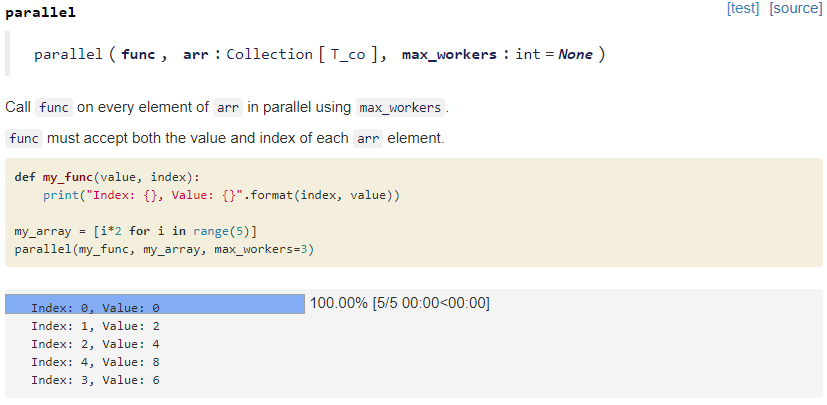
I’ve been looking closely at parallel (fastai.core). It takes a function (func) and a collection (arr) and calls func on each element of arr (in parallel).
Does anyone here know why forces the function you provide func to accept both the value and index of each element in arr? This means you have to write a new function that is a copy of your old one, but accepts an additional input index that it never uses. In the source code it calls
Thank you, that’s what I’ve been doing but wasn’t sure if a better way was possible. I’ve also noticed it fails more or less silently when you pass in a function that hasn’t been altered to accept an index. The progress bar completes to 100% in 0:00 but the function doesn’t get run. The full documentation makes it really clear, but the in notebook documentation doesn’t mention the existence of an index. I can add these as issues, but I’m really new and wanted to make sure this wasn’t expected behavior.
This next question is a bit off topic and I know you’re incredibly busy, so no worries if you don’t have time to reply. Any advice on best practice for using parallel when you have a function that takes more than one argument? My approach has been if the other arguments are static, to use a partial, but if the other arguments are variable, to change the function to accept one argument that is actually a tuple of arguments (and the index of course), and then pack and pass in a collection of tuples. I’ve written a post on the nuances of parallel to teach others to use it and I’d really like to get it right. Thank you.
That seems the right way to do it, yes. Also note that this is just a convenience function for our internal use, which just takes a few lines of code, so you can rewrite your own version whenever it’s needed
My apologies @sgugger I didn’t see that the is_in_colab has changed. It was a mistake I made by looking at the latest released version codebase on conda (where it is a problem) and the latest changes where it is indeed no longer needed. Please ignore my initial report.
I’m really having a difficult time figuring out how to implement my own BatchSampler in fastai. I’ve successfully implemented other training-time tweaks using the Callbacks API, but for the life of me, I can’t figure out how to implement my own method for batch-wise sampling from a dataset. I’ve tried simply replacing data.train_dl.batch_sampler after the fact, but I can’t tell if that even works, and it’s not clear to me that implementing batch sampling is possible via callbacks.
There are low-level PyTorch implementations that are floating around out there, but they all exist within the PyTorch training context, and I’m finding the implementations rather opaque coming from a fastai-first mindset.
Hi I would like to ask about discriminative learning rates. I want to have different optimizers for different layers (like Adam and SGD …) Anyone else looking at this? Not sure how hard it is to tweak the code so it can handle different optimizers.
Hey, thanks for the idea but it looks like you can’t blindly pass a lambda to parallel because at some stage in the pipeline it gets pickled and python is picky about pickling lambdas. There is a way to do it but it didnt seem advantageous over just making a function copy since this is mostly for preprocessing and not production code. I could be implementing it wrong though.
Here’s what I did. Code’s a bit messy, but it zips all the args together in a tuple, and instead of rewriting my function to accept a tuple (since parallel only takes functions that accept 1 arg), I make a lambda that calls my function after unpacking the tuple. If I run my lambda manually in line 3 it works, if I pass to parallel it blows up and I get the error at bottom for all threads.
Ohhhh, that’s where it is. I was digging around for which method would accept batch_sampler as a keyword, but I just couldn’t find it. I will have to try that, thanks! I figured you’d have an answer.
Hello all!
In SF study group I discussed with Jeremy possibility of making lazy evaluating DataBlock API. I spent few evenings and made proof of concept notebook - what can be better/different, how we can do it without breaking current API, how it will change data processing flow, how it will look like and where we can go from there. Please check notebook in this Pull Request or by this link - in GitHub interface (all cells were evaluated with latest dev install of fastai from a few days ago).
I think it is possible to do (and easy, because every step wrapped in abstraction) any defaults/presets for specific tasks. For example in my proposed prototype we can add some param in initializer of DataChain - what kind of databunch we want to get in the end - and if it’s possible - it will preset specific blocks/steps if possible (it will create LabelBlock with assemble_fn='label_from_lm' because it’s default for LM databunch).
Hi Sylvain, just to confirm, right now the TrainingPhase does not have the opt_func argument like the previous version right? I’m thinking of using different optimizers.
Sylvain, while I was developing custom loss function, I’ve noticed that the get_preds adds the activation to the logits when it recognize the loss and it does not otherwise.
It took me quite some time to figure out why my custom metric functions don’t work when I change the loss to one recognized by fastai, and they work just fine with my custom loss function.
I understand why we have such dependency between loss and the get_preds but it is surprising, as loss is in realms of training and get_preds in realms of inference this two should not depend on each other.
Would you consider moving the activation function to the model it self ? That way we break the dependency between of loss and the get_preds and we make the library a bit easier to reason about.
Another option would be to simply show a warning when user has custom loss and he uses get_preds.