It wasn’t intentional at all, which part indicates that? That would need to be fixed. Also, what is meant by being part of the training? As far as I understand form the paper, they keep a copy of model weights and update it via moving/simple average every n epoch/cycle len. That average model becomes SWA model, correct me if I am wrong. Thanks for looking into this!
Yes you are correct, thanks for adding those.
I did some debugging:
- Removed
if self.training - Use
after_train
Problem: I am getting CUDA OOM error at update_bn step. Even while using a small batch size, and leaving half of the GPU memory free.
from torch.optim.swa_utils import AveragedModel
class SWA(Callback):
"https://arxiv.org/abs/1803.05407"
def __init__(self, swa_start=0, cycle_len=1):
store_attr()
def before_epoch(self):
if (self.epoch == self.swa_start):
self.swa_model = AveragedModel(self.learn.model)
print("Init SWA model")
def after_train(self):
if (self.epoch >= self.swa_start) and (self.epoch%self.cycle_len==0):
self.swa_model.update_parameters(self.model)
print("Updated SWA model")
def before_validate(self):
if self.epoch >= self.swa_start:
self.old_model = self.learn.model
self.learn.model = self.swa_model
def after_validate(self):
if self.epoch >= self.swa_start:
self.learn.model = self.old_model
def after_fit(self):
if (self.epoch >= self.swa_start):
torch.optim.swa_utils.update_bn(loader=self.dl, model=self.swa_model, device=self.dls.device)
self.learn.model = self.swa_model
print("Updated BN stats")
Is the problem that we store a copy of the model? Another think I just realized, after looking, again: If we wish to get a proper validation score after each epoch, we actually need to update the BN layers after each epoch (see revised code below), which is obviously time consuming (I guess one could offer an option to the user as to whether they want that?!). Now I remember that that was why I just showed the normal model validation metrics. In a way, it would be nicest, to show extra columns in the table showing metrics for the SWA model, too, in addition to those for the normal model.
from torch.optim.swa_utils import AveragedModel
class SWA(Callback):
"https://arxiv.org/abs/1803.05407"
def __init__(self, swa_start=0, cycle_len=1):
store_attr()
def before_epoch(self):
if (self.epoch == self.swa_start):
self.swa_model = AveragedModel(self.learn.model)
print("Init SWA model")
def after_train(self):
if (self.epoch >= self.swa_start) and (self.epoch%self.cycle_len==0):
self.swa_model.update_parameters(self.model)
print("Updated SWA model")
if (self.epoch > self.swa_start):
torch.optim.swa_utils.update_bn(loader=self.dl, model=self.swa_model, device=self.dls.device)
print("Updated BN stats")
def before_validate(self):
if self.epoch >= self.swa_start:
self.old_model = self.learn.model
self.learn.model = self.swa_model
def after_validate(self):
if self.epoch >= self.swa_start:
self.learn.model = self.old_model
def after_fit(self):
if (self.epoch >= self.swa_start):
self.learn.model = self.swa_model
print("Replaced model with SWA model")
1 Like
That’s a great idea, what is the easiest way to show multi column metrics?
First, we need to fix the OOM issue. Storing a copy model shouldn’t be a problem, as I successfully did a similar thing in other callbacks. I am not sure what happens inside update_bn function.
Do we need to detach the weights of the SWA model? But, pytorch example don’t do such thing and they only wrap the model as swa_model = torch.optim.swa_utils.AveragedModel(model). I am a bit confused…
BTW this works without OOM error (Wonder why it previously failed while using after_fit):
from torch.optim.swa_utils import AveragedModel, update_bn
class SWA(Callback):
"https://arxiv.org/abs/1803.05407"
def __init__(self, swa_start=0, cycle_len=1):
store_attr()
def before_epoch(self):
if (self.epoch == self.swa_start):
self.swa_model = AveragedModel(self.learn.model)
print("Init SWA model")
def after_train(self):
if (self.epoch >= self.swa_start) and (self.epoch%self.cycle_len==0):
self.swa_model.update_parameters(self.model)
print("Updated SWA model")
update_bn(loader=self.dl, model=self.swa_model, device=self.dls.device)
print("Updated BN stats")
def before_validate(self):
if self.epoch >= self.swa_start:
self.old_model = self.learn.model
self.learn.model = self.swa_model
def after_validate(self):
if self.epoch >= self.swa_start:
self.learn.model = self.old_model
def after_fit(self):
if (self.epoch >= self.swa_start):
self.learn.model = self.swa_model
OOM issue seemed to be related to native fp16 not being used. So an alternative fix is:
class SWA(Callback):
"https://arxiv.org/abs/1803.05407"
def __init__(self, swa_start=0, cycle_len=1, every=2):
store_attr()
def before_epoch(self):
if (self.epoch == self.swa_start):
self.swa_model = AveragedModel(self.learn.model)
print("Init SWA model")
def after_train(self):
if (self.epoch >= self.swa_start) and (self.epoch%self.cycle_len==0):
self.swa_model.update_parameters(self.model)
print("Updated SWA model")
def before_validate(self):
if (self.epoch >= self.swa_start):
self.old_model = self.learn.model
self.learn.model = self.swa_model
def after_validate(self):
if (self.epoch >= self.swa_start):
self.learn.model = self.old_model
def after_fit(self):
if (self.epoch >= self.swa_start):
self.learn.model = self.swa_model
dl = self.dls.train.new(batch_size=self.dl.bs//2)
update_bn(loader=dl, model=self.swa_model, device=self.dls.device)
print("Updated BN stats")
I’ve tried both you version (commented out below) and a version where I tried to add the ability for users to choose not to update BN throughout (see below). With either version learn.validate() does not seem to match the validation metrics reported. I think for your code that’s obvious, because you do not updated BN throughout training. However, I got the same for my version, which has me a little concerned. This is my example I have been using:
from fastai.basics import *
from torch.optim.swa_utils import AveragedModel
from fastai.vision.all import *
#export
class SWA(Callback):
"Implementation of Stochastic Weight Averaging based on https://arxiv.org/abs/1803.05407"
def __init__(self, swa_start=0, cycle_len=1, swa_valid=True):
store_attr()
def before_epoch(self):
print(self.epoch)
if (self.epoch == self.swa_start):
self.swa_model = AveragedModel(self.learn.model)
print("Init SWA model")
def after_train(self):
# The if self.epoch>self.swa_start below is for when we use learn.fine_tune, which also leads to after_fit (assumption: SWA is only intended in 2nd stage of fine-tuning)
if (self.epoch >= self.swa_start) and (self.epoch%self.cycle_len==0):
self.swa_model.update_parameters(self.model)
print("Updated SWA model")
if (self.epoch > self.swa_start) and ((self.swa_valid==True) or (self.epoch+1==self.n_epoch)):
# half precision seems ineffective hence temporarily reducing bs =/ 2
dl = self.dls.train.new(c=self.dl.bs//2)
torch.optim.swa_utils.update_bn(loader=self.dl, model=self.swa_model, device=self.dls.device)
dl = self.dls.train.new(batch_size=self.dl.bs)
print("Updated BN stats")
def before_validate(self):
if (self.epoch >= self.swa_start) and (self.swa_valid==True):
self.old_model = self.learn.model
self.learn.model = self.swa_model
print("Replaced model before validation")
def after_validate(self):
if (self.epoch >= self.swa_start) and (self.epoch+1<self.n_epoch) and (self.swa_valid==True):
self.learn.model = self.old_model
print("Replaced model again after validation")
def after_fit(self):
if (self.epoch >= self.swa_start) and (self.epoch+1==self.n_epoch) and (self.swa_valid==False):
self.learn.model = self.swa_model
print("Replaced model with SWA model (only at final step)")
# class SWA(Callback):
# "https://arxiv.org/abs/1803.05407"
# def __init__(self, swa_start=0, cycle_len=1, every=2):
# store_attr()
# def before_epoch(self):
# if (self.epoch == self.swa_start):
# self.swa_model = AveragedModel(self.learn.model)
# print("Init SWA model")
# def after_train(self):
# if (self.epoch >= self.swa_start) and (self.epoch%self.cycle_len==0):
# self.swa_model.update_parameters(self.model)
# print("Updated SWA model")
# def before_validate(self):
# if (self.epoch >= self.swa_start):
# self.old_model = self.learn.model
# self.learn.model = self.swa_model
# def after_validate(self):
# if (self.epoch >= self.swa_start):
# self.learn.model = self.old_model
path = untar_data(URLs.PETS)/'images'
def is_cat(x): return x[0].isupper()
dls = ImageDataLoaders.from_name_func(path, get_image_files(path), valid_pct=0.2, seed=42,
label_func=is_cat, item_tfms=Resize(460), batch_size=128,
batch_tfms=aug_transforms(size=224))
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(freeze_epochs=1, epochs=6, base_lr=1e-3, cbs=SWA(swa_start=3)) #, swa_valid=False
learn.validate()
I’m getting:
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.411989 | 0.025326 | 0.008796 | 00:18 |
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.051684 | 0.008797 | 0.001353 | 00:22 |
| 1 | 0.036272 | 0.015122 | 0.003383 | 00:22 |
| 2 | 0.025214 | 0.005100 | 0.003383 | 00:23 |
| 3 | 0.018217 | 0.004636 | 0.002706 | 00:23 |
| 4 | 0.012118 | 0.023204 | 0.004060 | 00:31 |
| 5 | 0.008521 | 0.025356 | 0.006089 | 00:32 |
(#2) [0.005227192305028439,0.002706359839066863]
Notice how the output from learn.validate() is more favorable than the metrics in epoch 5 (and, yes, learn.validate() consistently gives the same result…).
I notice the same discrepancy you show. But when I compare state dict of both learner.model after fit and swa callback swa_model they appear to be same, so I am not sure why validation scores are different. Here is what I mean:
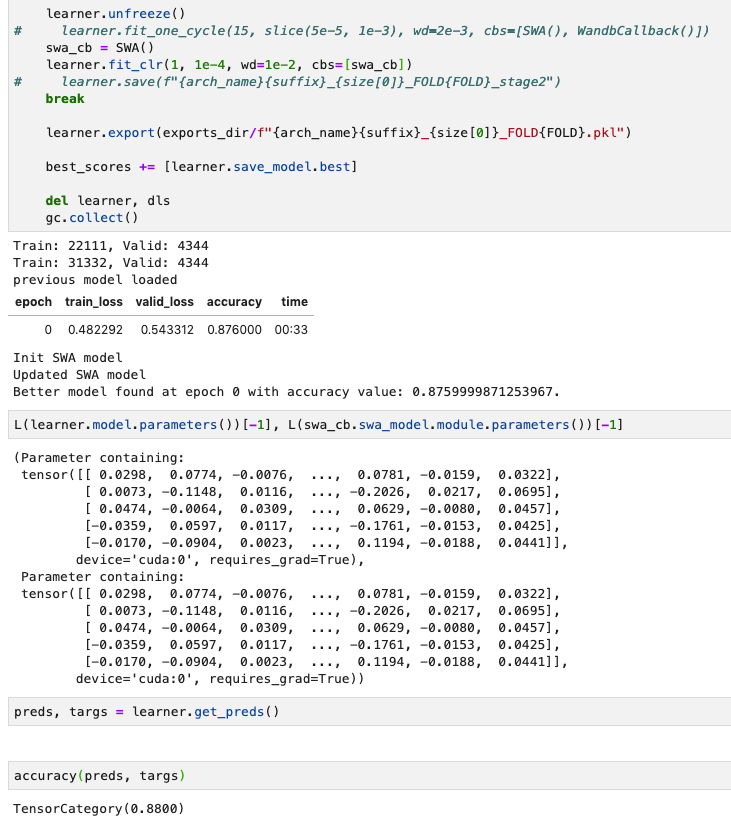
Yes. I know, there’s nothing that should change the parameters. I just find it really odd.
This test also passes:
model_state_dict = learner.model.state_dict()
swa_state_dict = swa_cb.swa_model.module.state_dict()
for k in model_state_dict:
assert torch.equal(model_state_dict[k], swa_state_dict[k])
OK! I found the issue TrainEvalCallback is the cb which puts our model in eval mode, so since SWA() is called after TrainEvalCallback our swa_model is never put into eval mode. Try the following cb below, it works for me.
from torch.optim.swa_utils import AveragedModel, update_bn
class SWA(Callback):
"https://arxiv.org/abs/1803.05407"
def __init__(self, swa_start=0, cycle_len=1):
store_attr()
def before_epoch(self):
if (self.epoch == self.swa_start):
self.swa_model = AveragedModel(self.learn.model)
print("Init SWA model")
def after_train(self):
if (self.epoch >= self.swa_start) and (self.epoch%self.cycle_len==0):
self.swa_model.update_parameters(self.model)
print("Updated SWA model")
if self.epoch == (self.n_epoch-1):
dl = self.dls.train.new(batch_size=self.dl.bs//2)
update_bn(loader=dl, model=self.swa_model, device=self.dls.device)
print("Updated BN stats")
def before_validate(self):
if (self.epoch >= self.swa_start):
self.old_model = self.learn.model
self.learn.model = self.swa_model.module
self.learn.model.eval() # TrainEvalCallback's order matter
def after_validate(self):
if (self.epoch >= self.swa_start):
self.learn.model = self.old_model
def after_fit(self):
if (self.epoch >= self.swa_start):
self.learn.model = self.swa_model.module
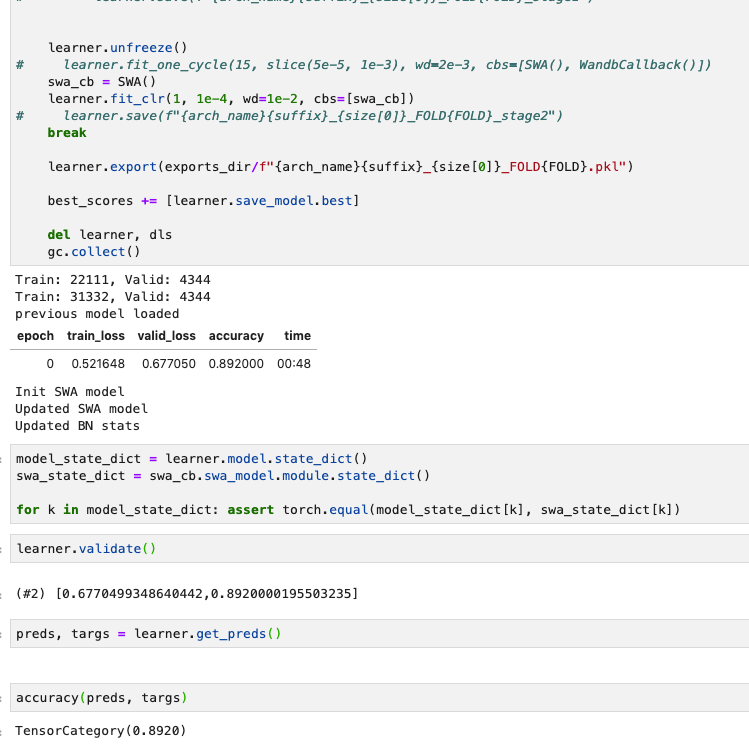
@deepgander Thanks a lot for noticing this bug before me!
Note: For those interested in CLR fitting, I am using the following (it’s an ugly modification of fit_sgdr  ):
):
@patch
def fit_clr(self:Learner, n_epoch, lr_max=None, cycle_mult=2, cbs=None, reset_opt=False, wd=None):
"Fit `self.model` for `n_cycles` of `cycle_len` using SGDR."
if self.opt is None: self.create_opt()
self.opt.set_hyper('lr', self.lr if lr_max is None else lr_max)
lr_max = np.array([h['lr'] for h in self.opt.hypers])
scheds = [SchedCos(lr_max, 0) for _ in range(n_epoch)]
pcts = [1./(n_epoch) for i in range(n_epoch-1)]
pcts += [1-sum(pcts)]
scheds = {'lr': combine_scheds(pcts, scheds)}
self.fit(n_epoch, cbs=ParamScheduler(scheds)+L(cbs), reset_opt=reset_opt, wd=wd)
3 Likes
It’s cyclical learning rate scheduler. You can find it’s reference in SWA paper.
Hello everyone,
My goal is to submit a PR containing a jupyter notebook I made that breaks down the steps to obtaining the keys for the Bing Search API. I am trying to follow the contributing guidelines, but I am having trouble installing git hooks with: nbdev_install_git_hooks
One method I have tried is through a command line (I am new to this):
I found “pull requests made easy” which brought me to downloading github desktop, I know enough that I do not want to PR to the master:
However, I feel that I should be executing the jupyter notebook from “pull requests made easy” , but I sadly cant figure out how to download it. I was able to get as far as installing the bash kernel:
I am honestly not sure what direction to head in. Any advice is greatly appreciated.
Learn.Predict() outputs an unwanted empty line to the console and this line can’t be removed.
For example if I try to predict for 100 sample, I will get 100 empty lines in the console output.
Is there anyway to prevent this?
Hello,
Newb here . Is this the active developer chat? First post says it is for fastai v1.
In any case, I would like to propose to enhance the error of .datablocks() when there are no items. Currently, it raises a very cryptic error ('NoneType' object is not iterable), on a line that makes it difficult to figure out what is going on:
fastai/data/core.py in setup(self, train_setup)
277 x = f(x)
278 self.types.append(type(x))
--> 279 types = L(t if is_listy(t) else [t] for t in self.types).concat().unique()
280 self.pretty_types = '\n'.join([f' - {t}' for t in types])
A beginner user (like me), cannot possibly figure out what the types have to do with their code.
It turns out, the call db.dataloaders(path) called with a wrong path results in this, as the items given by get_items() is an empty list.
I suggest to fail earlier if this is the case. For example, get_image_files() could return an error if none were found, or if the directory does not exist.
But this only fixes it for images. In addition, it should be fixed at DataBlock level, “here” (sorry, don’t know how to link to line of code in notebook).
What is the devs opinion on this ?
fastdebug does this Try it again and do:
!pip install fastdebug
from fastdebug import *
# Then run your code as normal
Oh, cool !
Yeap, seems to work quite nicely !
It also improves the error Could not do one pass in your DataLoader, there is something wrong in it, by putting a stack trace.
For that I guess I’ll open a separate question, don’t wanna spam dev chat 
Thanks a lot !
1 Like
Btw, @cipri_tom most of our developer chat and work happens on the fastai discord nowadays (Jeremy is there too!) so feel free to swing by on it and post in the fastai-dev channel https://discord.gg/hU4R6Ap