Thanks for all of your help on this, and yes, its the DogBreed competition! I am very curious to see where I can get, so I can test my understanding of Jeremy’s and others’ instructions!
Have just submitted this “trained on all the data” model and it does not do very well - a score of 0.22755. I am not sure that I can trust the way I have gone about it, and as there is so much digging around to get clear understanding on this, it’s no wonder
I think I will just go back to the drawing board and try and follow the regular approach to see where it gets me, because I was certainly getting a better score during the building of the model, but all of this extra work with the ful data set has left me in the dark.
Is there any way to test how well we are doing on the test set before we submit to kaggle?
Running through my learning again after setting val_idxs = [0] (i.e. just one validation file), I still am getting validation errors and predictions that look like the previous information when I had a full data set - is this expected? Is this validation against my one and only validation file?
Also, should I be looking at the error rate and accuracy data and choosing a place to stop the learning, as I can see that after the second run I am increasingly overfitting and my accuracy is getting worse, so going all the way through 3 runs may not be desirable? Its very hard to know what is really happening without a validation set!
I tried train_features = learn.predict(data.trn_dl), but it returns an array with shape (10357, 1000). I also tried train_features = learn.predict(data.trn_ds) and it has the same shape. data.trn_y has a shape (8178,) which is what I expected since 20% of the data is in the validation set.
This error is coming from my call to metrics.log_loss. I believe its because something is wrong with y I am passing as a parameter.
If I switch around the parameters and say metrics.log_loss(probs, y) then I get a different error, “ValueError: Multioutput target data is not supported with label binarization” - so I don’t think that the parameters are in an incorrect order.
Actually, y is just an array of zeros which can’t be right, so maybe when we use log_preds, y = learn.TTA(is_test=True) then the y we are getting back is incorrect.
I believe that my y is just zeros because I have used val_idxs = [0] - in order to train with the entire data set.
In summary I believe the problem it reports (that I need to “Please provide the true labels explicitly through the labels argument”) means that I need to get my labels some other way - how would this be done?
Ah, is that the case? Apologies for missing that part. Now the error makes sense. Since you have put val_idxs = [0], the validation set would have had (almost) less than 10 records and it so happens that all those records are of the same label. Sklearn enforces atleast two different labels constraint; which is the error you see.
Anyways, if you’re training on all the data, this number will not be significant to your analysis right? Why would you want to calculate it anyway?
Edit: I’m on my phone right now. I’ll get back on this a little while later.
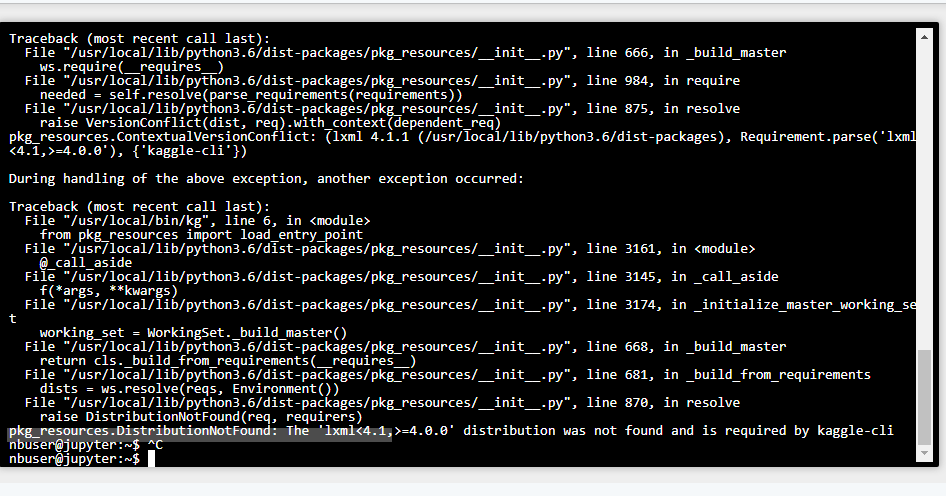
,i’m trying to use kaggle-cli on crestle .after kg config i encounter this error .do anyone of you have any suggestion what should i do to resolve this issue.
You have let me know the problem. I just have one file in my valid set and so y is only one label.
But now I am confused about the is_test = True. I thought this meant that it is going to use the images in the test folder to test against. And that there should be Y labels equivalent for those images, and that TTA function would return return those. But I guess they wouldn’t be a proper test set would they, if you knew the labels!
This line suggests that when you don’t give is_test=True in your TTA function call, the 2nd output in the return statement will contain targets from validation folder - which in your case happens to be 1 record and hence the sklearn error.
However, when you put is_test=True, you are using the images in your test folder (for which you do not know the label) and using the model to generation predictions; in this case library returns zeros as a placeholder as the second output result, which you can consider irrelevant. You only need the first output from TTA function call and from those probabilities you could further extract labels / probabilities as you’d like to process them downstream.
nbuser@jupyter:~$ kg config -g -u ##### -p ###### -c Dog Breed Identification
usage: kg config [-h] [-u USERNAME] [-p PASSWORD] [-c COMPETITION] [-g]
kg config: error: unrecognized arguments: Breed Identification
nbuser@jupyter:~$ kg config -h -u ##### -p ##### -c Dog Breed Identification -g
usage: kg [–version] [-v | -q] [–log-file LOG_FILE] [-h] [–debug]
An unofficial Kaggle command line tool.
optional arguments:
–version show program’s version number and exit
-v, --verbose Increase verbosity of output. Can be repeated.
-q, --quiet Suppress output except warnings and errors.
–log-file LOG_FILE Specify a file to log output. Disabled by default.
-h, --help Show help message and exit.
–debug Show tracebacks on errors.
Commands:
complete print bash completion command
config Set config.
dataset Download dataset from a specific user.
download Download data files from a specific competition.
help print detailed help for another command
submissions List recent submissions.
submit Submit an entry to a specific competition.
nbuser@jupyter:~$
does that mean i did everything correctly @sermakarevich,
if yes ,now how should i download the dog breed dataset