Hi All,
Apologies for the delay, I’ve got too many side projects going on, and training the language model took me about 30 mins / epoch, which I will have to investigate later. Here’s the notes from lecture 10. Looks like the readling list is growing with some good paper suggestions!
- Tim
Lesson 10
NLP Classification and Translation
We are going to look at NLP this week
Review of Object Detection:
- See Lesson 8 / Lesson 9
NLP
Introduction
Recall in image classification, with conv_learner it has a standard way to stick a layer ontop (any custom head) and have it do anything we like. Now we have flexibility to understand rotations, or solve other interesting problems. Lets take this concept and apply this to text.
NLP + Computer vision techniques Roadmap:
- Learn to find word structures from images aka, captioning
- Learn to find images to word structures
- Learn to find images from images
- Image enhancement - upscaling low photos into high res
- Segmenting a picture into objects
torchtext to fastai.text
torchtext is great, but its slow, it doesn’t run in parallel, and it doesn’t remember. fastai.text is a combination of torchtext and fastai.nlp. Consider fastai.nlp deprecated (outdated) at this point.

Import libraries
import sys
sys.path.append('../')
from fastai.text import *
import html
IMDB - Internet Movie Database
Get the dataset
!wget http://files.fast.ai/data/aclImdb.tgz
!tar -xf aclImdb.tgz
Check the file directories:
!ls ~/data/aclImdb/
->imdbEr.txt imdb.vocab README test train
Check the file counts
!ls /home/paperspace/data/aclImdb/train/all | wc -l
75000
!ls /home/paperspace/data/aclImdb/test/all | wc -l
25000
Look at directories
!ls /home/paperspace/data/aclImdb/
imdbEr.txt imdb.vocab models README test tmp train
!ls /home/paperspace/data/aclImdb/train
all neg unsup urls_neg.txt urls_unsup.txt
labeledBow.feat pos unsupBow.feat urls_pos.txt
Create a CLAS - classification and LM - language model
# create paths to save future features
CLAS_PATH=Path('/home/paperspace/data/imdb_clas/')
CLAS_PATH.mkdir(exist_ok=True)
LM_PATH=Path('/home/paperspace/data/imdb_lm/')
LM_PATH.mkdir(exist_ok=True)
BOS = 'xbos' # beginning-of-sentence tag
FLD = 'xfld' # data field tag
CLASSES = ['neg', 'pos', 'unsup']
PATH=Path('/home/paperspace/data/aclImdb/')
Turning Text into Numbers
- How do we turn sentences into numbers?
First lets prepare the imdb dataset, by creating a panda dataframe from the collection of .txt files
def get_texts(path):
"""
This function will go through the aclImdb folder
and create the necessary datasets
"""
# initializes the text and labels collections
texts,labels = [],[]
# for each sentiment
for idx,label in enumerate(CLASSES):
# will go through the
for fname in (path/label).glob('*.*'):
# open the file and append the filetext
texts.append(fname.open('r').read())
# open
labels.append(idx)
return np.array(texts),np.array(labels)
trn_texts,trn_labels = get_texts(PATH/'train')
val_texts,val_labels = get_texts(PATH/'test')
Look at a sample of the text
trn_labels[0],trn_texts[0]
(0,
"Basically, Cruel Intentions 2 is Cruel Intentions 1, again, only poorly done. The story is exactly the same as the first one (even some of the lines), with only a few exceptions. The cast is more unknown, and definitely less talented. Instead of being seductive and drawing me into watching it, I ended up feeling dirty because it compares to watching a soft-core porn. I'm not sure whether to blame some of the idiotic lines on the actors or the writers...and I always feel bad saying that, because I know how hard it is to do both...but it was basically a two-hour waste of my life. It literally amazes me that some movies get made, and this is no exception...I can't believe they'd make a third one.")
Prepare dataframe
col_names = ['labels','text']
np.random.seed(42)
# shuffle the indexes in place
trn_idx = np.random.permutation(len(trn_texts))
val_idx = np.random.permutation(len(val_texts))
#shuffle texts
trn_texts = trn_texts[trn_idx]
val_texts = val_texts[val_idx]
#shuffle the labels
trn_labels = trn_labels[trn_idx]
val_labels = val_labels[val_idx]
#create dataframe
df_trn = pd.DataFrame({'text':trn_texts, 'labels':trn_labels}, columns=col_names)
df_val = pd.DataFrame({'text':val_texts, 'labels':val_labels}, columns=col_names)
# saving training and validation dataset
df_trn[df_trn['labels']!=2].to_csv(CLAS_PATH/'train.csv', header=False, index=False)
df_val.to_csv(CLAS_PATH/'test.csv', header=False, index=False)
#write the classes
(CLAS_PATH/'classes.txt').open('w').writelines(f'{o}\n' for o in CLASSES)
Create trn and validation texts with different test size
from sklearn.model_selection import train_test_split
trn_texts,val_texts = train_test_split(np.concatenate([trn_texts,val_texts]), test_size=0.1)
len(trn_texts), len(val_texts)
(90000, 10000)
Create Language model LM dataframes and save
df_trn = pd.DataFrame({'text':trn_texts, 'labels':[0]*len(trn_texts)}, columns=col_names)
df_val = pd.DataFrame({'text':val_texts, 'labels':[0]*len(val_texts)}, columns=col_names)
df_trn.to_csv(LM_PATH/'train.csv', header=False, index=False)
df_val.to_csv(LM_PATH/'test.csv', header=False, index=False)
Language Model Tokens
- tokenization - turn a sentence into words with some specific rules, correcting for puncutation.
-
fixup()- there’s always strange encodings in text, here are a couple that will replace some outlier characters -
get_texts()- will iterate through all files and collect the in-file text -
get_all()- will callget_texts()repeatedly for each row of the dataframe, pulling text from the source text files and returning tokens and labels
Reference
Tokenizer().proc_all_mp(partition_by_cores(texts))
proc_all_mp function
def proc_all_mp(ss, lang='en'):
ncpus = num_cpus()//2
with ProcessPoolExecutor(ncpus) as e:
return sum(e.map(Tokenizer.proc_all, ss, [lang]*len(ss)), [])
partition_by_cores function
def partition_by_cores(a):
return partition(a, len(a)//num_cpus() + 1)
ProcessPoolExecutor is from a Python 3 standard library:
More on multiprocessing
# generalized use of ProcessPoolExecutor
import concurrent.futures
def main():
with concurrent.futures.ProcessPoolExecutor() as executor:
for number, prime in zip(PRIMES, executor.map(is_prime, PRIMES)):
print('%d is prime: %s' % (number, prime))
"""
when given to pandas, it won't return a full dataframe,
but it will return an iterator. It will return sub-sized chunks
over and over again
"""
chunksize=24000
re1 = re.compile(r' +')
def fixup(x):
""" Cleans up erroroneus characters"""
x = x.replace('#39;', "'").replace('amp;', '&').replace('#146;', "'").replace(
'nbsp;', ' ').replace('#36;', '$').replace('\\n', "\n").replace('quot;', "'").replace(
'<br />', "\n").replace('\\"', '"').replace('<unk>','u_n').replace(' @.@ ','.').replace(
' @-@ ','-').replace('\\', ' \\ ')
return re1.sub(' ', html.unescape(x))
def get_texts(df, n_lbls=1):
# pull the labels out from the dataframe
labels = df.iloc[:,range(n_lbls)].values.astype(np.int64)
# pull the full FILEPATH for each text
# BOS is a flag to indicate when a new text is starting
texts = f'\n{BOS} {FLD} 1 ' + df[n_lbls].astype(str)
# Sometimes, text has title, or other sub-sections. We will record all of these
for i in range(n_lbls+1, len(df.columns)): texts += f' {FLD} {i-n_lbls} ' + df[i].astype(str)
texts = texts.apply(fixup).values.astype(str)
# Tokenize the data
tok = Tokenizer().proc_all_mp(partition_by_cores(texts))
return tok, list(labels)
def get_all(df, n_lbls):
tok, labels = [], []
for i, r in enumerate(df):
print(i)
tok_, labels_ = get_texts(r, n_lbls)
tok += tok_;
labels += labels_
return tok, labels
Install Spacy if you don’t have it
!pip install spacy
Requirement already satisfied: spacy in /home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages
Requirement already satisfied: numpy>=1.7 in /home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages (from spacy)
Requirement already satisfied: murmurhash<0.29,>=0.28 in /home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages (from spacy)
Requirement already satisfied: cymem<1.32,>=1.30 in /home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages (from spacy)
Requirement already satisfied: preshed<2.0.0,>=1.0.0 in /home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages (from spacy)
Requirement already satisfied: thinc<6.11.0,>=6.10.1 in /home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages (from spacy)
Requirement already satisfied: plac<1.0.0,>=0.9.6 in /home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages (from spacy)
Requirement already satisfied: six in /home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages (from spacy)
Requirement already satisfied: html5lib==1.0b8 in /home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages (from spacy)
Requirement already satisfied: pathlib in /home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages (from spacy)
Requirement already satisfied: ujson>=1.35 in /home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages (from spacy)
Requirement already satisfied: dill<0.3,>=0.2 in /home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages (from spacy)
Requirement already satisfied: requests<3.0.0,>=2.13.0 in /home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages (from spacy)
Requirement already satisfied: regex==2017.4.5 in /home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages (from spacy)
Requirement already satisfied: ftfy<5.0.0,>=4.4.2 in /home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages (from spacy)
Requirement already satisfied: msgpack-python==0.5.4 in /home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages (from spacy)
Requirement already satisfied: msgpack-numpy==0.4.1 in /home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages (from spacy)
Requirement already satisfied: wrapt in /home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages (from thinc<6.11.0,>=6.10.1->spacy)
Requirement already satisfied: tqdm<5.0.0,>=4.10.0 in /home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages (from thinc<6.11.0,>=6.10.1->spacy)
Requirement already satisfied: cytoolz<0.9,>=0.8 in /home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages (from thinc<6.11.0,>=6.10.1->spacy)
Requirement already satisfied: termcolor in /home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages (from thinc<6.11.0,>=6.10.1->spacy)
Requirement already satisfied: chardet<3.1.0,>=3.0.2 in /home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages (from requests<3.0.0,>=2.13.0->spacy)
Requirement already satisfied: idna<2.7,>=2.5 in /home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages (from requests<3.0.0,>=2.13.0->spacy)
Requirement already satisfied: urllib3<1.23,>=1.21.1 in /home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages (from requests<3.0.0,>=2.13.0->spacy)
Requirement already satisfied: certifi>=2017.4.17 in /home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages (from requests<3.0.0,>=2.13.0->spacy)
Requirement already satisfied: wcwidth in /home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages (from ftfy<5.0.0,>=4.4.2->spacy)
Requirement already satisfied: toolz>=0.8.0 in /home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages (from cytoolz<0.9,>=0.8->thinc<6.11.0,>=6.10.1->spacy)
Download English Model
!python -m spacy download en
Collecting https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-2.0.0/en_core_web_sm-2.0.0.tar.gz
Downloading https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-2.0.0/en_core_web_sm-2.0.0.tar.gz (37.4MB)
e[K 100% |████████████████████████████████| 37.4MB 6.7MB/s ta 0:00:0111
e[?25h Requirement already satisfied (use --upgrade to upgrade): en-core-web-sm==2.0.0 from https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-2.0.0/en_core_web_sm-2.0.0.tar.gz in /home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages
e[93m Linking successfule[0m
/home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages/en_core_web_sm
-->
/home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages/spacy/data/en
You can now load the model via spacy.load('en')
import spacy
nlp = spacy.load('en')
Read in our Language model data, extract texts
__spec__ = "ModuleSpec(name='builtins', loader=<class '_frozen_importlib.BuiltinImporter'>)"
df_trn = pd.read_csv(LM_PATH/'train.csv', header=None, chunksize=chunksize)
df_val = pd.read_csv(LM_PATH/'test.csv', header=None, chunksize=chunksize)
tok_trn, trn_labels = get_all(df_trn, 1)
tok_val, val_labels = get_all(df_val, 1)
0
1
2
3
0
Make working tmp directory & save tokens
(LM_PATH/'tmp').mkdir(exist_ok=True)
np.save(LM_PATH/'tmp'/'tok_trn.npy', tok_trn)
np.save(LM_PATH/'tmp'/'tok_val.npy', tok_val)
Load tokenization & check top tokens
tok_trn = np.load(LM_PATH/'tmp'/'tok_trn.npy')
tok_val = np.load(LM_PATH/'tmp'/'tok_val.npy')
freq = Counter(p for o in tok_trn for p in o)
freq.most_common(25)
[('the', 1208449),
('.', 992545),
(',', 986614),
('and', 587567),
('a', 583520),
('of', 525412),
('to', 484871),
('is', 393923),
('it', 341485),
('in', 337351),
('i', 307751),
('this', 270410),
('that', 261107),
('"', 237920),
("'s", 222037),
('-', 188209),
('was', 180235),
('\n\n', 179009),
('as', 166145),
('with', 159253),
('for', 158601),
('movie', 157735),
('but', 150659),
('film', 144618),
('you', 123979)]
recreate a single entry
-
xbos- start stream -
xfld- start field - word on caps - how do get the semantic impact of CAPS vs. normal version?
-
t_up- add a tag in front to indicate the next word is uppercase
' '.join(tok_trn[0])
'\n xbos xfld 1 i saw this movie at the dragon*con 2006 independent film festival . it was awarded 2 awards at that festival and rightfully so . this is probably the best short horror film i \'ve ever seen . the simplicity of camera usage really works.the main character is brilliant . his acting is quite good and is believable . the 3 cameras in the room with tim russel make his insanity that much more believable . i love it . i have talked with mike and he says that they are in the process of making a feature film compassing the first three chapters together . i ca n\'t wait . i will be first in line for that film . the effects of the " mirror " creatures are used so well . you do n\'t see them for very long so it scares the pants off of you when you do . i recommend this film to anyone who wants to watch a good horror movie for once . best 32 minutes of spine tingling horror i \'ve ever seen . thanks mike .'
Setup the Vocabulary and add a term for unknown and for padding
max_vocab = 60000
min_freq = 2
# index to word
itos = [o for o,c in freq.most_common(max_vocab) if c>min_freq]
itos.insert(0, '_pad_')
itos.insert(0, '_unk_')
# word to index
stoi = collections.defaultdict(lambda:0, {v:k for k,v in enumerate(itos)})
print(len(itos))
# create a array of token_indices
trn_lm = np.array([[stoi[o] for o in p] for p in tok_trn])
val_lm = np.array([[stoi[o] for o in p] for p in tok_val])
# save the i
np.save(LM_PATH/'tmp'/'trn_ids.npy', trn_lm)
np.save(LM_PATH/'tmp'/'val_ids.npy', val_lm)
pickle.dump(itos, open(LM_PATH/'tmp'/'itos.pkl', 'wb'))
60002
Example of a numerical representation
' '.join([str(val) for val in trn_lm[0]])
'40 41 42 39 12 235 13 23 44 2 0 3368 1662 25 1331 3 10 18 8833 261 2474 44 14 1331 5 9383 51 3 13 9 263 2 138 364 200 25 12 159 143 129 3 2 5416 7 371 9080 83 58696 305 122 9 556 3 35 136 9 204 66 5 9 842 3 2 379 3992 11 2 655 21 1895 13095 113 35 4853 14 93 67 842 3 12 133 10 3 12 36 3515 21 1555 5 34 566 14 45 33 11 2 1648 7 251 6 820 25 0 2 105 299 8000 312 3 12 196 29 881 3 12 104 37 105 11 367 22 14 25 3 2 306 7 2 15 3006 15 2204 33 345 51 88 3 26 57 29 82 111 22 69 216 51 10 2702 2 3719 141 7 26 68 26 57 3 12 404 13 25 8 273 48 505 8 126 6 66 200 23 22 301 3 138 13558 249 7 7191 21684 200 12 159 143 129 3 1179 1555 3'
Load from checkpoint
trn_lm = np.load(LM_PATH/'tmp'/'trn_ids.npy')
val_lm = np.load(LM_PATH/'tmp'/'val_ids.npy')
itos = pickle.load(open(LM_PATH/'tmp'/'itos.pkl', 'rb'))
vs=len(itos)
vs,len(trn_lm)
(60002, 90000)
Instead of pretraining on imagenet, for NLP we will use a large subset of wikipedia
Previously in lesson 4, we trained a language model that was state of the art. Using a pre-selected text articles from wikipedia, a language model was trained, and the weights were saved.
wikitext103 model - weights
#! wget -nH -r -np -P {PATH} http://files.fast.ai/models/wt103/
How to use a pretrained model - must have same network sizes
-
em_sz- embedding sizes for vectors (400) -
nh- number of hidden (# of activations) -
nl- number of layers (hidden) -
model type: AWD LSTM link
Some work will have to be done to map the pre-trained vocabulary to the current vocab that we are working with. Any words not found in pre-trained vocab, we will use global mean values.
em_sz,nh,nl = 400,1150,3
# set filepaths
PRE_PATH = PATH/'models'/'wt103'
PRE_LM_PATH = PRE_PATH/'fwd_wt103.h5'
# load weights (returns a dictionary)
wgts = torch.load(PRE_LM_PATH, map_location=lambda storage, loc: storage)
# pull out embedding weights
# sized vocab x em_sz
enc_wgts = to_np(wgts['0.encoder.weight'])
row_m = enc_wgts.mean(0)
# load pre trained vocab to index mappings
itos2 = pickle.load((PRE_PATH/'itos_wt103.pkl').open('rb'))
stoi2 = collections.defaultdict(lambda:-1, {v:k for k,v in enumerate(itos2)})
# create a pre-trained -> current corpus vocab to vocab mapping
# initialize an empty matrix
new_w = np.zeros((vs, em_sz), dtype=np.float32)
# loop through by row index and insert the correct embedding
for i,w in enumerate(itos):
r = stoi2[w]
new_w[i] = enc_wgts[r] if r>=0 else row_m
# create our torch `state` that we will load later
wgts['0.encoder.weight'] = T(new_w)
wgts['0.encoder_with_dropout.embed.weight'] = T(np.copy(new_w))
wgts['1.decoder.weight'] = T(np.copy(new_w))
Language Model Creation
-
wd- weight decay -
bptt- back prop through time -
bs- batchsize
We will be performing a continuous process of
given words --> predict next word
Lesson 4 - note the best loss
[ 0. 4.3926 4.2917]
[ 1. 4.37693 4.28255]
[ 2. 4.37998 4.27243]
[ 3. 4.34284 4.24789]
[ 4. 4.3287 4.2317]
[ 5. 4.28881 4.20722]
[ 6. 4.24637 4.18926]
[ 7. 4.23797 4.17644]
Pretrained Model - we already start with a better score
epoch trn_loss val_loss accuracy
0 4.332359 4.120674 0.289563
1 4.247177 4.067932 0.294281
Comparison to Word2Vec
Word2Vec - single embedding matrix. Each word has a matrix and thats it. It’s a single layer (input) from a pretrained model. It’s from a linear model on a co-occurance matrix.
wd=1e-7
bptt=70
bs=52
opt_fn = partial(optim.Adam, betas=(0.8, 0.99))
trn_dl = LanguageModelLoader(np.concatenate(trn_lm), bs, bptt)
val_dl = LanguageModelLoader(np.concatenate(val_lm), bs, bptt)
md = LanguageModelData(PATH, 1, vs, trn_dl, val_dl, bs=bs, bptt=bptt)
drops = np.array([0.25, 0.1, 0.2, 0.02, 0.15])*0.7
learner= md.get_model(opt_fn, em_sz, nh, nl,
dropouti=drops[0], dropout=drops[1], wdrop=drops[2], dropoute=drops[3], dropouth=drops[4])
learner.metrics = [accuracy]
learner.unfreeze()
Language Model Components:
1. DataLoader
2. ModelData
3. Model
1. Language Model Loader
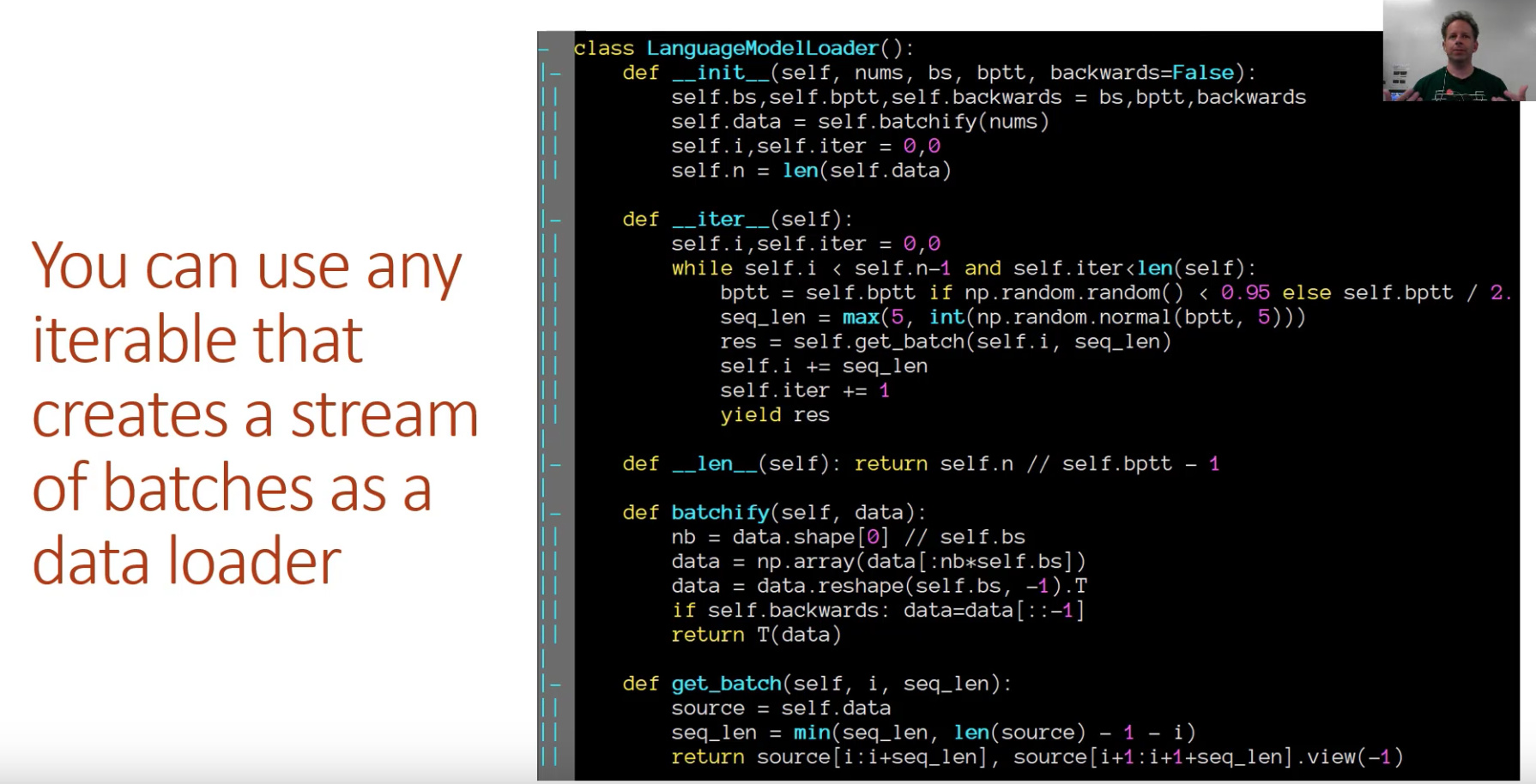
Key Notes:
- Batch size is not the count of things in a batch. In this context, batch_size is more batch_ct
- Randomness-> size instead of order - if we grab 70 at a time, and do a new epoch, the data will be exactly the same, and all the batches will be identical. In images we would shuffle, but that doesn’t work in the language model, because it is trying to learn the sentence. So if order can’t change, let’s randomly change the sequence length
class LanguageModelLoader():
"""Returns tuples of mini-batches."""
def __init__(self, nums, bs, bptt, backwards=False):
# assign values
self.bs,self.bptt,self.backwards = bs,bptt,backwards
# batchify the numbers. Based on the batchsize
# subdivide the data. Note: batchsize 64
# 640,000 would be broken into 64 x 10,000
self.data = self.batchify(nums)
# initialize other values
self.i,self.iter = 0,0
self.n = len(self.data)
def __iter__(self):
""" Iterator implementation"""
# start from zero
self.i,self.iter = 0,0
# will continually pull data out
while self.i < self.n-1 and self.iter<len(self):
if self.i == 0:
seq_len = self.bptt + 5 * 5
else:
bptt = self.bptt if np.random.random() < 0.95 else self.bptt / 2.
seq_len = max(5, int(np.random.normal(bptt, 5)))
res = self.get_batch(self.i, seq_len)
self.i += seq_len
self.iter += 1
# yields the value
yield res
def __len__(self): return self.n // self.bptt - 1
def batchify(self, data):
"""splits the data into batch_size counts of sets"""
nb = data.shape[0] // self.bs
data = np.array(data[:nb*self.bs])
data = data.reshape(self.bs, -1).T
if self.backwards: data=data[::-1]
# returns the transpose
# have batch_size number of columns
return T(data)
def get_batch(self, i, seq_len):
source = self.data
seq_len = min(seq_len, len(source) - 1 - i)
return source[i:i+seq_len], source[i+1:i+1+seq_len].view(-1)
ModelData
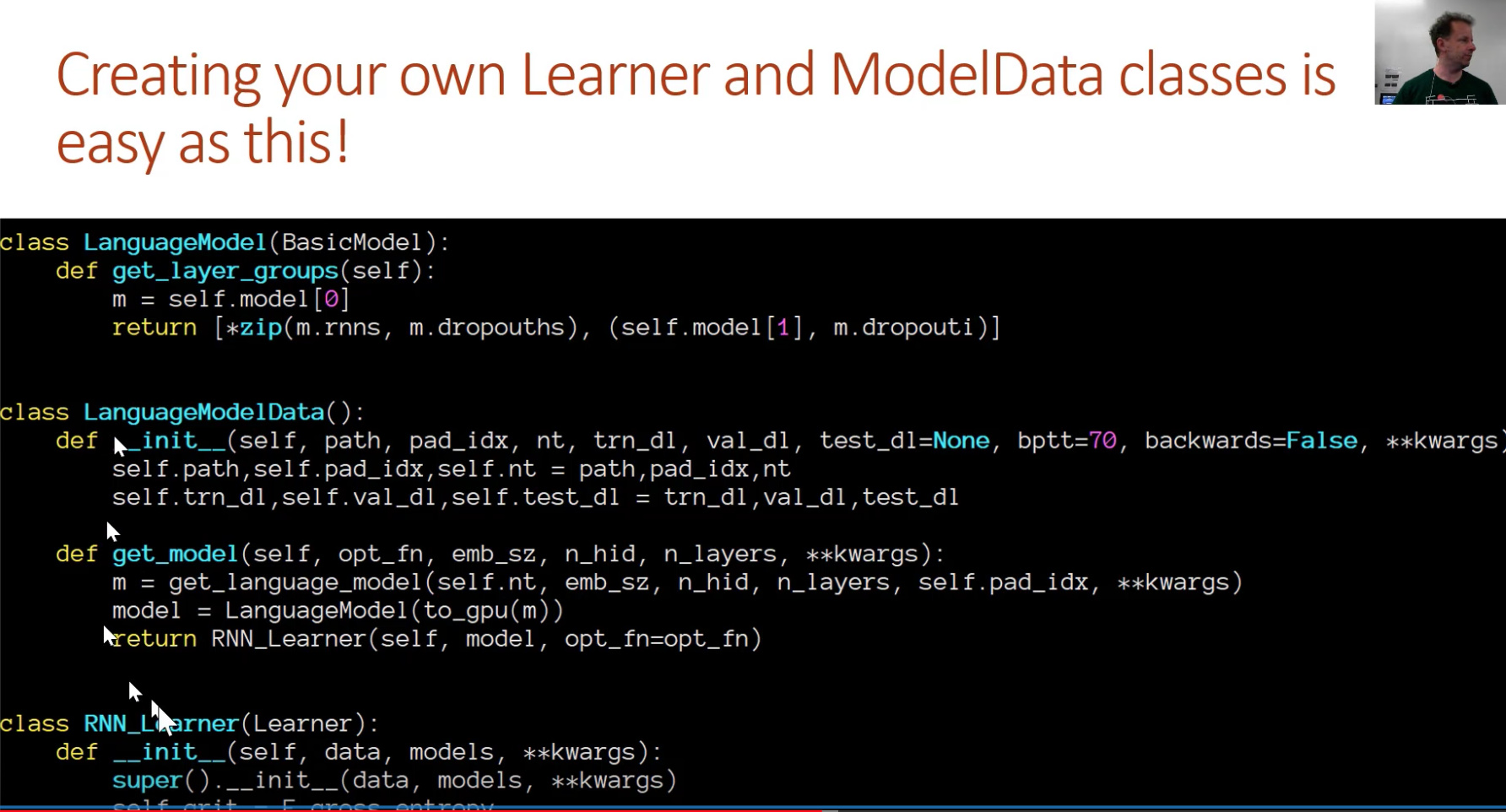
class LanguageModelData():
"""
- a training data loader
- a validation data loader
- a test loader
- a saving path
- model parameteres
"""
def __init__(self, path, pad_idx, nt, trn_dl, val_dl, test_dl=None, bptt=70, backwards=False, **kwargs):
self.path,self.pad_idx,self.nt = path,pad_idx,nt
self.trn_dl,self.val_dl,self.test_dl = trn_dl,val_dl,test_dl
def get_model(self, opt_fn, emb_sz, n_hid, n_layers, **kwargs):
m = get_language_model(self.nt, emb_sz, n_hid, n_layers, self.pad_idx, **kwargs)
model = LanguageModel(to_gpu(m))
return RNN_Learner(self, model, opt_fn=opt_fn)
Our Language Model extends the basic model
We are overriding one method that returns a list of all your layer groups.
class LanguageModel(BasicModel):
def get_layer_groups(self):
m = self.model[0]
return [*zip(m.rnns, m.dropouths), (self.model[1], m.dropouti)]
Extend the learner class, set default to cross entropy
class RNN_Learner(Learner):
def __init__(self, data, models, **kwargs):
super().__init__(data, models, **kwargs)
self.crit = F.cross_entropy
def save_encoder(self, name): save_model(self.model[0], self.get_model_path(name))
def load_encoder(self, name): load_model(self.model[0], self.get_model_path(name))
Review of the RNN Encoder
- Embedding input layer
- 1 x LSTM layer per layer asked for
nl - The rest are places to put dropout
Forward:
- Call the Embedding Layer
- Add some drop out
- Call RNN layer
- Append to outputs
- drop out
import torch.nn as nn
class RNN_Encoder(nn.Module):
"""A custom RNN encoder network that uses
- an embedding matrix to encode input,
- a stack of LSTM layers to drive the network, and
- variational dropouts in the embedding and LSTM layers
The architecture for this network was inspired by the work done in
"Regularizing and Optimizing LSTM Language Models".
(https://arxiv.org/pdf/1708.02182.pdf)
"""
initrange=0.1
def __init__(self, ntoken, emb_sz, nhid, nlayers, pad_token, bidir=False,
dropouth=0.3, dropouti=0.65, dropoute=0.1, wdrop=0.5):
""" Default constructor for the RNN_Encoder class
Args:
bs (int): batch size of input data
ntoken (int): number of vocabulary (or tokens) in the source dataset
emb_sz (int): the embedding size to use to encode each token
nhid (int): number of hidden activation per LSTM layer
nlayers (int): number of LSTM layers to use in the architecture
pad_token (int): the int value used for padding text.
dropouth (float): dropout to apply to the activations going from one LSTM layer to another
dropouti (float): dropout to apply to the input layer.
dropoute (float): dropout to apply to the embedding layer.
wdrop (float): dropout used for a LSTM's internal (or hidden) recurrent weights.
Returns:
None
"""
super().__init__()
self.ndir = 2 if bidir else 1
self.bs = 1
self.encoder = nn.Embedding(ntoken, emb_sz, padding_idx=pad_token)
self.encoder_with_dropout = EmbeddingDropout(self.encoder)
self.rnns = [nn.LSTM(emb_sz if l == 0 else nhid, (nhid if l != nlayers - 1 else emb_sz)//self.ndir,
1, bidirectional=bidir, dropout=dropouth) for l in range(nlayers)]
if wdrop: self.rnns = [WeightDrop(rnn, wdrop) for rnn in self.rnns]
self.rnns = torch.nn.ModuleList(self.rnns)
self.encoder.weight.data.uniform_(-self.initrange, self.initrange)
self.emb_sz,self.nhid,self.nlayers,self.dropoute = emb_sz,nhid,nlayers,dropoute
self.dropouti = LockedDropout(dropouti)
self.dropouths = nn.ModuleList([LockedDropout(dropouth) for l in range(nlayers)])
def forward(self, input):
""" Invoked during the forward propagation of the RNN_Encoder module.
Args:
input (Tensor): input of shape (sentence length x batch_size)
Returns:
raw_outputs (tuple(list (Tensor), list(Tensor)): list of tensors evaluated from each RNN layer without using
dropouth, list of tensors evaluated from each RNN layer using dropouth,
"""
sl,bs = input.size()
if bs!=self.bs:
self.bs=bs
self.reset()
emb = self.encoder_with_dropout(input, dropout=self.dropoute if self.training else 0)
emb = self.dropouti(emb)
raw_output = emb
new_hidden,raw_outputs,outputs = [],[],[]
for l, (rnn,drop) in enumerate(zip(self.rnns, self.dropouths)):
current_input = raw_output
with warnings.catch_warnings():
warnings.simplefilter("ignore")
raw_output, new_h = rnn(raw_output, self.hidden[l])
new_hidden.append(new_h)
raw_outputs.append(raw_output)
if l != self.nlayers - 1: raw_output = drop(raw_output)
outputs.append(raw_output)
self.hidden = repackage_var(new_hidden)
return raw_outputs, outputs
def one_hidden(self, l):
nh = (self.nhid if l != self.nlayers - 1 else self.emb_sz)//self.ndir
return Variable(self.weights.new(self.ndir, self.bs, nh).zero_(), volatile=not self.training)
def reset(self):
self.weights = next(self.parameters()).data
self.hidden = [(self.one_hidden(l), self.one_hidden(l)) for l in range(self.nlayers)]
Choosing Dropout
If you have less data for your language model, you will need more dropout. If you have more data, you will need less dropout. Otherwise the following dropout numbers were selected by experimentation:
drops = np.array([0.25, 0.1, 0.2, 0.02, 0.15])*0.7
Note on : 0.7 if you are overfitting, increase the number, if you are underfitting, decrease this number
Normally we look at cross-entropy loss. But comparing CE Loss, if you are right, you should be very confident. Accuracy only cares if the answer was right or wrong, often times is more stable to track.
Back to the Language Model
wd=1e-7
bptt=70
bs=52
opt_fn = partial(optim.Adam, betas=(0.8, 0.99))
trn_dl = LanguageModelLoader(np.concatenate(trn_lm), bs, bptt)
val_dl = LanguageModelLoader(np.concatenate(val_lm), bs, bptt)
md = LanguageModelData(PATH, 1, vs, trn_dl, val_dl, bs=bs, bptt=bptt)
drops = np.array([0.25, 0.1, 0.2, 0.02, 0.15])*0.7
learner= md.get_model(opt_fn, em_sz, nh, nl,
dropouti=drops[0], dropout=drops[1], wdrop=drops[2], dropoute=drops[3], dropouth=drops[4])
learner.metrics = [accuracy]
learner.unfreeze()
note to reader - this block takes a long time to run (single epoch) - 30mins/epoch on 8 core 32 GB
import time
learner.model.load_state_dict(wgts)
# fit a single cycle
lr=1e-3
lrs = lr
start = time.time()
learner.fit(lrs/2, 1, wds=wd, use_clr=(32,2), cycle_len=1)
print("time to train 1 epoch,", time.time()-start)
learner.save('lm_last_ft')
learner.load('lm_last_ft')
learner.unfreeze()
HBox(children=(IntProgress(value=0, description='Epoch', max=1), HTML(value='')))
epoch trn_loss val_loss accuracy
0 4.354009 4.18011 0.285487
time to train 1 epoch, 1856.5503034591675
this will take a while to run - 15 epochs! make sure you have the time / computing resources
# search for a learning rate, then run for 15 epoches
learner.lr_find(start_lr=lrs/10, end_lr=lrs*10, linear=True)
learner.sched.plot()
start = time.time()
learner.fit(lrs, 1, wds=wd, use_clr=(20,10), cycle_len=15)
print("Time to train,", time.time() - start)
After fitting the model we save it
We save the trained model weights and separately save the encoder part of the LM model as well. This will serve as our backbone in the classification task model.
# saves the model
learner.save('lm1')
# saves just the RNN encoder (rnn_enc)
learner.save_encoder('lm1_enc')
learner.sched.plot_loss()
From FASTAI reference notebook - Results of the 15 epoches
epoch trn_loss val_loss accuracy
0 4.332359 4.120674 0.289563
1 4.247177 4.067932 0.294281
2 4.175848 4.027153 0.298062
3 4.140306 4.001291 0.300798
4 4.112395 3.98392 0.302663
5 4.078948 3.971053 0.304059
6 4.06956 3.958152 0.305356
7 4.025542 3.951509 0.306309
8 4.019778 3.94065 0.30756
9 4.027846 3.931385 0.308232
10 3.98106 3.928427 0.309011
11 3.97106 3.920667 0.30989
12 3.941096 3.917029 0.310515
13 3.924818 3.91302 0.311015
14 3.923296 3.908476 0.311586
Create the Classifier Tokens
The classifier model is basically a linear layer custom head on top of the LM backbone. Setting up the classifier data is similar to the LM data setup except that we cannot use the unsup movie reviews this time.
# read in the data again
df_trn = pd.read_csv(CLAS_PATH/'train.csv', header=None, chunksize=chunksize)
df_val = pd.read_csv(CLAS_PATH/'test.csv', header=None, chunksize=chunksize)
# get the tokens
tok_trn, trn_labels = get_all(df_trn, 1)
tok_val, val_labels = get_all(df_val, 1)
(CLAS_PATH/'tmp').mkdir(exist_ok=True)
np.save(CLAS_PATH/'tmp'/'tok_trn.npy', tok_trn)
np.save(CLAS_PATH/'tmp'/'tok_val.npy', tok_val)
np.save(CLAS_PATH/'tmp'/'trn_labels.npy', trn_labels)
np.save(CLAS_PATH/'tmp'/'val_labels.npy', val_labels)
tok_trn = np.load(CLAS_PATH/'tmp'/'tok_trn.npy')
tok_val = np.load(CLAS_PATH/'tmp'/'tok_val.npy')
# We load the integer to vocab that we saved before
itos = pickle.load((LM_PATH/'tmp'/'itos.pkl').open('rb'))
stoi = collections.defaultdict(lambda:0, {v:k for k,v in enumerate(itos)})
# create all matricies with indices
trn_clas = np.array([[stoi[o] for o in p] for p in tok_trn])
val_clas = np.array([[stoi[o] for o in p] for p in tok_val])
# then save the matricies
np.save(CLAS_PATH/'tmp'/'trn_ids.npy', trn_clas)
np.save(CLAS_PATH/'tmp'/'val_ids.npy', val_clas)
Classifier
Now we can create our final model, a classifier which is really a custom linear head over our trained IMDB backbone. The steps to create the classifier model are similar to the ones for the LM.
# we load our numpy arrays with indexes (representing vocab)
trn_clas = np.load(CLAS_PATH/'tmp'/'trn_ids.npy')
val_clas = np.load(CLAS_PATH/'tmp'/'val_ids.npy')
# we load our labels
trn_labels = np.squeeze(np.load(CLAS_PATH/'tmp'/'trn_labels.npy'))
val_labels = np.squeeze(np.load(CLAS_PATH/'tmp'/'val_labels.npy'))
# set up our model parameters
bptt,em_sz,nh,nl = 70,400,1150,3
vs = len(itos)
# select our optimizer
# also pick a batch size as big as you can that doesn't run out of memory
opt_fn = partial(optim.Adam, betas=(0.8, 0.99))
bs = 48
min_lbl = trn_labels.min()
trn_labels -= min_lbl
val_labels -= min_lbl
c=int(trn_labels.max())+1
In the classifier, unlike LM, we need to read a movie review at a time and learn to predict the it’s sentiment as pos/neg. We do not deal with equal bptt size batches, so we have to pad the sequences to the same length in each batch. To create batches of similar sized movie reviews, we use a sortish sampler method invented by @Smerity and @jekbradbury
The sortishSampler cuts down the overall number of padding tokens the classifier ends up seeing.
Note: If documents are different lengths, they should be padded to be the same size. Luckily fastai does this automatically

Process Optimizing Note: Put the short documents first (with some randomness)
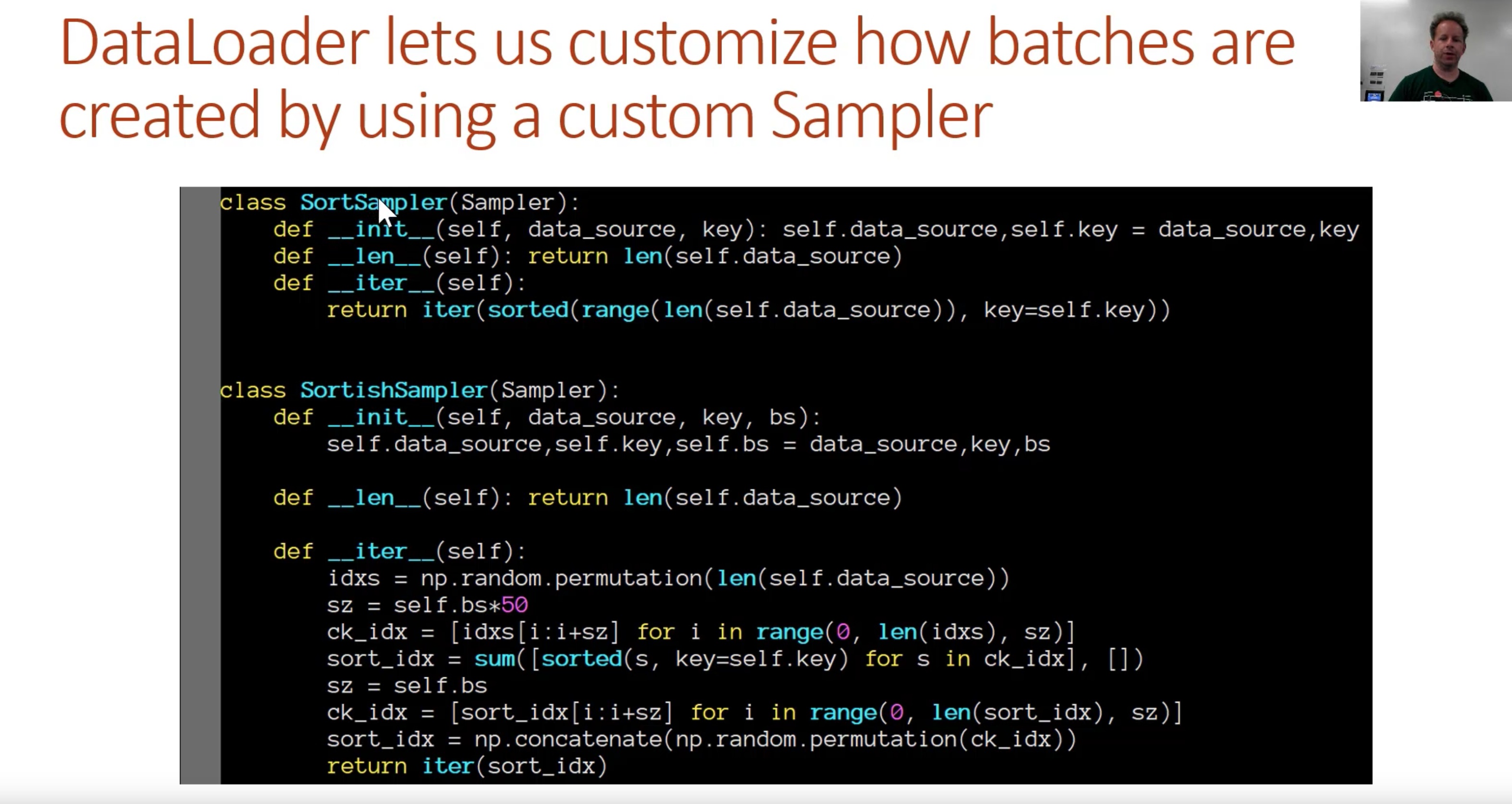
# create basic text datasets
trn_ds = TextDataset(trn_clas, trn_labels)
val_ds = TextDataset(val_clas, val_labels)
# sort the docs based on size.
# validation will be explicitly short -> long
# training, which sorts loosely
trn_samp = SortishSampler(trn_clas, key=lambda x: len(trn_clas[x]), bs=bs//2)
val_samp = SortSampler(val_clas, key=lambda x: len(val_clas[x]))
# then we create our dataloaders as before but with a [sampler] parameter
trn_dl = DataLoader(trn_ds, bs//2, transpose=True, num_workers=1, pad_idx=1, sampler=trn_samp)
val_dl = DataLoader(val_ds, bs, transpose=True, num_workers=1, pad_idx=1, sampler=val_samp)
md = ModelData(PATH, trn_dl, val_dl)
Load our Pretrained Model, and train the last Layer
We will pass hidden layer details
layers=[em_sz*3, 50, c]
-
em_sz*3- inputsize -
50- output of first layer -
c- output of the 2nd layer
Why x3? - Concat pooling
We take the average pooling over the sequence, the max pooling, and the final pooling and concatenating them all together
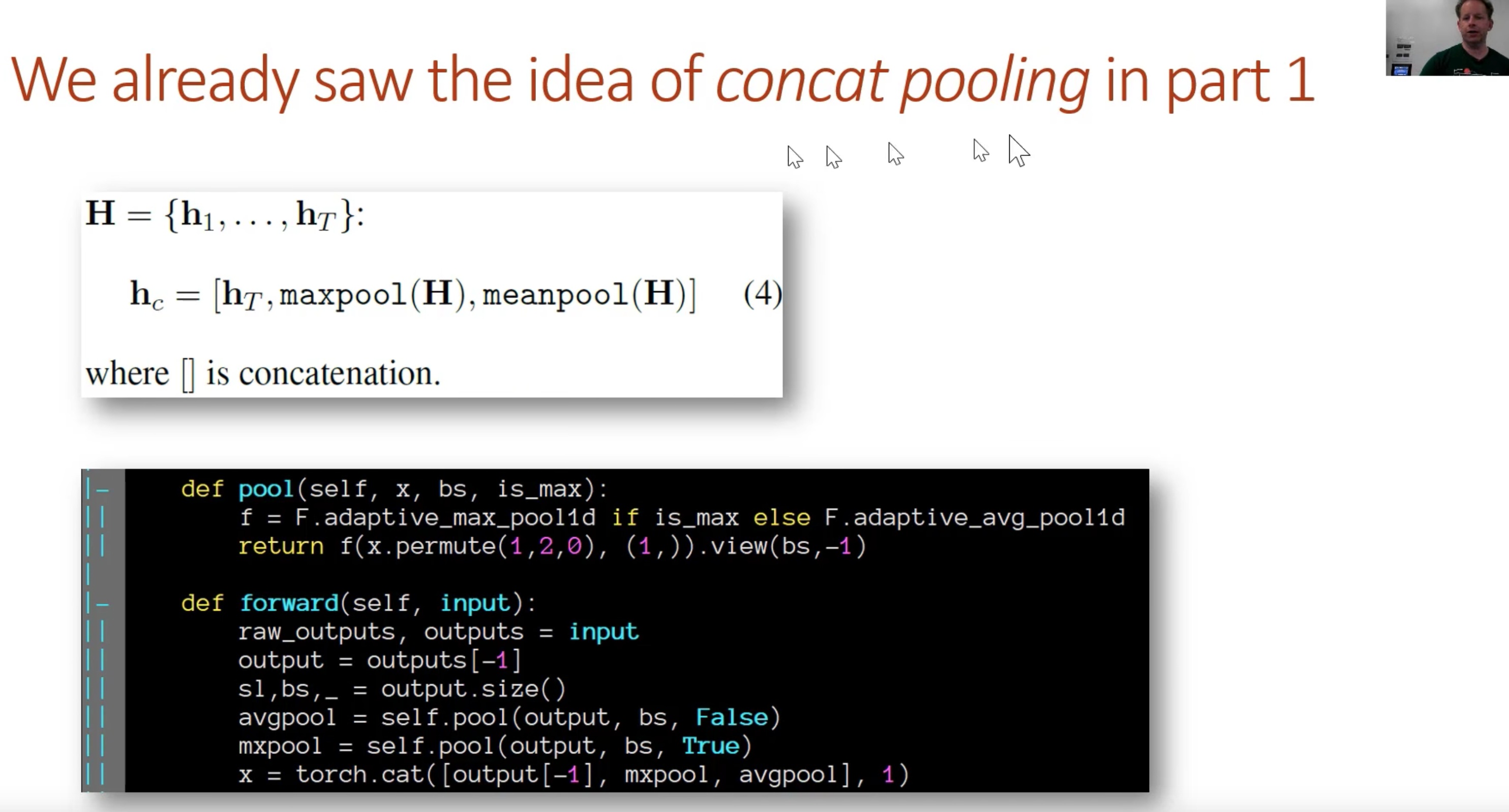
pass in drop out details
drops=[dps[4], 0.1]
pass the AWD dropout parameters:
dropouti=dps[0], wdrop=dps[1], dropoute=dps[2], dropouth=dps[3])
# setup our dropout rates
dps = np.array([0.4,0.5,0.05,0.3,0.4])*0.5
m = get_rnn_classifer(bptt, 20*70, c, vs, emb_sz=em_sz, n_hid=nh, n_layers=nl, pad_token=1,
layers=[em_sz*3, 50, c], drops=[dps[4], 0.1],
dropouti=dps[0], wdrop=dps[1], dropoute=dps[2], dropouth=dps[3])
opt_fn = partial(optim.Adam, betas=(0.7, 0.99))
# define our RNN learner
learn = RNN_Learner(md, TextModel(to_gpu(m)), opt_fn=opt_fn)
learn.reg_fn = partial(seq2seq_reg, alpha=2, beta=1)
learn.clip=25.
learn.metrics = [accuracy]
# set our learning rate
# we will use discriminative learning rates for different layers
lr=3e-3
lrm = 2.6
lrs = np.array([lr/(lrm**4), lr/(lrm**3), lr/(lrm**2), lr/lrm, lr])
# Now we load our language model from before
# but freeze everything except the last layer
lrs=np.array([1e-4,1e-4,1e-4,1e-3,1e-2])
wd = 1e-7
wd = 0
learn.load_encoder('lm2_enc')
learn.freeze_to(-1)
# find the optimal learning rate
learn.lr_find(lrs/1000)
learn.sched.plot()
Train the last Layer
A Jupyter Widget
epoch trn_loss val_loss accuracy
0 0.365457 0.185553 0.928719
learn.fit(lrs, 1, wds=wd, cycle_len=1, use_clr=(8,3))
learn.save('clas_0')
What if we freeze everything except the last two layers?
epoch trn_loss val_loss accuracy
0 0.340473 0.17319 0.933125
learn.load('clas_0')
learn.freeze_to(-2)
learn.fit(lrs, 1, wds=wd, cycle_len=1, use_clr=(8,3))
learn.save('clas_1')
Now lets try and train the whole model
Note that the state of the art is 0.941, which is beaten in 3-4 epoches
epoch trn_loss val_loss accuracy
0 0.337347 0.186812 0.930782
1 0.284065 0.318038 0.932062
2 0.246721 0.156018 0.941747
3 0.252745 0.157223 0.944106
4 0.24023 0.159444 0.945393
5 0.210046 0.202856 0.942858
6 0.212139 0.149009 0.943746
7 0.21163 0.186739 0.946553
8 0.186233 0.1508 0.945218
9 0.176225 0.150472 0.947985
10 0.198024 0.146215 0.948345
11 0.20324 0.189206 0.948145
12 0.165159 0.151402 0.947745
13 0.165997 0.146615 0.947905
learn.load('clas_1')
learn.unfreeze()
learn.fit(lrs, 1, wds=wd, cycle_len=14, use_clr=(32,10))
Fun thing to try: do the same thing, but reverse the document
When you combine the forward and backward models and average the results, we get a 95% accuracy!
The previous state of the art result was 94.1% accuracy (5.9% error). With bidir we get 95.4% accuracy (4.6% error).
Check out the paper

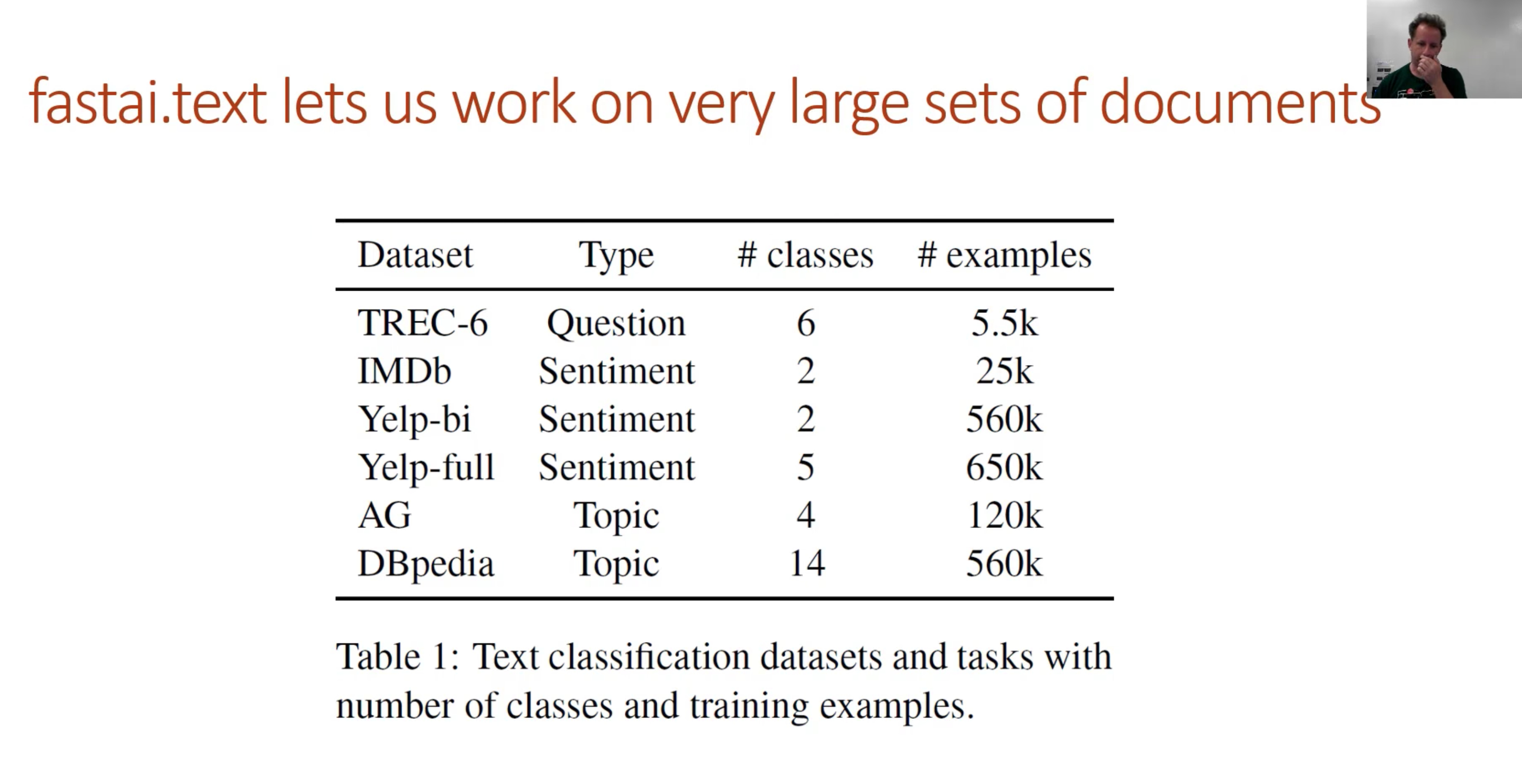
fastai.text performance on text sets
discriminative learning rates - renamed from differential learning rates

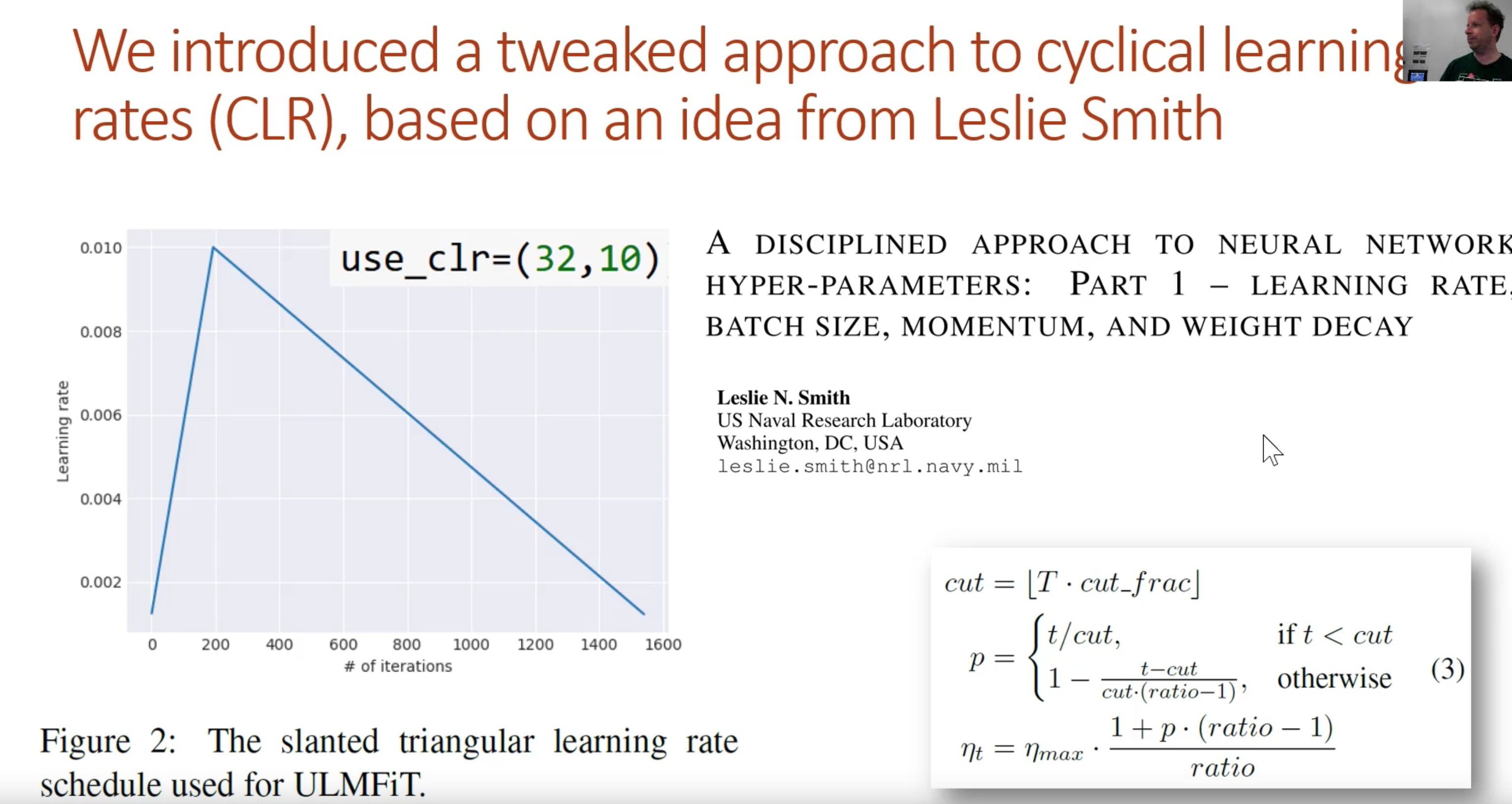
gradual unfreezing learning rates - unfreezing a layer at a time

Tweaked approach to cyclical learning rates CLR - based on idea from Leslie smith
Only do 1 cycle that goes up quickly and goes down slower afterwards. Currently implemented in fastai. First number is ratio of highest learning rate to the lowest ratio rate. 32. Second number is the ratio between teh first peak and the last peak. First epoch to be upward, and 9 down, = 10
BPTT - Normal RNN vs. MultiBatch RNN:
Key difference is that hte normal RNN encoder. We can BPTT chunk at a time, and predice the next word. But for the classifier, we need to do the entire doc, or the entire movie review. The entire review could be 2000 words, and we can’t fit all in memory.
Sends back only as many activations as we have decided to keep. If your max is 1000, but your doc is 2000. It will go through and only keep the most recent 1000 activations.

Results vs. customized algorithms
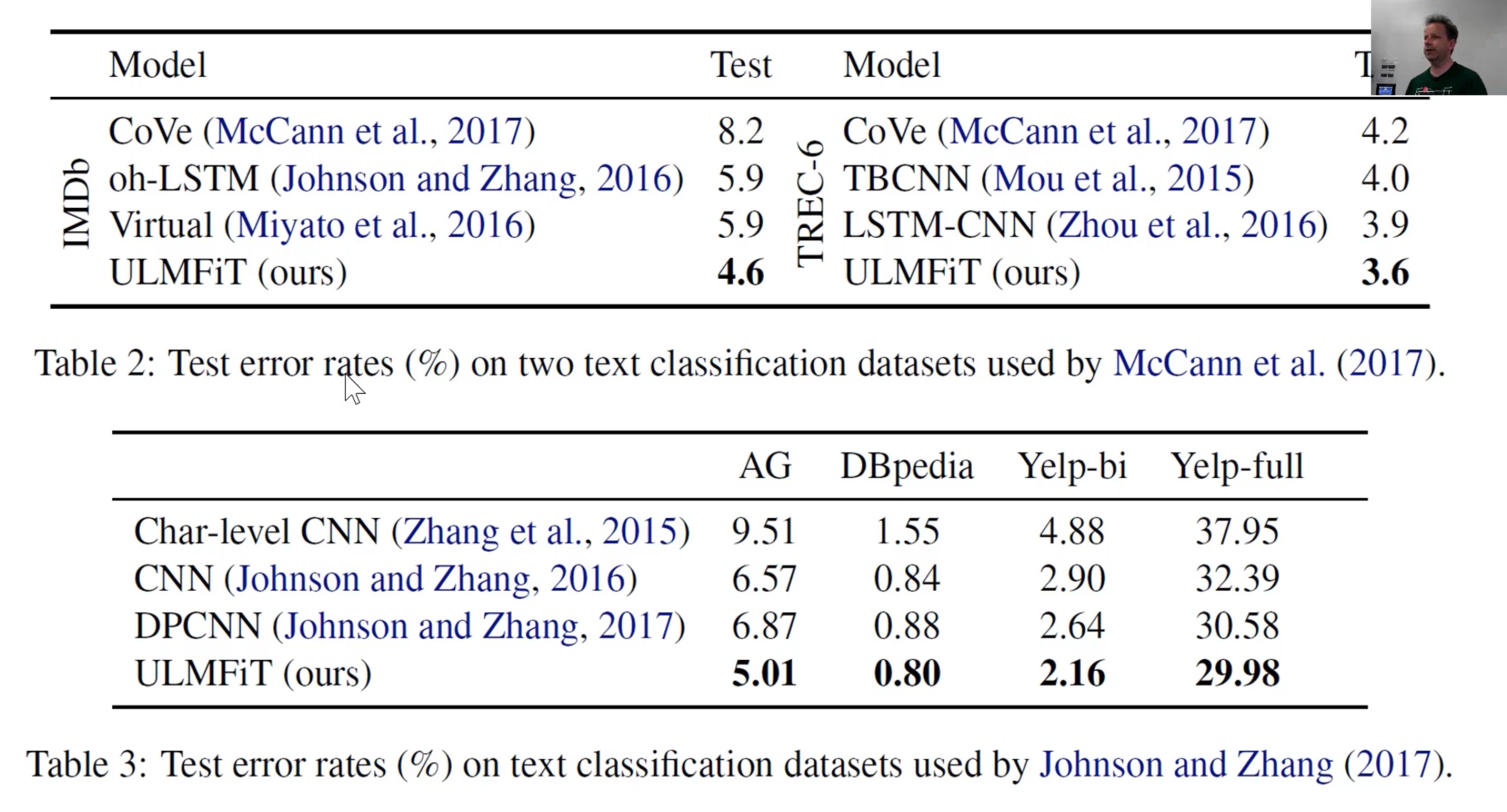
how do the different techniques affect the score?
- What happens with different dataset sizes
- What happens if different techniques are turned on and off?

