It’s not the same thing. By downsampling the signal, you lose information about frequencies above half of the new sample rate. The hop_length has nothing to do with frequencies but rather a way of controlling the time-resolution of the spectrogram: With a small hop_length you compute the FFT of windows that overlap a lot, with a larger hop_length the windows overlap less and each time frame of the spectrogram is more independent of its neighbours.
I can see how it can be confusing though, since decreasing the sample rate and increasing the hop_length both reduces the number of time frames in the resulting spectrogram.
Also: Very cool thread! I’m new to Pytorch and fastai but I have been working on deep learning for audio for a while.
Thanks for the notebooks, they have really helped a ton and I have been using them constantly as a reference
However, I’m still unsure about one thing: what does ref do in power_to_db and amplitude_to_db? I tried reading the docs but I’m not sure exactly what it does. I’m also not sure what is the best value to put there because I have seen many leave it as the default (1.0), some use np.min, and some use np.max (this actually seems to be the most common). Additionally, I’ve seen many take the absolute value of the signal when using this function, what is the purpose of that?
Decibels is a relative scale so values must be relative to some reference value, ref in this case. So after conversion a value equal to ref will be 0dB. The default of 1.0 would be based on the common case where values are floats in the range (-1,1), which is commonly used to avoid different values depending on input file bit-depth (i.e. 8-bit files have a range of 0 to 255, or -128 to 127 if signed, while 16 bit files have a range of 0 to 65536, or -32768 to 32767). This will give decibel values in a range of around (-70, 0), depending on signal resolution. That’s prior to processing which can give higher values, values aren’t actually limited to the range. np.max would use the actual maximum value of your signal as the reference giving a similar range of (-70,0), while np.min would give a range of around (0, 70). Don’t think it matters especially much which you use. In fact I don’t think any are especially well suited to neural nets as none are near the mean of 0 and SD of 1 that is ideal. Though subsequent normalisation (i.e. substract mean, divide by SD) should work with any and I think should produce much the same normalised values from them all. So it doesn’t really matter and the primary purpose is likely just to produce values that align with common ranges used for audio (going back to common conventions on analog equipment).
@MadeUpMasters has made a fix to do this I believe, should be present in the next release. But thanks for the colour map suggestion and feel free to make a PR yourself
Looking for some feedback on bringing the fastai audio application back into the main fastai library. If you have thoughts on this, really would like to get a conversation started over in the fastai dev section of the forums!
Hey, you mentioned in the dev thread you’re interested in implementing Baidu’s DeepSpeech in fastai. I’d love to hear more about your work and why you’re interested in Speech Recognition. I’m about to start on something quite similar, building a phoneme based speech recognition system without a language model in order to help non-native English speakers improve their pronunciation.
Hey fellow learners
I’m trying to make an audio editing learner for some project, using the GAN architecture from lesson 7.
I’ve already used your fantastic fastai_audio library to train a critic (90% identification in a minute of learning!).
But, I’m having trouble creating a generator learner, with a unet_learner like in lesson 7 and a custom AudioAudioList instead of ImageImageList.
When running fit_one_cycle I get the following error: RuntimeError: The size of tensor a (3078144) must match the size of tensor b (1280000) at non-singleton dimension 0
This error occurred during loss function calculation (MSE flat).
I think that this error means that fastai doesn’t understand the shape of my LabelClass (AudioItemList), and therefore the generated model has the wrong output size.
Any ideas on how to fix that? Anyone else working on generators/GANs for audio?
That’s really amazing news. We haven’t tried to do anything like that with the library so would be great to see what your doing and to help you with your problem. Could you share notebook as a gist?
Yes the telegram is still active. PM @MadeUpMasters with your telegram deets
Hey guys, Jermey talked about doing work with audio, its in the git repo but theres nothing about it in the course that I noticed. Did we skip it or am I missing something ?
I think the plan was changed during the course and some things like audio will instead be provided as future lessons, as noted at the very bottom of the course page.
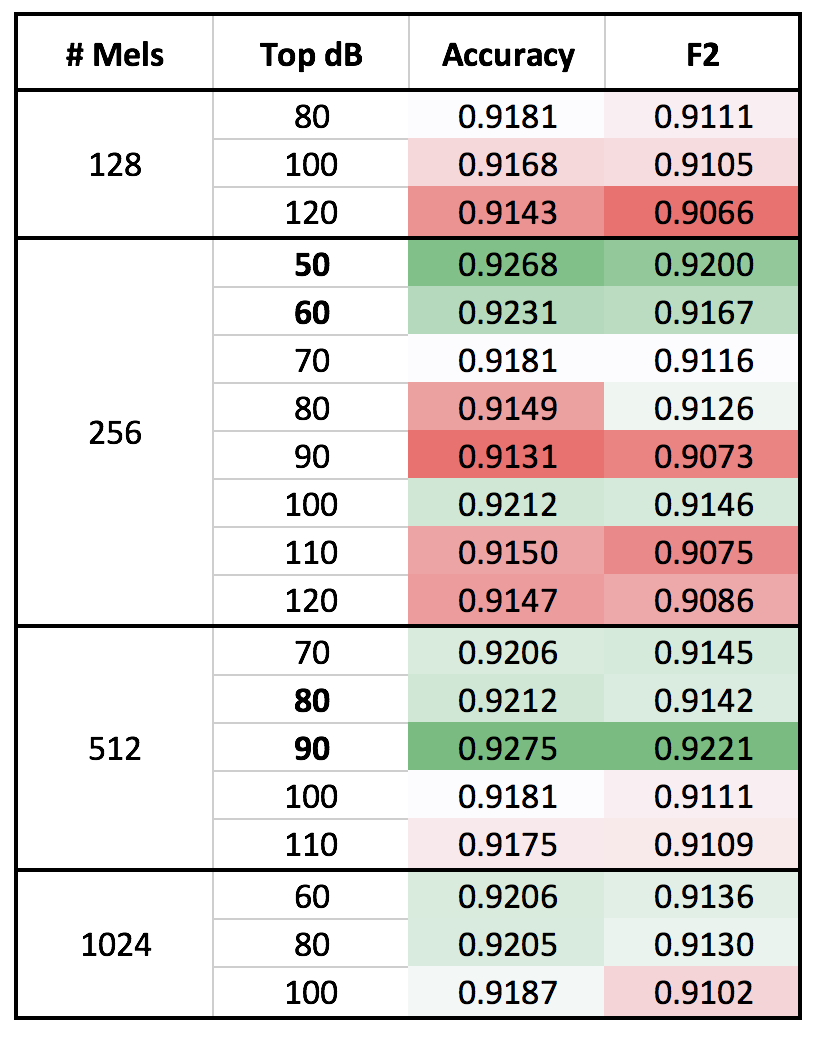
I’m currently working with a music dataset and did a little grid search on spectrogram params and figured I’d share my learnings here in case it is helpful to anyone
Dataset: 10k songs, 3 spectrograms per song (12 sec each), 10 genres (~1k songs each, +/- 50 songs per genre)
Training: ResNet 34, Incremental training on 112px, 224px, 448px
Results: As I somewhat expected, the spectrograms with the higher frequency resolution receive stronger performance. However, it was pretty surprising to see such strong performance from the 256 mel spectros with a Top dB of 50/60. It could be because I am trying to identify genres and something so broad benefits from noise reduction (both sound and data), but I’m not entirely sure.
Other Findings: I also tried using a ResNet 50 for a few of the best performing params, but saw no significant increase in performance (and a 75% increase in training time). Additionally, I tried the same with 896px spectrograms, but that also did not increase the performance (with 25% increase in spectro generation time, 100% increase in data transfer time, and 200% increase in training time… so definitely not worth it ).
Overall: I’m very happy with performance, if I use a “voting evaluation” for each of the songs (i.e. since there are three spectrograms per song, let the final prediction be what the majority of spectros decide), then I get a 98.8% Accuracy which could be above human performance. I’m eventually going to do something a little more complicated than genre identification, but this definitely inspires enough confidence to continue.
Hey, I was also working on an audio generator, I also made an AudioAudioList, which just added ways to visualize the audio and the spectrogram. The problem I found was my lack of knowledge in audio, but I did come across a similar problem as you. One of the things I had to do was make sure that the sampling rates and lengths of the audios where all the same, since I was only using a slightly modified unet_learner and not a rnn structure.
Even then I had one pesty audio in my data set that for some reason didn’t want to transform into the same shape, I ended up just taking it out of the data set and never figured out how to fix it. Check to see where this error occurs, and that should help you figure out how to fix it, or if it’s worth fixing.

 ).
).