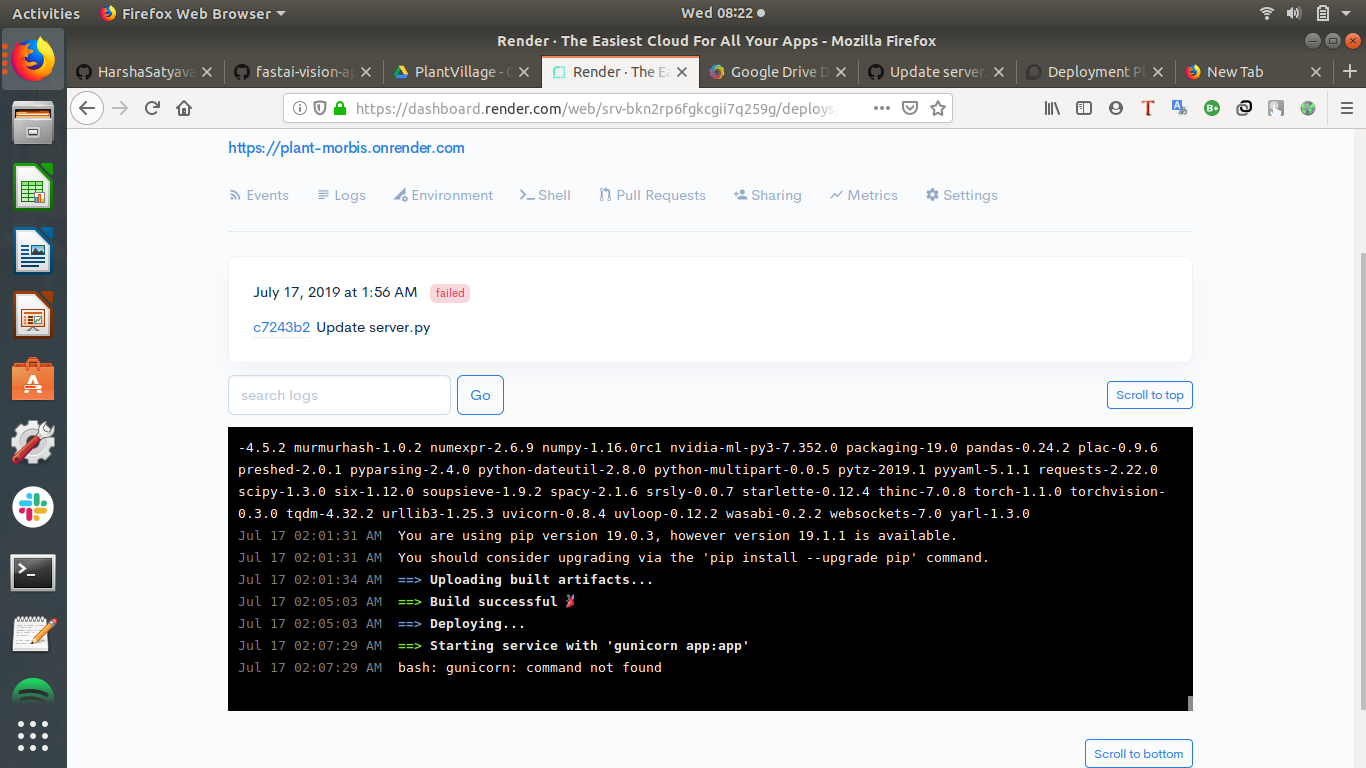
i am unable to deploy my app.it is saying gunicorn command not found.i tried keeping gunicorn in requirements.txt after that also its popping up the same error
Hi harshasatyavardhan
Have you tried adding
RUN pip install gunicorn
After the requirements line in the file called “Dockerfile” located in the repository.
Cheers mrfabulous1 
Worked well thanks
Hi Zachery I have also looked and the classes list and it is definitely not a requirement for the app to work.
It is my understanding that it is there for the following reasons.
- To enable class names to be used in any app you develop more easily.
- As a reference to make it easier to remember what classes were used in your app when you look back at the software in a years time.
If it were not there you would have to extract them from the .pkl file.
Cheers mrfabulous1
1 Like
Thanks mrfabulous! Yeah I realized I think it’s being used for the website (I saw it referenced in the javascript I believe). For anyone interested, at my campus I gave that talk on deployment and went over a few different models. Here’s the notebook: (The front end is awful, I am not a front-end dev so just focus on how the back-end is operating)
notebook
1 Like
Hi Zachery thanks for sharing your notebook!
mrfabulous1
No problem! Do note it’s a general guide on how to structure the inference and data collection. Don’t run the notebook  (I’ve just gotten addicted to writing notes this way)
(I’ve just gotten addicted to writing notes this way)
It does work, but depending on the plan you select it can take a REALLY long time to process a large image due to the low ram (1GB) and number cpus (1) of the lowest plans.
If you want more speed I’d look at increasing the ram and cpu of the instance, or hosting on a service which provides a gpu
I am also having this issue. I developed my model locally on my desktop PC in Jupyter.
Anyone come up with a solution yet?
Hi Matt this problem took me ages to fix, and I didn’t get a reply to this question.
I had to install uvicord 0.7.1 however I was unable to install it using Anaconda.
So from anaconda I had to:
- Open the terminal
- pip install uvicorn
When I built my bear classifier it was version 0.7.1 its now 0.8.4
Hope this helps
mrfabulous1
Hi mrfabulous1,
Thanks for your update. If I am interpreting what you saying correctly, I need to:
- Pip install uvicorn locally on my desktop
- Re-run my model training after installing uvicorn
- Upload the new exported .pkl file
- Deploy on Render.
Is that the fix that worked for you?
Hi Matt that is correct if.
Once you get it working on your desktop the fun begins when you deploy it.
The render guide is good however it is likely you may have a few issues deploying it. So check the posts on this thread.
On point 3 your library versions on your laptop may be different to the repository. So you may have to change the requirements.txt when you deploy the code on render.com. See the threads which contain !pip list for an explanation.
Cheers mrfabulous1:smiley:
1 Like
If want to host you model on Google Drive and still have the problem of not being able to download the large, this is the code I´ve used on server.py, it replaces the function download_file():
Note that now instead of the url, you just pass the id of the file:
model_file_id = '19xqtsyusFddcSkdCm1hlhW3y6ljGck5L'
def download_file_from_google_drive(id, destination):
if destination.exists():
return
URL = "https://docs.google.com/uc?export=download"
session = requests.Session()
response = session.get(URL, params = { 'id' : id }, stream = True)
token = get_confirm_token(response)
if token:
params = { 'id' : id, 'confirm' : token }
response = session.get(URL, params = params, stream = True)
save_response_content(response, destination)
def get_confirm_token(response):
for key, value in response.cookies.items():
if key.startswith('download_warning'):
return value
return None
def save_response_content(response, destination):
CHUNK_SIZE = 32768
with open(destination, "wb") as f:
for chunk in response.iter_content(CHUNK_SIZE):
if chunk: # filter out keep-alive new chunks
f.write(chunk)
async def setup_learner():
download_file_from_google_drive(model_file_id, path/'models'/f'{model_file_name}.pth')
data_bunch = ImageDataBunch.single_from_classes(path, classes,
ds_tfms=get_transforms(), size=224).normalize(imagenet_stats)
learn = cnn_learner(data_bunch, models.resnet34, pretrained=False)
learn.load(model_file_name)
return learn
Did Render start charging fastai students? I noticed an email telling me to add a credit card and also an unpaid bill.
Yes, Render has always charged for compute, but a few months ago we added $25 in credits to new accounts. I believe you got an email because your credits ran out.
1 Like
Thanks for clarifying.
Hello everyone! I’ve deployed my model on Render but the website seems to be stuck on the “Analyzing…” mode. Looking through the logs, I do see prediction = learn.predict(img)[0] so I know it’s predicting, but no result shows on the website.
The error in the Render logs I get is AttributeError: ‘Conv2d’ object has no attribute ‘padding_mode’. Any help / advice?
Thanks in advance and thanks @anurag for Render!
1 Like
I get this same error when trying to predict:
img = data.test_ds[0][0]
learn.predict(img)
~/.conda/envs/fastai_v1_2/lib/python3.7/site-packages/fastai/torch_core.py in <listcomp>(.0)
325 def grab_idx(x,i,batch_first:bool=True):
326 "Grab the `i`-th batch in `x`, `batch_first` stating the batch dimension."
--> 327 if batch_first: return ([o[i].cpu() for o in x] if is_listy(x) else x[i].cpu())
328 else: return ([o[:,i].cpu() for o in x] if is_listy(x) else x[:,i].cpu())
329
AttributeError: 'list' object has no attribute 'cpu'
Did you ever work out what was wrong?
Hi wigglepuff hope all is well!
Having created a number of different models now, all but one of the faults when deploying the model assuming it works in development, have been resolved in one of two ways, unless I made a mistake in configuring the model or building the app.
- I have read that fastai is generally not backwards compatible as many of the libraries such as pytorch are upgraded independently. So almost every time I create a model in Jupyter notebook by the time I have spent a day or week completing the training and building the app various libraries have been changed.
The solution to this if you are using the teddy bear template as the basis for your app, is to use !pip list and confirm that the library versions used in your development environment that you trained the model in are the same on render. You normally have to change the versions in the requirements.txt. search this forum topic for !pip list. for further details.
- My models seem to have a problem with my current version of Safari.
My solution test in all the top browsers.
Hope this helps mrfabulous1
2 Likes
I had expected it was a version discrepancy but had no idea how to address it, thank you @mrfabulous1!! Did exactly as you recommended and it worked perfectly.
Now I can finally help my friends decide if they look more like Brad Pitt or Elon Musk 
(Thanks again! Wow!)