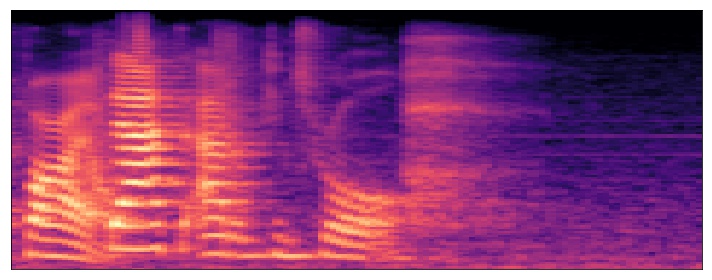
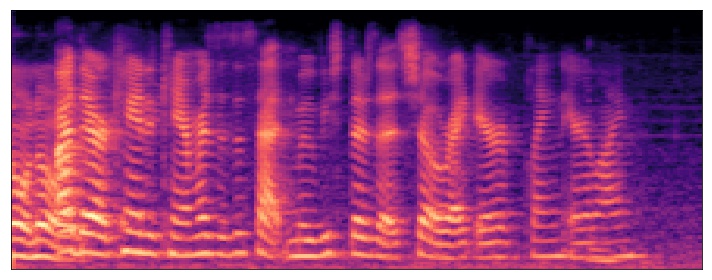
Yeah, I considered that, could be a reasonable addition (and perhaps primary method for spectrograms, obviously not helpful when using a time domain network).
Think you’d need to do some performance testing to know if it was better, and how much. It’d mean you’d be using less efficient FFT window lengths on longer chunks for various of the rates, i.e. if you were ‘resampling’ to 16000 via that method with nfft=1024 at a rate of 16000 it would mean a 22050 sample would need to be STFT’d with nfft=1411 (I think, quick calc). Whether the repeated FFTs of less efficient and longer windows would outweigh the advantage of just resampling in the first place, in particular for smaller hops where it will matter more, I don’t know. Given the FFT method is the most efficient way to resample on GPU i’d suspect it would probably be a net performance gain (except maybe at very small hop lengths), but it is a somewhat complex performance tradeoff.
Then there’s the question of whether the performance gain is worth the extra complexity. It also doesn’t just affect the spectrogram creation, you’d have to adapt things like the mel filterbank for the differing numbers of FFT bins.
Edit: Oh, and when thinking it through I realised that this only really works with mel filtering. Otherwise you are just left with different FFT resolutions for each sample rate and need to basically resample the FFT frequency data which seems unlikely to end up being a worthwhile method. With mel filtering (or similar frequency re-binning) you can just adapt the mel filterbank to each nfft.
Edit2: Oops, that’s wrong, you don’t need mel filtering, given appropriate scaling of nfft you just need to select the first x bins where x is the nfft at your standardised rate. So in the above example, the first 1024 bins of the 1411 bins from the 22050 clip should be identical to the ones from 16000 clip. So just the performance issue of whether the larger number (due to overlap with hop) of less efficient lengths are better than one longer (perhaps also inefficient) FFT to resample in the first place.
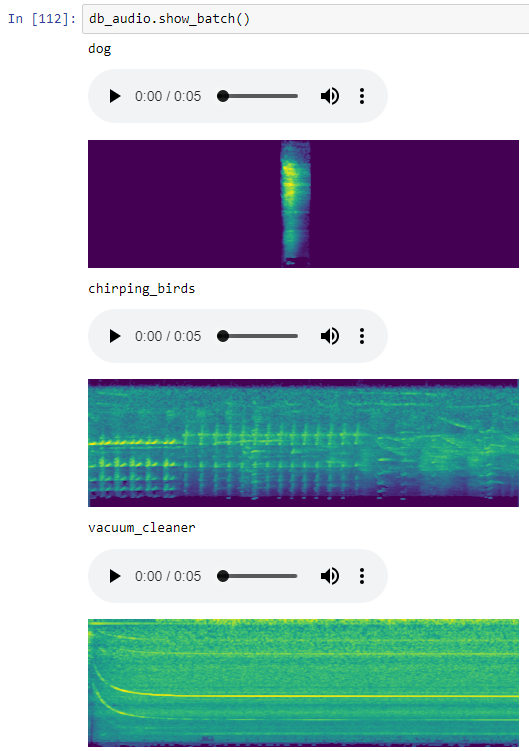
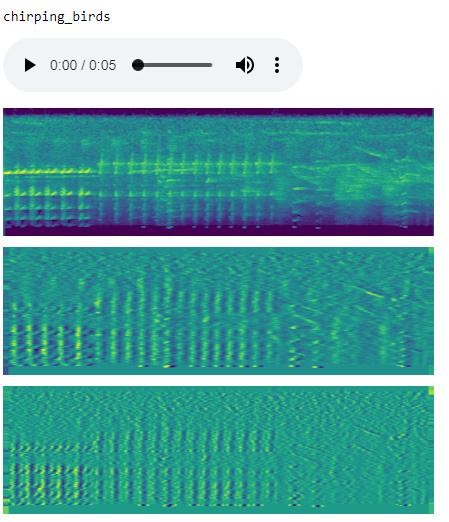

 ) so if you find yourself implementing something for audio AI and think it would be a cool feature for the library, or if you think the API sucks and want to try a refactor, go ahead.
) so if you find yourself implementing something for audio AI and think it would be a cool feature for the library, or if you think the API sucks and want to try a refactor, go ahead.