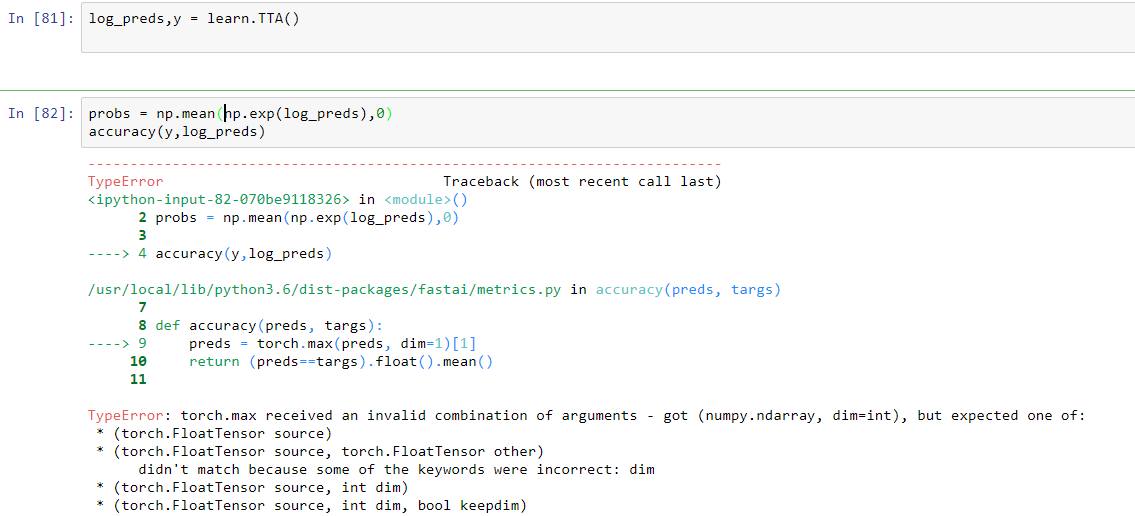
The problem I’m facing is during accuracy calculation . Its asking for a different data type than what I’ve given . I was following the lectures and over there it was done the same i.e passing numpy arrays but its expecting a torch data type . Please correct me in case if I’m doing wrong anywhere.
When submitting my predictions using the notebook provided, I’m getting a score that’s close to 13 even though my accuracy during the training steps are in the low 90s. Is there an error somewhere that I should be looking out for?
Edit: Managed to fix my problem! In case anybody else is interested, I wrote to a .csv file instead of a .gz file.