I have a possible dev implementation, I added onto recorder.plot another field, return_lr that returns the lr found by suggestion if it is true. Would this be valuable in the library?
I wanted to discuss here first before actually making a PR.
I have been thinking about making this change in the library but delayed it thinking it would be a minor thing. But I had to use this minor tweak in my personal code multiple times now, so thought it’s now time to discuss it here finally ![]()
Problem
TrackerCallback (and all of it’s children) doesn’t care for us people who is doing multi-stage training and with Fast.ai philosophy we almost always do multi-stage training via transfer learning.
Whenever we do the following steps learn.callback_fns are re-initialzied and hence their best value is re-initialized to (inf, -inf) based on your mode.
learn.fit()
learn.freeze_to(-2); learn.fit()
learn.unfreeze(); learn.fit()
We actually don’t want this in multi stage training because if best value is re-initialized, then a previous best model can be overwritten by an inferior model. Most can argue that
“Oh, but most of the time your later stage training will eventually be better than the best model of a preceding stage.”
Yes, this is probably the case for 99% of the cases where you pick a good learning rate and don’t mess up anything in the later stages, or your model actually benefits from training even the earliest layers.
But imagine running automated scripts, with auto lr find and running hundreds of experiments. In this case you wouldn’t have the guarantee of doing sanity checks. Yes, reading logs is a great way of seeing what happened but still why lose your best model even if it is only a bit better? It just doesn’t feel ok to me to let this go honestly ![]()
Fix
Fix is super simple.
- Add
best_inittoTrackerCallback:
class TrackerCallback(LearnerCallback):
"A `LearnerCallback` that keeps track of the best value in `monitor`."
def __init__(self, learn:Learner, monitor:str='valid_loss', mode:str='auto', best_init:float=None):
super().__init__(learn)
self.monitor,self.mode = monitor,mode
if self.mode not in ['auto', 'min', 'max']:
warn(f'{self.__class__} mode {self.mode} is invalid, falling back to "auto" mode.')
self.mode = 'auto'
mode_dict = {'min': np.less, 'max':np.greater}
mode_dict['auto'] = np.less if 'loss' in self.monitor else np.greater
self.operator = mode_dict[self.mode]
self.best_init = best_init
def on_train_begin(self, **kwargs:Any)->None:
"Initializes the best value."
if not self.best_init:
self.best = float('inf') if self.operator == np.less else -float('inf')
else: self.best = self.best_init
- New workflow
# 2) initialize TrackerCallback s with intermediate best value
def tracker_init(learn, best_init):
callback_fns = []
for cb_fn in learn.callback_fns:
if cb_fn.func.__base__ == fastai.callbacks.tracker.TrackerCallback:
cb_fn.keywords["best_init"] = best_init
cb_fn = partial(cb_fn.func, **cb_fn.keywords)
callback_fns.append(cb_fn)
learn.callback_fns = callback_fns
learn.fit()
learn = tracker_init(learn, learn.save_model_callback.best)
learn.freeze_to(-2); learn.fit()
learn = tracker_init(learn, learn.save_model_callback.best)
learn.unfreeze(); learn.fit()
Also we should add tracker_kwargs to each callback that inherits from TrackerCallback to allow initialization with new best_init argument
class EarlyStoppingCallback(TrackerCallback):
"A `TrackerCallback` that terminates training when monitored quantity stops improving."
def __init__(self, learn:Learner, monitor:str='valid_loss', mode:str='auto', min_delta:int=0, patience:int=0, **tracker_kwargs):
super().__init__(learn, monitor=monitor, mode=mode, **tracker_kwargs)
self.min_delta,self.patience = min_delta,patience
if self.operator == np.less: self.min_delta *= -1
Let me know what you think about this. Would it be really helpful? Am I missing anything? Let’s discuss!
Thanks
I’d put on hold any PR on callbacks since the mechanics are going to change a lot soon, when we start implementing the changes for v1.1.
Also note that if you instantiate your callback outside of the learner, and pass it in callbacks, it’s not going to be reset at each new training.
1 Like
Makes lot of sense thanks ![]()
Would it be ok to explore interpretations prior to v1.1 release for different type of tasks additional to ClassificationInterpretation? Maybe one parent class Interpretation for different tasks and implementing MultilabelClassification, Segmentation, etc… ?
I think it would be really nice to have a lot of good tools to have for post training to analyze and improve models further.
1 Like
That seems worth investigating yes. Actually it seems a very good idea 
If you make them all inherit from an Interpretation object that gather the predictions, losses and targets (with a from_learner class method like we have right now), then the tweaks you would have to do to keep it working with 1.1 would be minimal (if any).
1 Like
Hi everyone,
Not sure if this is the right topic to ask, but I’d like to know if it is OK to use the code from ImageCleaner in order to create a widget and how to give credits to the devs.
The widget will help people labeling images interactively inside a notebook. It is going to be open source and available on GitHub.
Also, I never contributed to a project before but I’d happily integrate the widget into the fastai library if you want to.
Cheers!
Mario
When will be released 1.1? are we talking about releasing it in days/weeks/months ?
A few weeks normally.
So, I followed your guidance.
-
Created a parent
Interpretationclass withfrom_learnerandtop_lossesmethods so far. Might add more methods which are task agnostic, e.g. sort by a given metric, etc… -
Made current
ClassificationInterpretationinherit from it. -
Created skeletons with
NotImplementedErrorforMultiLabelClassificationInterpretation,ObjectDetectionInterpretation,SegmentationInterpretation. -
Put everything to a module
interpret.py. -
Currently working on
SegmentationInterpretation:
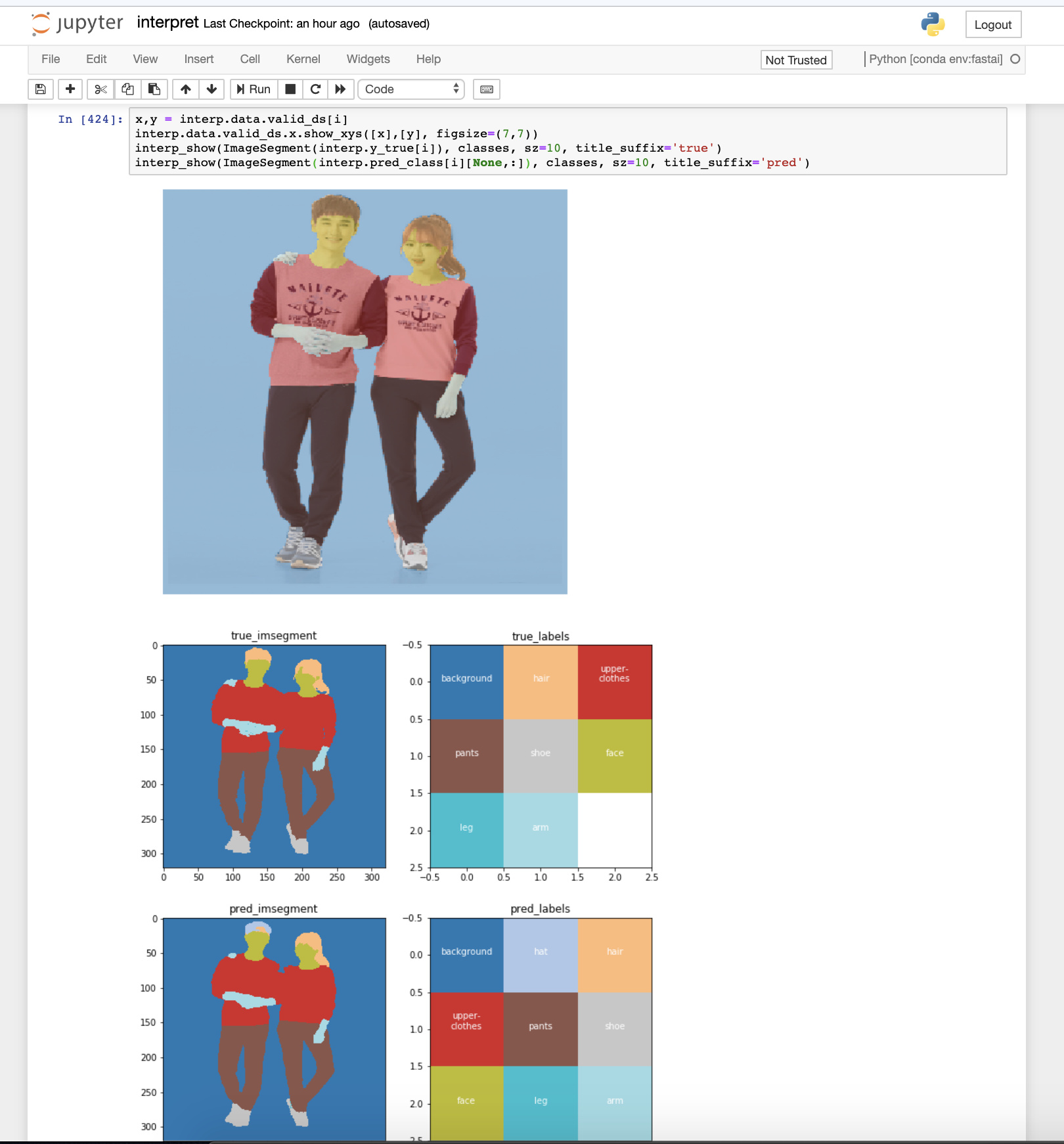
Should I create a PR with what I’ve done so far so that anyone can contribute, plus core devs can also review for feedback? Or should I keep working on it?
Thanks
Yes please, push what you have for now. It’s easier to merge incremental PRs.
1 Like
I noticed we can’t plot the top_losses for tabular data, and I feel as though this is important as when analyzing what went wrong in our model, or see what had difficulty, it can be beneficial to see what that value was, just like it is for image data. I have a plot_top_losses() function here that can do this. It is adapted from the image plot_top_losses() and inherits ClassificationInterpretation:
def plot_top_losses(self, k, largest = True, return_table:bool=False):
"Shows the respective rows in top_losses along with their prediction, actual, loss, and probability"
tl_val, tl_idx = self.top_losses(k)
classes = self.data.classes
cat_names = self.data.x.cat_names
cont_names = self.data.x.cont_names
df = pd.DataFrame(columns = [['Prediction', 'Actual', 'Loss','Prob'] + cat_names + cont_names])
for i, idx in enumerate(tl_idx):
da, cl = self.data.dl().dataset[idx]
cl = int(cl)
t1 = str(da)
t1 = t1.split(';')
arr = []
arr.append(classes[self.pred_class[idx]])
arr.append(classes[cl])
arr.append(f'{self.losses[idx]:.2f}')
arr.append(f'{self.probs[idx][cl]:.2f}')
for x in range(len(t1)-1):
_, value = t1[x].split()
arr.append(value)
df.loc[i] = arr
display(df)
if return_table: return df
Does this functionality plan to be released in 2.0 already?
Hi !
I’m working on simulated quantized networks (and generally speaking efficient deep learning) but the library lack this feature, while having quite a lot of other interesting ones. I did a general purpose class QuantizedNetwork(LearnerCallback) which I’m currently experimenting around with (mostly with binarized weights). If it’s of interest, I can do a PR to add this as an off the shelf callback. Could help people experiment around with low bitwidth networks.
I also have a few questions concerning the functionalities in Fastai :
- is adding Image Net dataset to the list of URLs possible ? mostly for convenience since there are quite a lot of others datasets already
- is there any plan to support pruning schemes in the library ? (following LTH, Supermasks, etc it may have some general interest to quickly toy around with pruning schemes)
- when exporting those low bitwidth quantized networks, I have superfluous callbacks and data inside the model. I maintain a copy of the learned parameters in FP16/32 and switch them around with on_batch_begin and on_batch_end. One could discard the FP16/32 data if the network is only used for inference. Further savings could be achieved with works like deep compression, custom CUDA kernels for binary ops, etc. Given 2.0 will bring a rework of callbacks, would you think it could be possible to run those kind of optimizations at export time (without rewriting locally part of the library) ?
- things like warm restarts, lamb optimizer that is mentioned in the patch note for v2, or simply that are in the doc and could be useful as is could maybe be added off the shelf in the library ? it would again allow to toy around with advanced things like we do with TTA, to_fp16, etc which are the bread and butter of Fast.ai
Edit : second modif since it seems I’m buzzing around the whole library this week
- learn.summary() is a great feature for a plain description of the layers of the model. However, since Fastai implement lots of tweaks and advanced stuff which are hidden for the user, it may be interesting to list all the “little things” at the end of learn.summary(). I.e. I spent 2 hours looking around the library, discovering bit by bit what’s happening behind the scene, to conclude that the basic model is already using AdamW without needing to worry about it (and trying things from posts of 2017 in the meantime
 ). I don’t know the shape of it, but it could lead to interesting discussions on what needs to be explicitly clear for the user, including the posts from the team that are really useful to grab the “good” tweak
). I don’t know the shape of it, but it could lead to interesting discussions on what needs to be explicitly clear for the user, including the posts from the team that are really useful to grab the “good” tweak 
3 Likes
This could be a interesting tool for debugging CUDA memory related issues:
GitHub repo:
1 Like
No, we’re not allowed to distribute this dataset. It’s on Kaggle though.
Not in the initial release, but it could be a nice contribution. We plan to do research on that in any case.
Both will probably be in the library in 2.0
That’s a very good idea (any PR to do this in v1 would be very welcome)!
1 Like
This is mostly a quality of life question/request but would it be possible to modify most_confused() to return a dataframe instead? Or is there reasoning not to have it as such.
Is it possible to remove ItemBase and derived classes from the project?
ItemBase being inside core.py and all derived classes as I checked are not used.
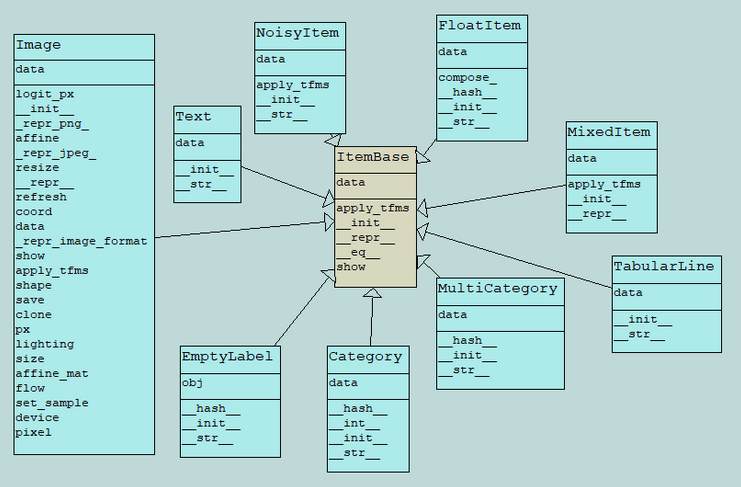
This would eliminate the possible confusion. Any feedback?
They are used any time you grab any data with fastai… so pretty much all the time.
@sgugger. Re approaching fast.ai v2. Are you going to change the way data loaders works for NLP? I’m thinking about enabling the following use cases:
- ability to train on super large dataset (the whole wikipedia) in fixed number of batches
- ability to re-tokenize content on the fly, it will let us use sentence piece subword regularisation as a way to get cheep data augmentation
- ability to implement weighted sampling to handle the cases where the data set is imbalanced.
All of this require modification to existing datasets, and since the v2 is going to change a lot of things we could try to change the design a bit to make the above use-cases possible.
Let me know your thoughts.
3 Likes
The new callback system will support anything the current one does, so training for a fixed nulber of batch will be possible.
Tokenization will be a separate command to run in v2: to be able to run without loading the whole dataset in RAM it will duplicate the way your data is structured (new folder with tokenized texts, new dataframe or new csv file). Tokenizing on the fly can also be added by use of tranforms (which will be more developed in v2).
I think weighted sampling is already possible in v1.